This is the multi-page printable view of this section. Click here to print.
Cluster management
- 1: Cluster management overview
- 2: Scale cluster
- 2.1: Scale Bare Metal cluster
- 2.2: Scale CloudStack cluster
- 2.3: Scale Nutanix cluster
- 2.4: Scale vSphere cluster
- 3: Upgrade cluster
- 4: Etcd Backup and Restore
- 5: Verify cluster
- 6: Add cluster integrations
- 7: Reboot nodes
- 8: Connect cluster to console
- 9: License cluster
- 10: Multus CNI plugin configuration
- 11: Authenticate cluster with AWS IAM Authenticator
- 12: Manage cluster with GitOps
- 13: Manage cluster with Terraform
- 14: Delete cluster
1 - Cluster management overview
The content in this page will describe the tools and interfaces available to an administrator after an EKS Anywhere cluster is up and running. It will also describe which administrative actions done:
- Directly in Kubernetes itself (such as adding nodes with
kubectl) - Through the EKS Anywhere API (such as deleting a cluster with
eksctl). - Through tools which interface with the Kubernetes API (such as managing a cluster with
terraform)
Note that direct changes to OVAs before nodes are deployed is not yet supported. However, we are working on a solution for that issue.
2 - Scale cluster
2.1 - Scale Bare Metal cluster
Scaling nodes on Bare Metal clusters
When you are horizontally scaling your Bare Metal EKS Anywhere cluster, consider the number of nodes you need for your control plane and for your data plane.
See the Kubernetes Components documentation to learn the differences between the control plane and the data plane (worker nodes).
Horizontally scaling the cluster is done by increasing the number for the control plane or worker node groups under the Cluster specification.
NOTE: If etcd is running on your control plane (the default configuration) you should scale your control plane in odd numbers (3, 5, 7…).
apiVersion: anywhere.eks.amazonaws.com/v1
kind: Cluster
metadata:
name: test-cluster
spec:
controlPlaneConfiguration:
count: 1 # increase this number to horizontally scale your control plane
...
workerNodeGroupsConfiguration:
- count: 1 # increase this number to horizontally scale your data plane
Next, you must ensure you have enough available hardware for the scale-up operation to function. Available hardware could have been fed to the cluster as extra hardware during a prior create command, or could be fed to the cluster during the scale-up process by providing the hardware CSV file to the upgrade cluster command (explained in detail below). For scale-down operation, you can skip directly to the upgrade cluster command .
To check if you have enough available hardware for scale up, you can use the kubectl command below to check if there are hardware with the selector labels corresponding to the controlplane/worker node group and without the ownerName label.
kubectl get hardware -n eksa-system --show-labels
For example, if you want to scale a worker node group with selector label type=worker-group-1, then you must have an additional hardware object in your cluster with the label type=worker-group-1 that doesn’t have the ownerName label.
In the command shown below, eksa-worker2 matches the selector label and it doesn’t have the ownerName label. Thus, it can be used to scale up worker-group-1 by 1.
kubectl get hardware -n eksa-system --show-labels
NAME STATE LABELS
eksa-controlplane type=controlplane,v1alpha1.tinkerbell.org/ownerName=abhnvp-control-plane-template-1656427179688-9rm5f,v1alpha1.tinkerbell.org/ownerNamespace=eksa-system
eksa-worker1 type=worker-group-1,v1alpha1.tinkerbell.org/ownerName=abhnvp-md-0-1656427179689-9fqnx,v1alpha1.tinkerbell.org/ownerNamespace=eksa-system
eksa-worker2 type=worker-group-1
If you don’t have any available hardware that match this requirement in the cluster, you can setup a new hardware CSV . You can feed this hardware inventory file during the upgrade cluster command .
Upgrade Cluster Command for Scale Up/Down
With Hardware CSV File
eksctl anywhere upgrade cluster -f cluster.yaml --hardware-csv <hardware.csv>
Without Hardware CSV File
eksctl anywhere upgrade cluster -f cluster.yaml
Autoscaling
EKS Anywhere supports autoscaling of worker node groups using the Kubernetes Cluster Autoscaler and as a curated package .
See here for details on how to configure your cluster spec to autoscale worker node groups for autoscaling.
2.2 - Scale CloudStack cluster
Autoscaling
EKS Anywhere supports autoscaling of worker node groups using the Kubernetes Cluster Autoscaler and as a curated package .
See here for details on how to configure your cluster spec to autoscale worker node groups for autoscaling.
2.3 - Scale Nutanix cluster
When you are scaling your Nutanix EKS Anywhere cluster, consider the number of nodes you need for your control plane and for your data plane. Each plane can be scaled horizontally (add more nodes) or vertically (provide nodes with more resources). In each case you can scale the cluster manually, semi-automatically, or automatically.
See the Kubernetes Components documentation to learn the differences between the control plane and the data plane (worker nodes).
Manual cluster scaling
Horizontally scaling the cluster is done by increasing the number for the control plane or worker node groups under the Cluster specification.
NOTE: If etcd is running on your control plane (the default configuration) you should scale your control plane in odd numbers (3, 5, 7…).
apiVersion: anywhere.eks.amazonaws.com/v1
kind: Cluster
metadata:
name: test-cluster
spec:
controlPlaneConfiguration:
count: 1 # increase this number to horizontally scale your control plane
...
workerNodeGroupsConfiguration:
- count: 1 # increase this number to horizontally scale your data plane
Vertically scaling your cluster is done by updating the machine config spec for your infrastructure provider. For a Nutanix cluster an example is
NOTE: Not all providers can be vertically scaled (e.g. bare metal)
apiVersion: anywhere.eks.amazonaws.com/v1
kind: NutanixMachineConfig
metadata:
name: test-machine
namespace: default
spec:
systemDiskSize: 50 # increase this number to make the VM disk larger
vcpuSockets: 8 # increase this number to add vCPUs to your VM
memorySize: 8192 # increase this number to add memory to your VM
Once you have made configuration updates you can apply the changes to your cluster. If you are adding or removing a node, only the terminated nodes will be affected. If you are vertically scaling your nodes, then all nodes will be replaced one at a time.
eksctl anywhere upgrade cluster -f cluster.yaml
Semi-automatic scaling
Scaling your cluster in a semi-automatic way still requires changing your cluster manifest configuration. In a semi-automatic mode you change your cluster spec and then have automation make the cluster changes.
You can do this by storing your cluster config manifest in git and then having a CI/CD system deploy your changes. Or you can use a GitOps controller to apply the changes. To read more about making changes with the integrated Flux GitOps controller you can read how to Manage a cluster with GitOps .
Autoscaling
EKS Anywhere supports autoscaling of worker node groups using the Kubernetes Cluster Autoscaler and as a curated package .
See here for details on how to configure your cluster spec to autoscale worker node groups for autoscaling.
2.4 - Scale vSphere cluster
When you are scaling your vSphere EKS Anywhere cluster, consider the number of nodes you need for your control plane and for your data plane. Each plane can be scaled horizontally (add more nodes) or vertically (provide nodes with more resources). In each case you can scale the cluster manually, semi-automatically, or automatically.
See the Kubernetes Components documentation to learn the differences between the control plane and the data plane (worker nodes).
Manual cluster scaling
Horizontally scaling the cluster is done by increasing the number for the control plane or worker node groups under the Cluster specification.
NOTE: If etcd is running on your control plane (the default configuration) you should scale your control plane in odd numbers (3, 5, 7…).
apiVersion: anywhere.eks.amazonaws.com/v1
kind: Cluster
metadata:
name: test-cluster
spec:
controlPlaneConfiguration:
count: 1 # increase this number to horizontally scale your control plane
...
workerNodeGroupsConfiguration:
- count: 1 # increase this number to horizontally scale your data plane
Vertically scaling your cluster is done by updating the machine config spec for your infrastructure provider. For a vSphere cluster an example is
NOTE: Not all providers can be vertically scaled (e.g. bare metal)
apiVersion: anywhere.eks.amazonaws.com/v1
kind: VSphereMachineConfig
metadata:
name: test-machine
namespace: default
spec:
diskGiB: 25 # increase this number to make the VM disk larger
numCPUs: 2 # increase this number to add vCPUs to your VM
memoryMiB: 8192 # increase this number to add memory to your VM
Once you have made configuration updates you can apply the changes to your cluster. If you are adding or removing a node, only the terminated nodes will be affected. If you are vertically scaling your nodes, then all nodes will be replaced one at a time.
eksctl anywhere upgrade cluster -f cluster.yaml
Semi-automatic scaling
Scaling your cluster in a semi-automatic way still requires changing your cluster manifest configuration. In a semi-automatic mode you change your cluster spec and then have automation make the cluster changes.
You can do this by storing your cluster config manifest in git and then having a CI/CD system deploy your changes. Or you can use a GitOps controller to apply the changes. To read more about making changes with the integrated Flux GitOps controller you can read how to Manage a cluster with GitOps .
Autoscaling
EKS Anywhere supports autoscaling of worker node groups using the Kubernetes Cluster Autoscaler and as a curated package .
See here for details on how to configure your cluster spec to autoscale worker node groups for autoscaling.
3 - Upgrade cluster
3.1 - Upgrade Bare Metal cluster
EKS Anywhere provides the command upgrade, which allows you to upgrade various aspects of your EKS Anywhere cluster.
When you run eksctl anywhere upgrade cluster -f ./cluster.yaml, EKS Anywhere runs a set of preflight checks to ensure your cluster is ready to be upgraded.
EKS Anywhere then performs the upgrade, modifying your cluster to match the updated specification.
The upgrade command also upgrades core components of EKS Anywhere and lets the user enjoy the latest features, bug fixes and security patches.
NOTE: Currently only Minor Version Upgrades are support for Bare Metal clusters. No other aspects of the cluster upgrades are currently supported.
