This is the multi-page printable view of this section. Click here to print.
Reference
- 1: Config
- 1.1: Bare metal configuration
- 1.2: Nutanix configuration
- 1.3: Snow configuration
- 1.4: vSphere configuration
- 1.5: CloudStack configuration
- 1.6: Optional configuration
- 1.6.1: Autoscaling configuration
- 1.6.2: CNI plugin configuration
- 1.6.3: IAM Roles for Service Accounts configuration
- 1.6.4: etcd configuration
- 1.6.5: AWS IAM Authenticator configuration
- 1.6.6: OIDC configuration
- 1.6.7: GitOpsConfig configuration
- 1.6.8: Proxy configuration
- 1.6.9: Registry Mirror configuration
- 1.6.10: Package controller configuration
- 2: Bare Metal
- 2.1: Requirements for EKS Anywhere on Bare Metal
- 2.2: Preparing Bare Metal for EKS Anywhere
- 2.3: Netbooting and Tinkerbell for Bare Metal
- 2.4: Customize HookOS for EKS Anywhere on Bare Metal
- 3: CloudStack
- 4: Nutanix
- 4.1: Requirements for EKS Anywhere on Nutanix Cloud Infrastructure
- 4.2: Preparing Nutanix Cloud Infrastructure for EKS Anywhere
- 4.3:
- 5: VMware vSphere
- 5.1: Requirements for EKS Anywhere on VMware vSphere
- 5.2: Preparing vSphere for EKS Anywhere
- 5.3: Customize OVAs: Ubuntu
- 5.4: Import OVAs
- 5.5: Custom DHCP Configuration
- 5.6:
- 6: Security best practices
- 7: Packages
- 7.1: Packages configuration
- 7.2: Configuration Best Practice
- 7.3: ADOT Configuration
- 7.4: Cert-Manager Configuration
- 7.4.1: v1.9.1
- 7.5: Cluster Autoscaler Configuration
- 7.5.1: v9.21.0
- 7.6: Emissary Configuration
- 7.7: Harbor configuration
- 7.8: MetalLB Configuration
- 7.9: Metrics Server Configuration
- 7.9.1: v3.8.2
- 7.10: Prometheus Configuration
- 8: What's New?
- 9: Frequently Asked Questions
- 10: Troubleshooting
- 11: Support
- 11.1: Support scope
- 11.2: Version support
- 12: Artifacts
- 13: Ports and protocols
- 14: Release Alerts
- 15: eksctl anywhere CLI reference
- 15.1: anywhere
- 15.2: anywhere apply
- 15.3: anywhere apply package(s)
- 15.4: anywhere check-images
- 15.5: anywhere copy
- 15.6: anywhere copy packages
- 15.7: anywhere create
- 15.8: anywhere create cluster
- 15.9: anywhere create package(s)
- 15.10: anywhere delete
- 15.11: anywhere delete cluster
- 15.12: anywhere delete package(s)
- 15.13: anywhere describe
- 15.14: anywhere describe package(s)
- 15.15: anywhere download
- 15.16: anywhere download artifacts
- 15.17: anywhere download images
- 15.18: anywhere exp
- 15.19: anywhere exp validate
- 15.20: anywhere exp validate create
- 15.21: anywhere exp validate create cluster
- 15.22: anywhere exp vsphere
- 15.23: anywhere exp vsphere setup
- 15.24: anywhere exp vsphere setup user
- 15.25: anywhere generate
- 15.26: anywhere generate clusterconfig
- 15.27: anywhere generate hardware
- 15.28: anywhere generate packages
- 15.29: anywhere generate support-bundle
- 15.30: anywhere generate support-bundle-config
- 15.31: anywhere get
- 15.32: anywhere get package(s)
- 15.33: anywhere get packagebundle(s)
- 15.34: anywhere get packagebundlecontroller(s)
- 15.35: anywhere import
- 15.36: anywhere import images
- 15.37: anywhere install
- 15.38: anywhere install package
- 15.39: anywhere install packagecontroller
- 15.40: anywhere list
- 15.41: anywhere list images
- 15.42: anywhere list ovas
- 15.43: anywhere list packages
- 15.44: anywhere upgrade
- 15.45: anywhere upgrade cluster
- 15.46: anywhere upgrade packages
- 15.47: anywhere upgrade plan
- 15.48: anywhere upgrade plan cluster
- 15.49: anywhere version
1 - Config
1.1 - Bare metal configuration
This is a generic template with detailed descriptions below for reference. The following additional optional configuration can also be included:
To generate your own cluster configuration, follow instructions from the Bare Metal Create production cluster section and modify it using descriptions below. For information on how to add cluster configuration settings to this file for advanced node configuration, see Advanced Bare Metal cluster configuration .