Minor Version Upgrades
Kubernetes has minor releases three times per year and EKS Distro follows a similar cadence. EKS Anywhere will add support for new EKS Distro releases as they are released, and you are advised to upgrade your cluster when possible.
Cluster upgrades are not handled automatically and require administrator action to modify the cluster specification and perform an upgrade. You are advised to upgrade your clusters in development environments first and verify your workloads and controllers are compatible with the new version.
Cluster upgrades are performed using a rolling upgrade process (similar to Kubernetes Deployments).
Upgrades can only happen one minor version at a time (e.g. 1.24 -> 1.25).
Control plane components will be upgraded before worker nodes.
Prerequisites
This type of upgrade requires you to have one spare hardware server for control plane upgrade and one for each worker node group upgrade. The spare hardware server is provisioned with the new version and then an old server is deprovisioned. The deprovisioned server is then reprovisioned with the new version while another old server is deprovisioned. This happens one at a time until all the control plane components have been upgraded, followed by worker node upgrades.
Core component upgrades
EKS Anywhere upgrade also supports upgrading the following core components:
- Core CAPI
- CAPI providers
- Cilium CNI plugin
- Cert-manager
- Etcdadm CAPI provider
- EKS Anywhere controllers and CRDs
- GitOps controllers (Flux) - this is an optional component, will be upgraded only if specified
The latest versions of these core EKS Anywhere components are embedded into a bundles manifest that the CLI uses to fetch the latest versions and image builds needed for each component upgrade. The command detects both component version changes and new builds of the same versioned component. If there is a new Kubernetes version that is going to get rolled out, the core components get upgraded before the Kubernetes version. Irrespective of a Kubernetes version change, the upgrade command will always upgrade the internal EKS Anywhere components mentioned above to their latest available versions. All upgrade changes are backwards compatible.
Check upgrade components
Before you perform an upgrade, check the current and new versions of components that are ready to upgrade by typing:
eksctl anywhere upgrade plan cluster -f cluster.yaml
The output should appear similar to the following:
Worker node group name not specified. Defaulting name to md-0.
Warning: The recommended number of control plane nodes is 3 or 5
Worker node group name not specified. Defaulting name to md-0.
Checking new release availability...
NAME CURRENT VERSION NEXT VERSION
EKS-A v0.0.0-dev+build.1000+9886ba8 v0.0.0-dev+build.1105+46598cb
cluster-api v1.0.2+e8c48f5 v1.0.2+1274316
kubeadm v1.0.2+92c6d7e v1.0.2+aa1a03a
vsphere v1.0.1+efb002c v1.0.1+ef26ac1
kubadm v1.0.2+f002eae v1.0.2+f443dcf
etcdadm-bootstrap v1.0.2-rc3+54dcc82 v1.0.0-rc3+df07114
etcdadm-controller v1.0.2-rc3+a817792 v1.0.0-rc3+a310516
To format the output in json, add -o json to the end of the command line.
Check hardware availability
Next, you must ensure you have enough available hardware for the rolling upgrade operation to function. This type of upgrade requires you to have one spare hardware server for control plane upgrade and one for each worker node group upgrade. Check prerequisites for more information. Available hardware could have been fed to the cluster as extra hardware during a prior create command, or could be fed to the cluster during the upgrade process by providing the hardware CSV file to the upgrade cluster command .
To check if you have enough available hardware for rolling upgrade, you can use the kubectl command below to check if there are hardware objects with the selector labels corresponding to the controlplane/worker node group and without the ownerName label.
kubectl get hardware -n eksa-system --show-labels
For example, if you want to perform upgrade on a cluster with one worker node group with selector label type=worker-group-1, then you must have an additional hardware object in your cluster with the label type=controlplane (for control plane upgrade) and one with type=worker-group-1 (for worker node group upgrade) that doesn’t have the ownerName label.
In the command shown below, eksa-worker2 matches the selector label and it doesn’t have the ownerName label. Thus, it can be used to perform rolling upgrade of worker-group-1. Similarly, eksa-controlplane-spare will be used for rolling upgrade of control plane.
kubectl get hardware -n eksa-system --show-labels
NAME STATE LABELS
eksa-controlplane type=controlplane,v1alpha1.tinkerbell.org/ownerName=abhnvp-control-plane-template-1656427179688-9rm5f,v1alpha1.tinkerbell.org/ownerNamespace=eksa-system
eksa-controlplane-spare type=controlplane
eksa-worker1 type=worker-group-1,v1alpha1.tinkerbell.org/ownerName=abhnvp-md-0-1656427179689-9fqnx,v1alpha1.tinkerbell.org/ownerNamespace=eksa-system
eksa-worker2 type=worker-group-1
If you don’t have any available hardware that match this requirement in the cluster, you can setup a new hardware CSV . You can feed this hardware inventory file during the upgrade cluster command .
Performing a cluster upgrade
To perform a cluster upgrade you can modify your cluster specification kubernetesVersion field to the desired version.
As an example, to upgrade a cluster with version 1.24 to 1.25 you would change your spec as follows:
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: Cluster
metadata:
name: dev
spec:
controlPlaneConfiguration:
count: 1
endpoint:
host: "198.18.99.49"
machineGroupRef:
kind: TinkerbellMachineConfig
name: dev
...
kubernetesVersion: "1.25"
...
NOTE: If you have a custom machine image for your nodes in your cluster config yaml you may also need to update your
TinkerbellDatacenterConfigwith a newosImageURL.
and then you will run the upgrade cluster command .
Upgrade cluster command
With hardware CSV
eksctl anywhere upgrade cluster -f cluster.yaml --hardware-csv <hardware.csv>
Without hardware CSV
eksctl anywhere upgrade cluster -f cluster.yaml
This will upgrade the cluster specification (if specified), upgrade the core components to the latest available versions and apply the changes using the provisioner controllers.
Output
Example output:
✅ control plane ready
✅ worker nodes ready
✅ nodes ready
✅ cluster CRDs ready
✅ cluster object present on workload cluster
✅ upgrade cluster kubernetes version increment
✅ validate immutable fields
🎉 all cluster upgrade preflight validations passed
Performing provider setup and validations
Pausing EKS-A cluster controller reconcile
Pausing Flux kustomization
GitOps field not specified, pause flux kustomization skipped
Creating bootstrap cluster
Installing cluster-api providers on bootstrap cluster
Moving cluster management from workload to bootstrap cluster
Upgrading workload cluster
Moving cluster management from bootstrap to workload cluster
Applying new EKS-A cluster resource; resuming reconcile
Resuming EKS-A controller reconciliation
Updating Git Repo with new EKS-A cluster spec
GitOps field not specified, update git repo skipped
Forcing reconcile Git repo with latest commit
GitOps not configured, force reconcile flux git repo skipped
Resuming Flux kustomization
GitOps field not specified, resume flux kustomization skipped
During the upgrade process, EKS Anywhere pauses the cluster controller reconciliation by adding the paused annotation anywhere.eks.amazonaws.com/paused: true to the EKS Anywhere cluster, provider datacenterconfig and machineconfig resources, before the components upgrade. After upgrade completes, the annotations are removed so that the cluster controller resumes reconciling the cluster.
Though not recommended, you can manually pause the EKS Anywhere cluster controller reconciliation to perform extended maintenance work or interact with Cluster API objects directly. To do it, you can add the paused annotation to the cluster resource:
kubectl annotate clusters.anywhere.eks.amazonaws.com ${CLUSTER_NAME} -n ${CLUSTER_NAMESPACE} anywhere.eks.amazonaws.com/paused=true
After finishing the task, make sure you resume the cluster reconciliation by removing the paused annotation, so that EKS Anywhere cluster controller can continue working as expected.
kubectl annotate clusters.anywhere.eks.amazonaws.com ${CLUSTER_NAME} -n ${CLUSTER_NAMESPACE} anywhere.eks.amazonaws.com/paused-
Upgradeable cluster attributes
Cluster:
kubernetesVersion
Advanced configuration for rolling upgrade
EKS Anywhere allows an optional configuration to customize the behavior of upgrades.
It allows the specification of Two parameters that control the desired behavior of rolling upgrades:
- maxSurge - The maximum number of machines that can be scheduled above the desired number of machines. When not specified, the current CAPI default of 1 is used.
- maxUnavailable - The maximum number of machines that can be unavailable during the upgrade. When not specified, the current CAPI default of 0 is used.
Example configuration:
upgradeRolloutStrategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0 # only configurable for worker nodes
‘upgradeRolloutStrategy’ configuration can be specified separately for control plane and for each worker node group. This template contains an example for control plane under the ‘controlPlaneConfiguration’ section and for worker node group under ‘workerNodeGroupConfigurations’:
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: Cluster
metadata:
name: my-cluster-name
spec:
clusterNetwork:
cniConfig:
cilium: {}
pods:
cidrBlocks:
- 192.168.0.0/16
services:
cidrBlocks:
- 10.96.0.0/12
controlPlaneConfiguration:
count: 1
endpoint:
host: "10.61.248.209"
machineGroupRef:
kind: TinkerbellMachineConfig
name: my-cluster-name-cp
upgradeRolloutStrategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
datacenterRef:
kind: TinkerbellDatacenterConfig
name: my-cluster-name
kubernetesVersion: "1.25"
managementCluster:
name: my-cluster-name
workerNodeGroupConfigurations:
- count: 2
machineGroupRef:
kind: TinkerbellMachineConfig
name: my-cluster-name
name: md-0
upgradeRolloutStrategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
---
...
upgradeRolloutStrategy
Configuration parameters for upgrade strategy.
upgradeRolloutStrategy.type
Type of rollout strategy. Currently only RollingUpdate is supported.
upgradeRolloutStrategy.rollingUpdate
Configuration parameters for customizing rolling upgrade behavior.
upgradeRolloutStrategy.rollingUpdate.maxSurge
Default: 1
This can not be 0 if maxUnavailable is 0.
The maximum number of machines that can be scheduled above the desired number of machines.
Example: When this is set to n, the new worker node group can be scaled up immediately by n when the rolling upgrade starts. Total number of machines in the cluster (old + new) never exceeds (desired number of machines + n). Once scale down happens and old machines are brought down, the new worker node group can be scaled up further ensuring that the total number of machines running at any time does not exceed the desired number of machines + n.
upgradeRolloutStrategy.rollingUpdate.maxUnavailable
Default: 0
This can not be 0 if MaxSurge is 0.
The maximum number of machines that can be unavailable during the upgrade.
Example: When this is set to n, the old worker node group can be scaled down by n machines immediately when the rolling upgrade starts. Once new machines are ready, old worker node group can be scaled down further, followed by scaling up the new worker node group, ensuring that the total number of machines unavailable at all times during the upgrade never falls below n.
Rolling upgrades with no additional hardware
When maxSurge is set to 0 and maxUnavailable is set to 1, it allows for a rolling upgrade without need for additional hardware. Use this configuration if your workloads can tolerate node unavailability.
NOTE: This could ONLY be used if unavailability of a maximum of 1 node is acceptable. For single node clusters, an additional temporary machine is a must. Alternatively, you may recreate the single node cluster for upgrading and handle data recovery manually.
With this kind of configuration, the rolling upgrade will proceed node by node, deprovision and delete a node fully before re-provisioning it with upgraded version, and re-join it to the cluster. This means that any point during the course of the rolling upgrade, there could be one unavailable node.
Troubleshooting
Attempting to upgrade a cluster with more than 1 minor release will result in receiving the following error.
✅ validate immutable fields
❌ validation failed {"validation": "Upgrade preflight validations", "error": "validation failed with 1 errors: WARNING: version difference between upgrade version (1.21) and server version (1.19) do not meet the supported version increment of +1", "remediation": ""}
Error: failed to upgrade cluster: validations failed
For more errors you can see the troubleshooting section .
3.2 - Upgrade vSphere, CloudStack, Nutanix, or Snow cluster
EKS Anywhere provides the command upgrade, which allows you to upgrade various aspects of your EKS Anywhere cluster.
When you run eksctl anywhere upgrade cluster -f ./cluster.yaml, EKS Anywhere runs a set of preflight checks to ensure your cluster is ready to be upgraded.
EKS Anywhere then performs the upgrade, modifying your cluster to match the updated specification.
The upgrade command also upgrades core components of EKS Anywhere and lets the user enjoy the latest features, bug fixes and security patches.
NOTE: If an upgrade fails, it is very important not to delete the Docker containers running the KinD bootstrap cluster. During an upgrade, the bootstrap cluster contains critical EKS Anywhere components. If it is deleted after a failed upgrade, they cannot be recovered.
Minor Version Upgrades
Kubernetes has minor releases three times per year and EKS Distro follows a similar cadence. EKS Anywhere will add support for new EKS Distro releases as they are released, and you are advised to upgrade your cluster when possible.
Cluster upgrades are not handled automatically and require administrator action to modify the cluster specification and perform an upgrade. You are advised to upgrade your clusters in development environments first and verify your workloads and controllers are compatible with the new version.
Cluster upgrades are performed in place using a rolling process (similar to Kubernetes Deployments).
Upgrades can only happen one minor version at a time (e.g. 1.24 -> 1.25).
Control plane components will be upgraded before worker nodes.
A new VM is created with the new version and then an old VM is removed. This happens one at a time until all the control plane components have been upgraded.
Core component upgrades
EKS Anywhere upgrade also supports upgrading the following core components:
- Core CAPI
- CAPI providers
- Cilium CNI plugin
- Cert-manager
- Etcdadm CAPI provider
- EKS Anywhere controllers and CRDs
- GitOps controllers (Flux) - this is an optional component, will be upgraded only if specified
The latest versions of these core EKS Anywhere components are embedded into a bundles manifest that the CLI uses to fetch the latest versions and image builds needed for each component upgrade. The command detects both component version changes and new builds of the same versioned component. If there is a new Kubernetes version that is going to get rolled out, the core components get upgraded before the Kubernetes version. Irrespective of a Kubernetes version change, the upgrade command will always upgrade the internal EKS Anywhere components mentioned above to their latest available versions. All upgrade changes are backwards compatible.
Specifically for Snow provider, a new Admin instance is needed when upgrading to the new versions of EKS Anywhere. See Upgrade EKS Anywhere AMIs in Snowball Edge devices to upgrade and use a new Admin instance in Snow devices. After that, ugrades of other components can be done as described in this document.
Check upgrade components
Before you perform an upgrade, check the current and new versions of components that are ready to upgrade by typing:
Management Cluster
eksctl anywhere upgrade plan cluster -f mgmt-cluster.yaml
Workload Cluster
eksctl anywhere upgrade plan cluster -f workload-cluster.yaml --kubeconfig mgmt/mgmt-eks-a-cluster.kubeconfig
The output should appear similar to the following:
Worker node group name not specified. Defaulting name to md-0.
Warning: The recommended number of control plane nodes is 3 or 5
Worker node group name not specified. Defaulting name to md-0.
Checking new release availability...
NAME CURRENT VERSION NEXT VERSION
EKS-A v0.0.0-dev+build.1000+9886ba8 v0.0.0-dev+build.1105+46598cb
cluster-api v1.0.2+e8c48f5 v1.0.2+1274316
kubeadm v1.0.2+92c6d7e v1.0.2+aa1a03a
vsphere v1.0.1+efb002c v1.0.1+ef26ac1
kubadm v1.0.2+f002eae v1.0.2+f443dcf
etcdadm-bootstrap v1.0.2-rc3+54dcc82 v1.0.0-rc3+df07114
etcdadm-controller v1.0.2-rc3+a817792 v1.0.0-rc3+a310516
To the format output in json, add -o json to the end of the command line.
Performing a cluster upgrade
To perform a cluster upgrade you can modify your cluster specification kubernetesVersion field to the desired version.
As an example, to upgrade a cluster with version 1.24 to 1.25 you would change your spec
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: Cluster
metadata:
name: dev
spec:
controlPlaneConfiguration:
count: 1
endpoint:
host: "198.18.99.49"
machineGroupRef:
kind: VSphereMachineConfig
name: dev
...
kubernetesVersion: "1.25"
...
NOTE: If you have a custom machine image for your nodes you may also need to update your
vsphereMachineConfigwith a newtemplate.
and then you will run the command
Management Cluster
eksctl anywhere upgrade cluster -f mgmt-cluster.yaml
Workload Cluster
eksctl anywhere upgrade cluster -f workload-cluster.yaml --kubeconfig mgmt/mgmt-eks-a-cluster.kubeconfig
This will upgrade the cluster specification (if specified), upgrade the core components to the latest available versions and apply the changes using the provisioner controllers.
Example output:
✅ control plane ready
✅ worker nodes ready
✅ nodes ready
✅ cluster CRDs ready
✅ cluster object present on workload cluster
✅ upgrade cluster kubernetes version increment
✅ validate immutable fields
🎉 all cluster upgrade preflight validations passed
Performing provider setup and validations
Pausing EKS-A cluster controller reconcile
Pausing Flux kustomization
GitOps field not specified, pause flux kustomization skipped
Creating bootstrap cluster
Installing cluster-api providers on bootstrap cluster
Moving cluster management from workload to bootstrap cluster
Upgrading workload cluster
Moving cluster management from bootstrap to workload cluster
Applying new EKS-A cluster resource; resuming reconcile
Resuming EKS-A controller reconciliation
Updating Git Repo with new EKS-A cluster spec
GitOps field not specified, update git repo skipped
Forcing reconcile Git repo with latest commit
GitOps not configured, force reconcile flux git repo skipped
Resuming Flux kustomization
GitOps field not specified, resume flux kustomization skipped
During the upgrade process, EKS Anywhere pauses the cluster controller reconciliation by adding the paused annotation anywhere.eks.amazonaws.com/paused: true to the EKS Anywhere cluster, provider datacenterconfig and machineconfig resources, before the components upgrade. After upgrade completes, the annotations are removed so that the cluster controller resumes reconciling the cluster.
Though not recommended, you can manually pause the EKS Anywhere cluster controller reconciliation to perform extended maintenance work or interact with Cluster API objects directly. To do it, you can add the paused annotation to the cluster resource:
kubectl annotate clusters.anywhere.eks.amazonaws.com ${CLUSTER_NAME} -n ${CLUSTER_NAMESPACE} anywhere.eks.amazonaws.com/paused=true
After finishing the task, make sure you resume the cluster reconciliation by removing the paused annotation, so that EKS Anywhere cluster controller can continue working as expected.
kubectl annotate clusters.anywhere.eks.amazonaws.com ${CLUSTER_NAME} -n ${CLUSTER_NAMESPACE} anywhere.eks.amazonaws.com/paused-
Upgradeable Cluster Attributes
EKS Anywhere upgrade supports upgrading more than just the kubernetesVersion,
allowing you to upgrade a number of fields simultaneously with the same procedure.
Upgradeable Attributes
Cluster:
kubernetesVersioncontrolPlaneConfig.countcontrolPlaneConfigurations.machineGroupRef.nameworkerNodeGroupConfigurations.countworkerNodeGroupConfigurations.machineGroupRef.nameetcdConfiguration.externalConfiguration.machineGroupRef.nameidentityProviderRefs(Only forkind:OIDCConfig,kind:AWSIamConfigis immutable)gitOpsRef(Once set, you can’t change or delete the field’s content later)
VSphereMachineConfig:
datastorediskGiBfoldermemoryMiBnumCPUsresourcePooltemplateusers
NutanixMachineConfig:
vcpusPerSocketvcpuSocketsmemorySizeimageclustersubnetsystemDiskSize
SnowMachineConfig:
amiIDinstanceTypephysicalNetworkConnectorsshKeyNamedevicescontainersVolumeosFamilynetwork
OIDCConfig:
clientIDgroupsClaimgroupsPrefixissuerUrlrequiredClaims.claimrequiredClaims.valueusernameClaimusernamePrefix
AWSIamConfig:
mapRolesmapUsers
EKS Anywhere upgrade also supports adding more worker node groups post-creation.