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: Cluster
metadata:
name: my-cluster-name
spec:
clusterNetwork:
cniConfig:
cilium: {}
pods:
cidrBlocks:
- 192.168.0.0/16
services:
cidrBlocks:
- 10.96.0.0/12
controlPlaneConfiguration:
count: 1
endpoint:
host: "<Control Plane Endpoint IP>"
machineGroupRef:
kind: TinkerbellMachineConfig
name: my-cluster-name-cp
datacenterRef:
kind: TinkerbellDatacenterConfig
name: my-cluster-name
kubernetesVersion: "1.25"
managementCluster:
name: my-cluster-name
workerNodeGroupConfigurations:
- count: 1
machineGroupRef:
kind: TinkerbellMachineConfig
name: my-cluster-name
name: md-0
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: TinkerbellDatacenterConfig
metadata:
name: my-cluster-name
spec:
tinkerbellIP: "<Tinkerbell IP>"
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: TinkerbellMachineConfig
metadata:
name: my-cluster-name-cp
spec:
hardwareSelector: {}
osFamily: bottlerocket
templateRef: {}
users:
- name: ec2-user
sshAuthorizedKeys:
- ssh-rsa AAAAB3NzaC1yc2... jwjones@833efcab1482.home.example.com
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: TinkerbellMachineConfig
metadata:
name: my-cluster-name
spec:
hardwareSelector: {}
osFamily: bottlerocket
templateRef:
kind: TinkerbellTemplateConfig
name: my-cluster-name
users:
- name: ec2-user
sshAuthorizedKeys:
- ssh-rsa AAAAB3NzaC1yc2... jwjones@833efcab1482.home.example.com
Cluster Fields
name (required)
Name of your cluster (my-cluster-name in this example).
clusterNetwork (required)
Specific network configuration for your Kubernetes cluster.
clusterNetwork.cniConfig (required)
CNI plugin to be installed in the cluster. The only supported value at the moment is cilium.
clusterNetwork.pods.cidrBlocks[0] (required)
Subnet used by pods in CIDR notation. Please note that only 1 custom pods CIDR block specification is permitted.
This CIDR block should not conflict with the clusterNetwork.services.cidrBlocks and network subnet range selected for the machines.
clusterNetwork.services.cidrBlocks[0] (required)
Subnet used by services in CIDR notation. Please note that only 1 custom services CIDR block specification is permitted.
This CIDR block should not conflict with the clusterNetwork.pods.cidrBlocks and network subnet range selected for the machines.
clusterNetwork.dns.resolvConf.path (optional)
Path to the file with a custom DNS resolver configuration.
controlPlaneConfiguration (required)
Specific control plane configuration for your Kubernetes cluster.
controlPlaneConfiguration.count (required)
Number of control plane nodes. This number needs to be odd to maintain ETCD quorum.
controlPlaneConfiguration.endpoint.host (required)
A unique IP you want to use for the control plane in your EKS Anywhere cluster. Choose an IP in your network range that does not conflict with other machines.
NOTE: This IP should be outside the network DHCP range as it is a floating IP that gets assigned to one of the control plane nodes for kube-apiserver loadbalancing.
controlPlaneConfiguration.machineGroupRef (required)
Refers to the Kubernetes object with Tinkerbell-specific configuration for your nodes. See TinkerbellMachineConfig Fields below.
controlPlaneConfiguration.taints
A list of taints to apply to the control plane nodes of the cluster.
Replaces the default control plane taint (For k8s versions prior to 1.24, node-role.kubernetes.io/master. For k8s versions 1.24+, node-role.kubernetes.io/control-plane). The default control plane components will tolerate the provided taints.
Modifying the taints associated with the control plane configuration will cause new nodes to be rolled-out, replacing the existing nodes.
NOTE: The taints provided will be used instead of the default control plane taint. Any pods that you run on the control plane nodes must tolerate the taints you provide in the control plane configuration.
controlPlaneConfiguration.labels
A list of labels to apply to the control plane nodes of the cluster. This is in addition to the labels that EKS Anywhere will add by default.
Modifying the labels associated with the control plane configuration will cause new nodes to be rolled out, replacing the existing nodes.
datacenterRef
Refers to the Kubernetes object with Tinkerbell-specific configuration. See TinkerbellDatacenterConfig Fields below.
kubernetesVersion (required)
The Kubernetes version you want to use for your cluster. Supported values: 1.25, 1.24, 1.23, 1.22, 1.21
managementCluster
Identifies the name of the management cluster. If this is a standalone cluster or if it were serving as the management cluster for other workload clusters, this will be the same as the cluster name. Bare Metal EKS Anywhere clusters do not yet support the creation of separate workload clusters.
workerNodeGroupConfigurations
This takes in a list of node groups that you can define for your workers.
You can omit workerNodeGroupConfigurations when creating Bare Metal clusters. In this case, control plane nodes will not be tainted and all pods will run on the control plane nodes. This mechanism can be used to deploy Bare Metal clusters on a single server.