To add more worker node groups, modify your cluster config file to define the additional group(s).
Example:
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: Cluster
metadata:
name: dev
spec:
controlPlaneConfiguration:
...
workerNodeGroupConfigurations:
- count: 2
machineGroupRef:
kind: VSphereMachineConfig
name: my-cluster-machines
name: md-0
- count: 2
machineGroupRef:
kind: VSphereMachineConfig
name: my-cluster-machines
name: md-1
...
Worker node groups can use the same machineGroupRef as previous groups, or you can define a new machine configuration for your new group.
Resume upgrade after failure
EKS Anywhere supports re-running the upgrade command post-failure as an experimental feature.
If the upgrade command fails, the user can manually fix the issue (when applicable) and simply rerun the same command. At this point, the CLI will skip the completed tasks, restore the state of the operation, and resume the upgrade process.
The completed tasks are stored in the generated folder as a file named <clusterName>-checkpoint.yaml.
This feature is experimental. To enable this feature, export the following environment variable:
export CHECKPOINT_ENABLED=true
Troubleshooting
Attempting to upgrade a cluster with more than 1 minor release will result in receiving the following error.
✅ validate immutable fields
❌ validation failed {"validation": "Upgrade preflight validations", "error": "validation failed with 1 errors: WARNING: version difference between upgrade version (1.21) and server version (1.19) do not meet the supported version increment of +1", "remediation": ""}
Error: failed to upgrade cluster: validations failed
For more errors you can see the troubleshooting section .
4 - Etcd Backup and Restore
NOTE: External etcd topology is supported for vSphere and CloudStack clusters, but not yet for Bare Metal or Nutanix clusters.
This page contains steps for backing up a cluster by taking an etcd snapshot, and restoring the cluster from a snapshot. These steps are for an EKS Anywhere cluster provisioned using the external etcd topology (selected by default) and Ubuntu OVAs.
Use case
EKS-Anywhere clusters use etcd as the backing store. Taking a snapshot of etcd backs up the entire cluster data. This can later be used to restore a cluster back to an earlier state if required. Etcd backups can be taken prior to cluster upgrade, so if the upgrade doesn’t go as planned you can restore from the backup.
Backup
Etcd offers a built-in snapshot mechanism. You can take a snapshot using the etcdctl snapshot save command by following the steps given below.
- Login to any one of the etcd VMs
ssh -i $PRIV_KEY ec2-user@$ETCD_VM_IP
- Run the etcdctl command to take a snapshot with the following steps
sudo su
source /etc/etcd/etcdctl.env
etcdctl snapshot save snapshot.db
chown ec2-user snapshot.db
- Exit the VM. Copy the snapshot from the VM to your local/admin setup where you can save snapshots in a secure place. Before running scp, make sure you don’t already have a snapshot file saved by the same name locally.
scp -i $PRIV_KEY ec2-user@$ETCD_VM_IP:/home/ec2-user/snapshot.db .
NOTE: This snapshot file contains all information stored in the cluster, so make sure you save it securely (encrypt it).
Restore
Restoring etcd is a 2-part process. The first part is restoring etcd using the snapshot, creating a new data-dir for etcd. The second part is replacing the current etcd data-dir with the one generated after restore. During etcd data-dir replacement, we cannot have any kube-apiserver instances running in the cluster. So we will first stop all instances of kube-apiserver and other controlplane components using the following steps for every controlplane VM:
Pausing Etcdadm controller reconcile
During restore, it is required to pause the Etcdadm controller reconcile for the target cluster (whether it is management or workload cluster). To do that, you need to add a cluster.x-k8s.io/paused annotation to the target cluster’s etcdadmclusters resource. For example,
kubectl annotate etcdadmclusters workload-cluster-1-etcd cluster.x-k8s.io/paused=true -n eksa-system --kubeconfig mgmt-cluster.kubeconfig
Stopping the controlplane components
- Login to a controlplane VM
ssh -i $PRIV_KEY ec2-user@$CONTROLPLANE_VM_IP
- Stop controlplane components by moving the static pod manifests under a temp directory:
sudo su
mkdir temp-manifests
mv /etc/kubernetes/manifests/*.yaml temp-manifests
- Repeat these steps for all other controlplane VMs
After this you can restore etcd from a saved snapshot using the etcdctl snapshot save command following the steps given below.
Restoring from the snapshot
- The snapshot file should be made available in every etcd VM of the cluster. You can copy it to each etcd VM using this command:
scp -i $PRIV_KEY snapshot.db ec2-user@$ETCD_VM_IP:/home/ec2-user
- To run the etcdctl snapshot restore command, you need to provide the following configuration parameters:
- name: This is the name of the etcd member. The value of this parameter should match the value used while starting the member. This can be obtained by running:
export ETCD_NAME=$(cat /etc/etcd/etcd.env | grep ETCD_NAME | awk -F'=' '{print $2}')
- initial-advertise-peer-urls: This is the advertise peer URL with which this etcd member was configured. It should be the exact value with which this etcd member was started. This can be obtained by running:
export ETCD_INITIAL_ADVERTISE_PEER_URLS=$(cat /etc/etcd/etcd.env | grep ETCD_INITIAL_ADVERTISE_PEER_URLS | awk -F'=' '{print $2}')
- initial-cluster: This should be a comma-separated mapping of etcd member name and its peer URL. For this, get the
ETCD_NAMEandETCD_INITIAL_ADVERTISE_PEER_URLSvalues for each member and join them. And then use this exact value for all etcd VMs. For example, for a 3 member etcd cluster this is what the value would look like (The command below cannot be run directly without substituting the required variables and is meant to be an example)
export ETCD_INITIAL_CLUSTER=${ETCD_NAME_1}=${ETCD_INITIAL_ADVERTISE_PEER_URLS_1},${ETCD_NAME_2}=${ETCD_INITIAL_ADVERTISE_PEER_URLS_2},${ETCD_NAME_3}=${ETCD_INITIAL_ADVERTISE_PEER_URLS_3}
- initial-cluster-token: Set this to a unique value and use the same value for all etcd members of the cluster. It can be any value such as
etcd-cluster-1as long as it hasn’t been used before.
- Gather the required env vars for the restore command
cat <<EOF >> restore.env
export ETCD_NAME=$(cat /etc/etcd/etcd.env | grep ETCD_NAME | awk -F'=' '{print $2}')
export ETCD_INITIAL_ADVERTISE_PEER_URLS=$(cat /etc/etcd/etcd.env | grep ETCD_INITIAL_ADVERTISE_PEER_URLS | awk -F'=' '{print $2}')
EOF
cat /etc/etcd/etcdctl.env >> restore.env
- Make sure you form the correct
ETCD_INITIAL_CLUSTERvalue using all etcd members, and set it as an env var in the restore.env file created in the above step. - Once you have obtained all the right values, run the following commands to restore etcd replacing the required values:
sudo su
source restore.env
etcdctl snapshot restore snapshot.db --name=${ETCD_NAME} --initial-cluster=${ETCD_INITIAL_CLUSTER} --initial-cluster-token=etcd-cluster-1 --initial-advertise-peer-urls=${ETCD_INITIAL_ADVERTISE_PEER_URLS}
- This is going to create a new data-dir for the restored contents under a new directory
{ETCD_NAME}.etcd. To start using this, restart etcd with the new data-dir with the following steps:
systemctl stop etcd.service
mv /var/lib/etcd/member /var/lib/etcd/member.bak
mv ${ETCD_NAME}.etcd/member /var/lib/etcd/
- Perform this directory swap on all etcd VMs, and then start etcd again on those VMs
systemctl start etcd.service
NOTE: Until the etcd process is started on all VMs, it might appear stuck on the VMs where it was started first, but this should be temporary.
Starting the controlplane components
- Login to a controlplane VM
ssh -i $PRIV_KEY ec2-user@$CONTROLPLANE_VM_IP
- Start the controlplane components by moving back the static pod manifests from under the temp directory to the /etc/kubernetes/manifests directory:
mv temp-manifests/*.yaml /etc/kubernetes/manifests
- Repeat these steps for all other controlplane VMs
- It may take a few minutes for the kube-apiserver and the other components to get restarted. After this you should be able to access all objects present in the cluster at the time the backup was taken.
Resuming Etcdadm controller reconcile
Resume Etcdadm controller reconcile for the target cluster by removing the cluster.x-k8s.io/paused annotation in the target cluster’s etcdadmclusters resource. For example,
kubectl annotate etcdadmclusters workload-cluster-1-etcd cluster.x-k8s.io/paused- -n eksa-system
5 - Verify cluster
To verify that a cluster control plane is up and running, use the kubectl command to show that the control plane pods are all running.
kubectl get po -A -l control-plane=controller-manager
NAMESPACE NAME READY STATUS RESTARTS AGE
capi-kubeadm-bootstrap-system capi-kubeadm-bootstrap-controller-manager-57b99f579f-sd85g 2/2 Running 0 47m
capi-kubeadm-control-plane-system capi-kubeadm-control-plane-controller-manager-79cdf98fb8-ll498 2/2 Running 0 47m
capi-system capi-controller-manager-59f4547955-2ks8t 2/2 Running 0 47m
capi-webhook-system capi-controller-manager-bb4dc9878-2j8mg 2/2 Running 0 47m
capi-webhook-system capi-kubeadm-bootstrap-controller-manager-6b4cb6f656-qfppd 2/2 Running 0 47m
capi-webhook-system capi-kubeadm-control-plane-controller-manager-bf7878ffc-rgsm8 2/2 Running 0 47m
capi-webhook-system capv-controller-manager-5668dbcd5-v5szb 2/2 Running 0 47m
capv-system capv-controller-manager-584886b7bd-f66hs 2/2 Running 0 47m
You may also check the status of the cluster control plane resource directly. This can be especially useful to verify clusters with multiple control plane nodes after an upgrade.
kubectl get kubeadmcontrolplanes.controlplane.cluster.x-k8s.io
NAME INITIALIZED API SERVER AVAILABLE VERSION REPLICAS READY UPDATED UNAVAILABLE
supportbundletestcluster true true v1.20.7-eks-1-20-6 1 1 1
To verify that the expected number of cluster worker nodes are up and running, use the kubectl command to show that nodes are Ready.
This will confirm that the expected number of worker nodes are present.
Worker nodes are named using the cluster name followed by the worker node group name (example: my-cluster-md-0)
kubectl get nodes
NAME STATUS ROLES AGE VERSION
supportbundletestcluster-md-0-55bb5ccd-mrcf9 Ready <none> 4m v1.20.7-eks-1-20-6
supportbundletestcluster-md-0-55bb5ccd-zrh97 Ready <none> 4m v1.20.7-eks-1-20-6
supportbundletestcluster-mdrwf Ready control-plane,master 5m v1.20.7-eks-1-20-6
To test a workload in your cluster you can try deploying the hello-eks-anywhere .
6 - Add cluster integrations
EKS Anywhere offers AWS support for certain third-party vendor components, namely Ubuntu TLS, Cilium, and Flux. It also provides flexibility for you to integrate with your choice of tools in other areas. Below is a list of example third-party tools your consideration.
For a full list of partner integration options, please visit Amazon EKS Anywhere Partner page .
Note
The solutions listed on this page have not been tested by AWS and are not covered by the EKS Anywhere Support Subscription.| Feature | Example third-party tools |
|---|---|
| Ingress controller | Gloo Edge , Emissary-ingress (previously Ambassador) |
| Service type load balancer | MetalLB |
| Local container repository | Harbor |
| Monitoring | Prometheus , Grafana , Datadog , or NewRelic |
| Logging | Splunk or Fluentbit |
| Secret management | Hashi Vault |
| Policy agent | Open Policy Agent |
| Service mesh | Istio , Gloo Mesh , or Linkerd |
| Cost management | KubeCost |
| Etcd backup and restore | Velero |
| Storage | Default storage class, any compatible CSI |
7 - Reboot nodes
If you need to reboot a node in your cluster for maintenance or any other reason, performing the following steps will help prevent possible disruption of services on those nodes:
Warning
Rebooting a cluster node as described here is good for all nodes, but is critically important when rebooting a Bottlerocket node running theboots service on a Bare Metal cluster.
If it does go down while running the boots service, the Bottlerocket node will not be able to boot again until the boots service is restored on another machine. This is because Bottlerocket must get its address from a DHCP service.
-
Cordon the node so no further workloads are scheduled to run on it:
kubectl cordon <node-name> -
Drain the node of all current workloads:
kubectl drain <node-name> -
Shut down. Using the appropriate method for your provider, shut down the node.
-
Perform system maintenance or other task you need to do on the node and boot up the node.
-
Uncordon the node so that it can begin receiving workloads again.
kubectl uncordon <node-name>
8 - Connect cluster to console
The AWS EKS Connector lets you connect your EKS Anywhere cluster to the AWS EKS console, where you can see your the EKS Anywhere cluster, its configuration, workloads, and their status. EKS Connector is a software agent that can be deployed on your EKS Anywhere cluster, enabling the cluster to register with the EKS console.
Visit AWS EKS Connector for details.
9 - License cluster
If you are are licensing an existing cluster, apply the following secret to your cluster (replacing my-license-here with your license):
kubectl apply -f - <<EOF
apiVersion: v1
kind: Secret
metadata:
name: eksa-license
namespace: eksa-system
stringData:
license: "my-license-here"
type: Opaque
EOF
10 - Multus CNI plugin configuration
NOTE: Currently, Multus support is only available with the EKS Anywhere Bare Metal provider. The vSphere and CloudStack providers, do not have multi-network support for cluster machines. Once multiple network support is added to those clusters, Multus CNI can be supported.
Multus CNI is a container network interface plugin for Kubernetes that enables attaching multiple network interfaces to pods. In Kubernetes, each pod has only one network interface by default, other than local loopback. With Multus, you can create multi-homed pods that have multiple interfaces. Multus acts a as ‘meta’ plugin that can call other CNI plugins to configure additional interfaces.
Pre-Requisites
Given that Multus CNI is used to create pods with multiple network interfaces, the cluster machines that these pods run on need to have multiple network interfaces attached and configured. The interfaces on multi-homed pods need to map to these interfaces on the machines.
For Bare Metal clusters using the Tinkerbell provider, the cluster machines need to have multiple network interfaces cabled in and appropriate network configuration put in place during machine provisioning.
Overview of Multus setup
The following diagrams show the result of two applications (app1 and app2) running in pods that use the Multus plugin to communicate over two network interfaces (eth0 and net1) from within the pods. The Multus plugin uses two network interfaces on the worker node (eth0 and eth1) to provide communications outside of the node.
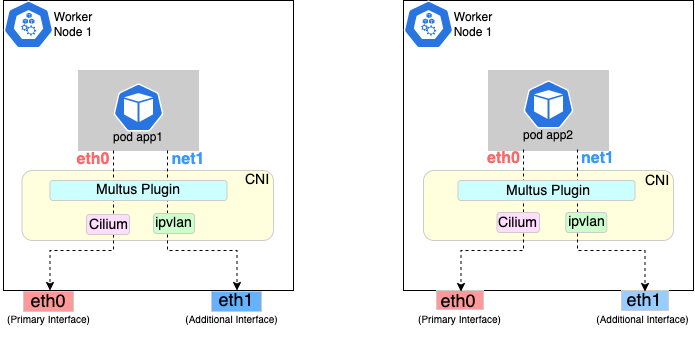
Follow the procedure below to set up Multus as illustrated in the previous diagrams.
Install and configure Multus
Deploying Multus using a Daemonset will spin up pods that install a Multus binary and configure Multus for usage in every node in the cluster. Here are the steps for doing that.
-
Clone the Multus CNI repo:
git clone https://github.com/k8snetworkplumbingwg/multus-cni.git && cd multus-cni -
Apply Multus daemonset to your EKS Anywhere cluster:
kubectl apply -f ./deployments/multus-daemonset-thick-plugin.yml -
Verify that you have Multus pods running:
kubectl get pods --all-namespaces | grep -i multus -
Check that Multus is running:
kubectl get pods -A | grep multusOutput:
kube-system kube-multus-ds-bmfjs 1/1 Running 0 3d1h kube-system kube-multus-ds-fk2sk 1/1 Running 0 3d1h
Create Network Attachment Definition
You need to create a Network Attachment Definition for the CNI you wish to use as the plugin for the additional interface.
You can verify that your intended CNI plugin is supported by ensuring that the binary corresponding to that CNI plugin is present in the node’s /opt/cni/bin directory.
Below is an example of a Network Attachment Definition yaml:
cat <<EOF | kubectl create -f -
apiVersion: "k8s.cni.cncf.io/v1"
kind: NetworkAttachmentDefinition
metadata:
name: ipvlan-conf
spec:
config: '{
"cniVersion": "0.3.0",
"type": "ipvlan",
"master": "eth1",
"mode": "l3",
"ipam": {
"type": "host-local",
"subnet": "198.17.0.0/24",
"rangeStart": "198.17.0.200",
"rangeEnd": "198.17.0.216",
"routes": [
{ "dst": "0.0.0.0/0" }
],
"gateway": "198.17.0.1"
}
}'
EOF
Note that eth1 is used as the master parameter.
This master parameter should match the interface name on the hosts in your cluster.
Verify the configuration
Type the following to verify the configuration you created:
kubectl get network-attachment-definitions
kubectl describe network-attachment-definitions ipvlan-conf
Deploy sample applications with network attachment
-
Create a sample application 1 (app1) with network annotation created in the previous steps:
cat <<EOF | kubectl apply -f - apiVersion: v1 kind: Pod metadata: name: app1 annotations: k8s.v1.cni.cncf.io/networks: ipvlan-conf spec: containers: - name: app1 command: ["/bin/sh", "-c", "trap : TERM INT; sleep infinity & wait"] image: alpine EOF -
Create a sample application 2 (app2) with the network annotation created in the previous step:
cat <<EOF | kubectl apply -f - apiVersion: v1 kind: Pod metadata: name: app2 annotations: k8s.v1.cni.cncf.io/networks: ipvlan-conf spec: containers: - name: app2 command: ["/bin/sh", "-c", "trap : TERM INT; sleep infinity & wait"] image: alpine EOF -
Verify that the additional interfaces were created on these application pods using the defined network attachment:
kubectl exec -it app1 -- ip aOutput:
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever *2: net1@if3: <BROADCAST,MULTICAST,NOARP,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UNKNOWN link/ether 00:50:56:9a:84:3b brd ff:ff:ff:ff:ff:ff inet 198.17.0.200/24 brd 198.17.0.255 scope global net1 valid_lft forever preferred_lft forever inet6 fe80::50:5600:19a:843b/64 scope link valid_lft forever preferred_lft forever* 31: eth0@if32: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP link/ether 0a:9e:a0:b4:21:05 brd ff:ff:ff:ff:ff:ff inet 192.168.1.218/32 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::89e:a0ff:feb4:2105/64 scope link valid_lft forever preferred_lft foreverkubectl exec -it app2 -- ip aOutput:
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever *2: net1@if3: <BROADCAST,MULTICAST,NOARP,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UNKNOWN link/ether 00:50:56:9a:84:3b brd ff:ff:ff:ff:ff:ff inet 198.17.0.201/24 brd 198.17.0.255 scope global net1 valid_lft forever preferred_lft forever inet6 fe80::50:5600:29a:843b/64 scope link valid_lft forever preferred_lft forever* 33: eth0@if34: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP link/ether b2:42:0a:67:c0:48 brd ff:ff:ff:ff:ff:ff inet 192.168.1.210/32 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::b042:aff:fe67:c048/64 scope link valid_lft forever preferred_lft foreverNote that both pods got the new interface net1. Also, the additional network interface on each pod got assigned an IP address out of the range specified by the Network Attachment Definition.
-
Test the network connectivity across these pods for Multus interfaces:
kubectl exec -it app1 -- ping -I net1 198.17.0.201Output:
PING 198.17.0.201 (198.17.0.201): 56 data bytes 64 bytes from 198.17.0.201: seq=0 ttl=64 time=0.074 ms 64 bytes from 198.17.0.201: seq=1 ttl=64 time=0.077 ms 64 bytes from 198.17.0.201: seq=2 ttl=64 time=0.078 ms 64 bytes from 198.17.0.201: seq=3 ttl=64 time=0.077 mskubectl exec -it app2 -- ping -I net1 198.17.0.200Output:
PING 198.17.0.200 (198.17.0.200): 56 data bytes 64 bytes from 198.17.0.200: seq=0 ttl=64 time=0.074 ms 64 bytes from 198.17.0.200: seq=1 ttl=64 time=0.077 ms 64 bytes from 198.17.0.200: seq=2 ttl=64 time=0.078 ms 64 bytes from 198.17.0.200: seq=3 ttl=64 time=0.077 ms
11 - Authenticate cluster with AWS IAM Authenticator
AWS IAM Authenticator Support (optional)
EKS Anywhere supports configuring AWS IAM Authenticator as an authentication provider for clusters.
When you create a cluster with IAM Authenticator enabled, EKS Anywhere
- Installs
aws-iam-authenticatorserver as a DaemonSet on the workload cluster. - Configures the Kubernetes API Server to communicate with iam authenticator using a token authentication webhook .
- Creates the necessary ConfigMaps based on user options.
Note
Enabling IAM Authenticator needs to be done during cluster creation.Create IAM Authenticator enabled cluster
Generate your cluster configuration and add the necessary IAM Authenticator configuration. For a full spec reference check AWSIamConfig .
Create an EKS Anywhere cluster as follows:
CLUSTER_NAME=my-cluster-name
eksctl anywhere create cluster -f ${CLUSTER_NAME}.yaml
Example AWSIamConfig configuration
This example uses a region in the default aws partition and EKSConfigMap as backendMode. Also, the IAM ARNs are mapped to the kubernetes system:masters group.
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: Cluster
metadata:
name: my-cluster-name
spec:
...
# IAM Authenticator
identityProviderRefs:
- kind: AWSIamConfig
name: aws-iam-auth-config
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: AWSIamConfig
metadata:
name: aws-iam-auth-config
spec:
awsRegion: us-west-1
backendMode:
- EKSConfigMap
mapRoles:
- roleARN: arn:aws:iam::XXXXXXXXXXXX:role/myRole
username: myKubernetesUsername
groups:
- system:masters
mapUsers:
- userARN: arn:aws:iam::XXXXXXXXXXXX:user/myUser
username: myKubernetesUsername
groups:
- system:masters
partition: aws
Note
When using backend modeCRD, the mapRoles and mapUsers are not required. For more details on configuring CRD mode, refer to CRD.
Authenticating with IAM Authenticator
After your cluster is created you may now use the mapped IAM ARNs to authenticate to the cluster.
EKS Anywhere generates a KUBECONFIG file in your local directory that uses aws-iam-authenticator client to authenticate with the cluster. The file can be found at
${PWD}/${CLUSTER_NAME}/${CLUSTER_NAME}-aws.kubeconfig
Steps
-
Ensure the IAM role/user ARN mapped in the cluster is configured on the local machine from which you are trying to access the cluster.
-
Install the
aws-iam-authenticator clientbinary on the local machine.- We recommend installing the binary referenced in the latest
release manifestof the kubernetes version used when creating the cluster. - The below commands can be used to fetch the installation uri for clusters created with
1.21kubernetes version and OSlinux.
CLUSTER_NAME=my-cluster-name KUBERNETES_VERSION=1.21 export KUBECONFIG=${PWD}/${CLUSTER_NAME}/${CLUSTER_NAME}-eks-a-cluster.kubeconfig EKS_D_MANIFEST_URL=$(kubectl get bundles $CLUSTER_NAME -o jsonpath="{.spec.versionsBundles[?(@.kubeVersion==\"$KUBERNETES_VERSION\")].eksD.manifestUrl}") OS=linux curl -fsSL $EKS_D_MANIFEST_URL | yq e '.status.components[] | select(.name=="aws-iam-authenticator") | .assets[] | select(.os == '"\"$OS\""' and .type == "Archive") | .archive.uri' - - We recommend installing the binary referenced in the latest
-
Export the generated IAM Authenticator based
KUBECONFIGfile.export KUBECONFIG=${PWD}/${CLUSTER_NAME}/${CLUSTER_NAME}-aws.kubeconfig -
Run
kubectlcommands to check cluster access. Example,kubectl get pods -A
Modify IAM Authenticator mappings
EKS Anywhere supports modifying IAM ARNs that are mapped on the cluster. The mappings can be modified by either running the upgrade cluster command or using GitOps.
upgrade command
The mapRoles and mapUsers lists in AWSIamConfig can be modified when running the upgrade cluster command from EKS Anywhere.
As an example, let’s add another IAM user to the above example configuration.
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: AWSIamConfig
metadata:
name: aws-iam-auth-config
spec:
...
mapUsers:
- userARN: arn:aws:iam::XXXXXXXXXXXX:user/myUser
username: myKubernetesUsername
groups:
- system:masters
- userARN: arn:aws:iam::XXXXXXXXXXXX:user/anotherUser
username: anotherKubernetesUsername
partition: aws
and then run the upgrade command
CLUSTER_NAME=my-cluster-name
eksctl anywhere upgrade cluster -f ${CLUSTER_NAME}.yaml
EKS Anywhere now updates the role mappings for IAM authenticator in the cluster and a new user gains access to the cluster.
GitOps
If the cluster created has GitOps configured, then the mapRoles and mapUsers list in AWSIamConfig can be modified by the GitOps controller. For GitOps configuration details refer to Manage Cluster with GitOps
.
Note
GitOps support for theAWSIamConfig is currently only on management or self-managed clusters.
- Clone your git repo and modify the cluster specification.
The default path for the cluster file is:
clusters/$CLUSTER_NAME/eksa-system/eksa-cluster.yaml - Modify the
AWSIamConfigobject and add to themapRolesandmapUsersobject lists. - Commit the file to your git repository
git add eksa-cluster.yaml git commit -m 'Adding IAM Authenticator access ARNs' git push origin main
EKS Anywhere GitOps Controller now updates the role mappings for IAM authenticator in the cluster and users gains access to the cluster.
12 - Manage cluster with GitOps
NOTE: GitOps support is available for vSphere clusters, but is not yet available for Bare Metal clusters
GitOps Support (optional)
EKS Anywhere supports a GitOps workflow for the management of your cluster.
When you create a cluster with GitOps enabled, EKS Anywhere will automatically commit your cluster configuration to the provided GitHub repository and install a GitOps toolkit on your cluster which watches that committed configuration file. You can then manage the scale of the cluster by making changes to the version controlled cluster configuration file and committing the changes. Once a change has been detected by the GitOps controller running in your cluster, the scale of the cluster will be adjusted to match the committed configuration file.
If you’d like to learn more about GitOps, and the associated best practices, check out this introduction from Weaveworks .
NOTE: Installing a GitOps controller can be done during cluster creation or through upgrade. In the event that GitOps installation fails, EKS Anywhere cluster creation will continue.
Supported Cluster Properties
Currently, you can manage a subset of cluster properties with GitOps:
Management Cluster
Cluster:
workerNodeGroupConfigurations.countworkerNodeGroupConfigurations.machineGroupRef.name
WorkerNodes VSphereMachineConfig:
datastorediskGiBfoldermemoryMiBnumCPUsresourcePooltemplateusers
Workload Cluster
Cluster:
kubernetesVersioncontrolPlaneConfiguration.countcontrolPlaneConfiguration.machineGroupRef.nameworkerNodeGroupConfigurations.countworkerNodeGroupConfigurations.machineGroupRef.nameidentityProviderRefs(Only forkind:OIDCConfig,kind:AWSIamConfigis immutable)
ControlPlane / Etcd / WorkerNodes VSphereMachineConfig:
datastorediskGiBfoldermemoryMiBnumCPUsresourcePooltemplateusers
OIDCConfig:
clientIDgroupsClaimgroupsPrefixissuerUrlrequiredClaims.claimrequiredClaims.valueusernameClaimusernamePrefix
Any other changes to the cluster configuration in the git repository will be ignored. If an immutable field has been changed in a Git repository, there are two ways to find the error message:
- If a notification webhook is set up, check the error message in notification channel.
- Check the Flux Kustomization Controller log:
kubectl logs -f -n flux-system kustomize-controller-******for error message containing text similar toInvalid value: 1: field is immutable
Getting Started with EKS Anywhere GitOps with Github
In order to use GitOps to manage cluster scaling, you need a couple of things:
- A GitHub account
- A cluster configuration file with a
GitOpsConfig, referenced with agitOpsRefin your Cluster spec - A Personal Access Token (PAT) for the GitHub account , with permissions to create, clone, and push to a repo
Create a GitHub Personal Access Token
Create a Personal Access Token (PAT)
to access your provided GitHub repository.
It must be scoped for all repo permissions.
NOTE: GitOps configuration only works with hosted github.com and will not work on a self-hosted GitHub Enterprise instances.
This PAT should have at least the following permissions:
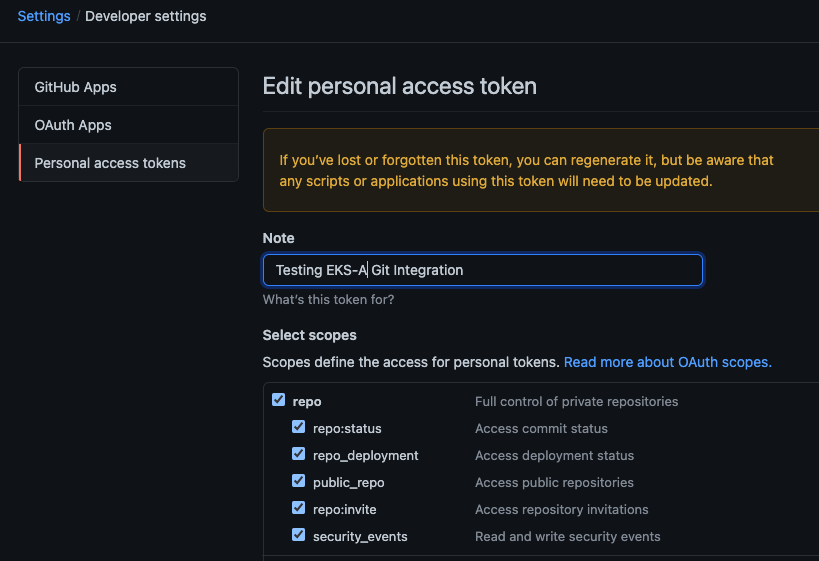
NOTE: The PAT must belong to the
ownerof therepositoryor, if using an organization as theowner, the creator of thePATmust have repo permission in that organization.
You need to set your PAT as the environment variable $EKSA_GITHUB_TOKEN to use it during cluster creation:
export EKSA_GITHUB_TOKEN=ghp_MyValidPersonalAccessTokenWithRepoPermissions
Create GitOps configuration repo
If you have an existing repo you can set that as your repository name in the configuration.
If you specify a repo in your FluxConfig which does not exist EKS Anywhere will create it for you.
If you would like to create a new repo you can click here
to create a new repo.
If your repository contains multiple cluster specification files, store them in sub-folders and specify the configuration path in your cluster specification.
In order to accommodate the management cluster feature, the CLI will now structure the repo directory following a new convention:
clusters
└── management-cluster
├── flux-system
│ └── ...
├── management-cluster
│ └── eksa-system
│ └── eksa-cluster.yaml
│ └── kustomization.yaml
├── workload-cluster-1
│ └── eksa-system
│ └── eksa-cluster.yaml
└── workload-cluster-2
└── eksa-system
└── eksa-cluster.yaml
By default, Flux kustomization reconciles at the management cluster’s root level (./clusters/management-cluster), so both the management cluster and all the workload clusters it manages are synced.
Example GitOps cluster configuration for Github
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: Cluster
metadata:
name: mynewgitopscluster
spec:
... # collapsed cluster spec fields
# Below added for gitops support
gitOpsRef:
kind: FluxConfig
name: my-cluster-name
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: FluxConfig
metadata:
name: my-cluster-name
spec:
github:
personal: true
repository: mygithubrepository
owner: mygithubusername
Create a GitOps enabled cluster
Generate your cluster configuration and add the GitOps configuration. For a full spec reference see the Cluster Spec reference .
NOTE: After your cluster has been created the cluster configuration will automatically be committed to your git repo.
-
Create an EKS Anywhere cluster with GitOps enabled.
CLUSTER_NAME=gitops eksctl anywhere create cluster -f ${CLUSTER_NAME}.yaml
Enable GitOps in an existing cluster
You can also install Flux and enable GitOps in an existing cluster by running the upgrade command with updated cluster configuration. For a full spec reference see the Cluster Spec reference .
-
Upgrade an EKS Anywhere cluster with GitOps enabled.
CLUSTER_NAME=gitops eksctl anywhere upgrade cluster -f ${CLUSTER_NAME}.yaml
Test GitOps controller
After your cluster has been created, you can test the GitOps controller by modifying the cluster specification.
-
Clone your git repo and modify the cluster specification. The default path for the cluster file is:
clusters/$CLUSTER_NAME/eksa-system/eksa-cluster.yaml -
Modify the
workerNodeGroupsConfigurations[0].countfield with your desired changes. -
Commit the file to your git repository
git add eksa-cluster.yaml git commit -m 'Scaling nodes for test' git push origin main -
The Flux controller will automatically make the required changes.
If you updated your node count, you can use this command to see the current node state.
kubectl get nodes
Getting Started with EKS Anywhere GitOps with any Git source
You can configure EKS Anywhere to use a generic git repository as the source of truth for GitOps by providing a FluxConfig with a git configuration.
EKS Anywhere requires a valid SSH Known Hosts file and SSH Private key in order to connect to your repository and bootstrap Flux.
Create a Git repository for use by EKS Anywhere and Flux
When using the git provider, EKS Anywhere requires that the configuration repository be pre-initialized.
You may re-use an existing repo or use the same repo for multiple management clusters.
Create the repository through your git provider and initialize it with a README.md documenting the purpose of the repository.
Create a Private Key for use by EKS Anywhere and Flux
EKS Anywhere requires a private key to authenticate to your git repository, push the cluster configuration, and configure Flux for ongoing management and monitoring of that configuration. The private key should have permissions to read and write from the repository in question.
It is recommended that you create a new private key for use exclusively by EKS Anywhere.
You can use ssh-keygen to generate a new key.
ssh-keygen -t ecdsa -C "my_email@example.com"
Please consult the documentation for your git provider to determine how to add your corresponding public key; for example, if using Github enterprise, you can find the documentation for adding a public key to your github account here .
Add your private key to your SSH agent on your management machine
When using a generic git provider, EKS Anywhere requires that your management machine has a running SSH agent and the private key be added to that SSH agent.
You can start an SSH agent and add your private key by executing the following in your current session:
eval "$(ssh-agent -s)" && ssh-add $EKSA_GIT_PRIVATE_KEY
Create an SSH Known Hosts file for use by EKS Anywhere and Flux
EKS Anywhere needs an SSH known hosts file to verify the identity of the remote git host.
A path to a valid known hosts file must be provided to the EKS Anywhere command line via the environment variable EKSA_GIT_KNOWN_HOSTS.
For example, if you have a known hosts file at /home/myUser/.ssh/known_hosts that you want EKS Anywhere to use, set the environment variable EKSA_GIT_KNOWN_HOSTS to the path to that file, /home/myUser/.ssh/known_hosts.
export EKSA_GIT_KNOWN_HOSTS=/home/myUser/.ssh/known_hosts
While you can use your pre-existing SSH known hosts file, it is recommended that you generate a new known hosts file for use by EKS Anywhere that contains only the known-hosts entries required for your git host and key type.
For example, if you wanted to generate a known hosts file for a git server located at example.com with key type ecdsa, you can use the OpenSSH utility ssh-keyscan:
ssh-keyscan -t ecdsa example.com >> my_eksa_known_hosts
This will generate a known hosts file which contains only the entry necessary to verify the identity of example.com when using an ecdsa based private key file.
Example FluxConfig cluster configuration for a generic git provider
For a full spec reference see the Cluster Spec reference .
NOTE: The
repositoryUrlvalue is of the formatssh://git@provider.com/$REPO_OWNER/$REPO_NAME.git. This may differ from the default SSH URL given by your provider. For Example, the github.com user interface provides an SSH URL containing a:before the repository owner, rather than a/. Make sure to replace this:with a/, if present.
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: Cluster
metadata:
name: mynewgitopscluster
spec:
... # collapsed cluster spec fields
# Below added for gitops support
gitOpsRef:
kind: FluxConfig
name: my-cluster-name
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: FluxConfig
metadata:
name: my-cluster-name
spec:
git:
repositoryUrl: ssh://git@provider.com/myAccount/myClusterGitopsRepo.git
sshKeyAlgorithm: ecdsa
Manage separate workload clusters using Gitops
Follow these steps if you want to use your initial cluster to create and manage separate workload clusters via Gitops.
Prerequisites
-
An existing EKS Anywhere cluster with Gitops enabled. If your existing cluster does not have Gitops installed, see Enable Gitops in an existing cluster. .
-
A cluster configuration file for your new workload cluster.
Create cluster using Gitops
-
Clone your git repo and add the new cluster specification. Be sure to follow the directory structure defined here :
clusters/<management-cluster-name>/$CLUSTER_NAME/eksa-system/eksa-cluster.yamlNOTE: Specify the
namespacefor all EKS Anywhere objects when you are using GitOps to create new workload clusters (even for thedefaultnamespace, usenamespace: defaulton those objects).Ensure workload cluster object names are distinct from management cluster object names. Be sure to set the
managementClusterfield to identify the name of the management cluster.Make sure there is a
kustomization.yamlfile under the namespace directory for the management cluster. Creating a Gitops enabled management cluster witheksctlshould create thekustomization.yamlfile automatically. -
Commit the file to your git repository.
git add clusters/<management-cluster-name>/$CLUSTER_NAME/eksa-system/eksa-cluster.yaml git commit -m 'Creating new workload cluster' git push origin main -
The Flux controller will automatically make the required changes. You can list the workload clusters managed by the management cluster.
export KUBECONFIG=${PWD}/${MGMT_CLUSTER_NAME}/${MGMT_CLUSTER_NAME}-eks-a-cluster.kubeconfig kubectl get clusters -
The kubeconfig for your new cluster is stored as a secret on the management cluster. You can get credentials and run the test application on your new workload cluster as follows:
kubectl get secret -n eksa-system w01-kubeconfig -o jsonpath=‘{.data.value}' | base64 —decode > w01.kubeconfig export KUBECONFIG=w01.kubeconfig kubectl apply -f "https://anywhere.eks.amazonaws.com/manifests/hello-eks-a.yaml"
Upgrade cluster using Gitops
-
To upgrade the cluster using Gitops, modify the workload cluster yaml file with the desired changes.
-
Commit the file to your git repository.
git add eksa-cluster.yaml git commit -m 'Scaling nodes on new workload cluster' git push origin main
Delete cluster using Gitops
- To delete the cluster using Gitops, delete the workload cluster yaml file from your repository and commit those changes.
git rm eksa-cluster.yaml git commit -m 'Deleting workload cluster' git push origin main
13 - Manage cluster with Terraform
NOTE: Support for using Terraform to manage and modify an EKS Anywhere cluster is available for vSphere, Snow and Nutanix clusters, but not yet for Bare Metal or CloudStack clusters.
Using Terraform to manage an EKS Anywhere Cluster (Optional)
This guide explains how you can use Terraform to manage and modify an EKS Anywhere cluster. The guide is meant for illustrative purposes and is not a definitive approach to building production systems with Terraform and EKS Anywhere.
At its heart, EKS Anywhere is a set of Kubernetes CRDs, which define an EKS Anywhere cluster,
and a controller, which moves the cluster state to match these definitions.
These CRDs, and the EKS-A controller, live on the management cluster or
on a self-managed cluster.
We can manage a subset of the fields in the EKS Anywhere CRDs with any tool that can interact with the Kubernetes API, like kubectl or, in this case, the Terraform Kubernetes provider.
In this guide, we’ll show you how to import your EKS Anywhere cluster into Terraform state and how to scale your EKS Anywhere worker nodes using the Terraform Kubernetes provider.
Prerequisites
-
An existing EKS Anywhere cluster
-
the latest version of Terraform
-
the latest version of tfk8s , a tool for converting Kubernetes manifest files to Terraform HCL
Guide
- Create an EKS-A management cluster, or a self-managed stand-alone cluster.
- if you already have an existing EKS-A cluster, skip this step.
- if you don’t already have an existing EKS-A cluster, follow the official instructions to create one
-
Set up the Terraform Kubernetes provider Make sure your KUBECONFIG environment variable is set
export KUBECONFIG=/path/to/my/kubeconfig.kubeconfigSet an environment variable with your cluster name:
export MY_EKSA_CLUSTER="myClusterName"cat << EOF > ./provider.tf provider "kubernetes" { config_path = "${KUBECONFIG}" } EOF -
Get
tfk8sand use it to convert your EKS Anywhere cluster Kubernetes manifest into Terraform HCL:- Install tfk8s
- Convert the manifest into Terraform HCL:
kubectl get cluster ${MY_EKSA_CLUSTER} -o yaml | tfk8s --strip -o ${MY_EKSA_CLUSTER}.tf -
Configure the Terraform cluster resource definition generated in step 2
- Set
metadata.generationas a computed field . Add the following to your cluster resource configuration
computed_fields = ["metadata.generated"]- Configure the field manager to force reconcile managed resources . Add the following configuration block to your cluster resource:
field_manager { force_conflicts = true }- Add the
namespaceto themetadataof the cluster - Remove the
generationfield from themetadataof the cluster - Your Terraform cluster resource should look similar to this:
computed_fields = ["metadata.generated"] field_manager { force_conflicts = true } manifest = { "apiVersion" = "anywhere.eks.amazonaws.com/v1alpha1" "kind" = "Cluster" "metadata" = { "name" = "MyClusterName" "namespace" = "default" } - Set
-
Import your EKS Anywhere cluster into terraform state:
terraform init terraform import kubernetes_manifest.cluster_${MY_EKSA_CLUSTER} "apiVersion=anywhere.eks.amazonaws.com/v1alpha1,kind=Cluster,namespace=default,name=${MY_EKSA_CLUSTER}"After you
importyour cluster, you will need to runterraform applyone time to ensure that themanifestfield of your cluster resource is in-sync. This will not change the state of your cluster, but is a required step after the initial import. Themanifestfield stores the contents of the associated kubernetes manifest, while theobjectfield stores the actual state of the resource. -
Modify Your Cluster using Terraform
- Modify the
countvalue of one of yourworkerNodeGroupConfigurations, or another mutable field, in the configuration stored in${MY_EKSA_CLUSTER}.tffile. - Check the expected diff between your cluster state and the modified local state via
terraform plan
You should see in the output that the worker node group configuration count field (or whichever field you chose to modify) will be modified by Terraform.
- Modify the
-
Now, actually change your cluster to match the local configuration:
terraform apply -
Observe the change to your cluster. For example:
kubectl get nodes
Manage separate workload clusters using Terraform
Follow these steps if you want to use your initial cluster to create and manage separate workload clusters via Terraform.
NOTE: If you choose to manage your cluster using Terraform, do not use
kubectlto edit your cluster objects as this can lead to field manager conflicts.
Prerequisites
- An existing EKS Anywhere cluster imported into Terraform state. If your existing cluster is not yet imported, see this guide. .
- A cluster configuration file for your new workload cluster.
Create cluster using Terraform
-
Create the new cluster configuration Terraform file.
tfk8s -f new-workload-cluster.yaml -o new-workload-cluster.tfNOTE: Specify the
namespacefor all EKS Anywhere objects when you are using Terraform to manage your clusters (even for thedefaultnamespace, use"namespace" = "default"on those objects).Ensure workload cluster object names are distinct from management cluster object names. Be sure to set the
managementClusterfield to identify the name of the management cluster. -
Ensure that this new Terraform workload cluster configuration exists in the same directory as the management cluster Terraform files.
my/terraform/config/path ├── management-cluster.tf ├── new-workload-cluster.tf ├── provider.tf ├── ... └── -
Verify the changes to be applied:
terraform plan -
If the plan looks as expected, apply those changes to create the new cluster resources:
terraform apply -
You can list the workload clusters managed by the management cluster.
export KUBECONFIG=${PWD}/${MGMT_CLUSTER_NAME}/${MGMT_CLUSTER_NAME}-eks-a-cluster.kubeconfig kubectl get clusters -
The kubeconfig for your new cluster is stored as a secret on the management cluster. You can get the workload cluster credentials and run the test application on your new workload cluster as follows:
kubectl get secret -n eksa-system w01-kubeconfig -o jsonpath=‘{.data.value}' | base64 --decode > w01.kubeconfig export KUBECONFIG=w01.kubeconfig kubectl apply -f "https://anywhere.eks.amazonaws.com/manifests/hello-eks-a.yaml"
Upgrade cluster using Terraform
- To upgrade a workload cluster using Terraform, modify the desired fields in the Terraform resource file and apply the changes.
terraform apply
Delete cluster using Terraform
- To delete a workload cluster using Terraform, you will need the name of the Terraform cluster resource.
This can be found on the first line of your cluster resource definition.
terraform destroy --target kubernetes_manifest.cluster_w01
Appendix
Terraform K8s Provider https://registry.terraform.io/providers/hashicorp/kubernetes/latest/docs
14 - Delete cluster
NOTE: EKS Anywhere Bare Metal clusters do not yet support separate workload and management clusters. Use the instructions for Deleting a management cluster to delete a Bare Metal cluster.
Deleting a workload cluster
Follow these steps to delete your EKS Anywhere cluster that is managed by a separate management cluster.
To delete a workload cluster, you will need:
- name of your workload cluster
- kubeconfig of your workload cluster
- kubeconfig of your management cluster
Run the following commands to delete the cluster:
-
Set up
CLUSTER_NAMEandKUBECONFIGenvironment variables:export CLUSTER_NAME=eksa-w01-cluster export KUBECONFIG=${CLUSTER_NAME}/${CLUSTER_NAME}-eks-a-cluster.kubeconfig export MANAGEMENT_KUBECONFIG=<path-to-management-cluster-kubeconfig> -
Run the delete command:
-
If you are running the delete command from the directory which has the cluster folder with
${CLUSTER_NAME}/${CLUSTER_NAME}-eks-a-cluster.yaml:eksctl anywhere delete cluster ${CLUSTER_NAME} --kubeconfig ${MANAGEMENT_KUBECONFIG}
Deleting a management cluster
Follow these steps to delete your management cluster.
To delete a cluster you will need:
- cluster name or cluster configuration
- kubeconfig of your cluster
Run the following commands to delete the cluster:
-
Set up
CLUSTER_NAMEandKUBECONFIGenvironment variables:export CLUSTER_NAME=mgmt export KUBECONFIG=${CLUSTER_NAME}/${CLUSTER_NAME}-eks-a-cluster.kubeconfig -
Run the delete command:
-
If you are running the delete command from the directory which has the cluster folder with
${CLUSTER_NAME}/${CLUSTER_NAME}-eks-a-cluster.yaml:eksctl anywhere delete cluster ${CLUSTER_NAME} -
Otherwise, use this command to manually specify the clusterconfig file path:
export CONFIG_FILE=<path-to-config-file> eksctl anywhere delete cluster -f ${CONFIG_FILE}
Example output:
Performing provider setup and validations
Creating management cluster
Installing cluster-api providers on management cluster
Moving cluster management from workload cluster
Deleting workload cluster
Clean up Git Repo
GitOps field not specified, clean up git repo skipped
🎉 Cluster deleted!
For vSphere, CloudStack, and Nutanix, this will delete all of the VMs that were created in your provider. For Bare Metal, the servers will be powered off if BMC information has been provided. If your workloads created external resources such as external DNS entries or load balancer endpoints you may need to delete those resources manually.