NOTE: Empty workerNodeGroupConfigurations is not supported when Kubernetes version <= 1.21.
workerNodeGroupConfigurations.count
Number of worker nodes. Optional if autoscalingConfiguration is used, in which case count will default to autoscalingConfiguration.minCount.
workerNodeGroupConfigurations.machineGroupRef (required)
Refers to the Kubernetes object with Tinkerbell-specific configuration for your nodes. See TinkerbellMachineConfig Fields below.
workerNodeGroupConfigurations.name (required)
Name of the worker node group (default: md-0)
workerNodeGroupConfigurations.autoscalingConfiguration.minCount
Minimum number of nodes for this node group’s autoscaling configuration.
workerNodeGroupConfigurations.autoscalingConfiguration.maxCount
Maximum number of nodes for this node group’s autoscaling configuration.
workerNodeGroupConfigurations.taints
A list of taints to apply to the nodes in the worker node group.
Modifying the taints associated with a worker node group configuration will cause new nodes to be rolled-out, replacing the existing nodes associated with the configuration.
At least one node group must not have NoSchedule or NoExecute taints applied to it.
workerNodeGroupConfigurations.labels
A list of labels to apply to the nodes in the worker node group. This is in addition to the labels that EKS Anywhere will add by default.
Modifying the labels associated with a worker node group configuration will cause new nodes to be rolled out, replacing the existing nodes associated with the configuration.
TinkerbellDatacenterConfig Fields
tinkerbellIP
Required field to identify the IP address of the Tinkerbell service. This IP address must be a unique IP in the network range that does not conflict with other IPs. Once the Tinkerbell services move from the Admin machine to run on the target cluster, this IP address makes it possible for the stack to be used for future provisioning needs. When separate management and workload clusters are supported in Bare Metal, the IP address becomes a necessity.
osImageURL
Optional field to replace the default Bottlerocket operating system. EKS Anywhere can only auto-import Bottlerocket. In order to use Ubuntu or Redhat see building baremetal node images to learn more on building and using Ubuntu with an EKS Anywhere cluster. This field is also useful if you want to provide a customized operating system image or simply host the standard image locally.
hookImagesURLPath
Optional field to replace the HookOS image. This field is useful if you want to provide a customized HookOS image or simply host the standard image locally. See Artifacts for details.
Example TinkerbellDatacenterConfig.spec
spec:
tinkerbellIP: "192.168.0.10" # Available, routable IP
osImageURL: "http://my-web-server/ubuntu-v1.23.7-eks-a-12-amd64.gz" # Full URL to the OS Image hosted locally
hookImagesURLPath: "http://my-web-server/hook" # Path to the hook images. This path must contain vmlinuz-x86_64 and initramfs-x86_64
This is the folder structure for my-web-server:
my-web-server
├── hook
│ ├── initramfs-x86_64
│ └── vmlinuz-x86_64
└── ubuntu-v1.23.7-eks-a-12-amd64.gz
skipLoadBalancerDeployment
Optional field to skip deploying the default load balancer for Tinkerbell stack.
EKS Anywhere for Bare Metal uses kube-vip load balancer by default to expose the Tinkerbell stack externally.
You can disable this feature by setting this field to true.
NOTE: If you skip load balancer deployment, you will have to ensure that the Tinkerbell stack is available at tinkerbellIP once the cluster creation is finished. One way to achieve this is by using the MetalLB package.
TinkerbellMachineConfig Fields
In the example, there are TinkerbellMachineConfig sections for control plane (my-cluster-name-cp) and worker (my-cluster-name) machine groups.
The following fields identify information needed to configure the nodes in each of those groups.
NOTE: Currently, you can only have one machine group for all machines in the control plane, although you can have multiple machine groups for the workers.
hardwareSelector
Use fields under hardwareSelector to add key/value pair labels to match particular machines that you identified in the CSV file where you defined the machines in your cluster.
Choose any label name you like.
For example, if you had added the label node=cp-machine to the machines listed in your CSV file that you want to be control plane nodes, the following hardwareSelector field would cause those machines to be added to the control plane:
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: TinkerbellMachineConfig
metadata:
name: my-cluster-name-cp
spec:
hardwareSelector:
node: "cp-machine"
osFamily (required)
Operating system on the machine. For example, bottlerocket or ubuntu.
templateRef (optional)
Identifies the template that defines the actions that will be applied to the TinkerbellMachineConfig.
See TinkerbellTemplateConfig fields below.
EKS Anywhere will generate default templates based on osFamily during the create command.
You can override this default template by providing your own template here.
users
The name of the user you want to configure to access your virtual machines through SSH.
The default is ec2-user.
Currently, only one user is supported.
users[0].sshAuthorizedKeys (optional)
The SSH public keys you want to configure to access your machines through SSH (as described below). Only 1 is supported at this time.
users[0].sshAuthorizedKeys[0] (optional)
This is the SSH public key that will be placed in authorized_keys on all EKS Anywhere cluster machines so you can SSH into
them. The user will be what is defined under name above. For example:
ssh -i <private-key-file> <user>@<machine-IP>
The default is generating a key in your $(pwd)/<cluster-name> folder when not specifying a value.
Advanced Bare Metal cluster configuration
When you generate a Bare Metal cluster configuration, the TinkerbellTemplateConfig is kept internally and not shown in the generated configuration file.
TinkerbellTemplateConfig settings define the actions done to install each node, such as get installation media, configure networking, add users, and otherwise configure the node.
Advanced users can override the default values set for TinkerbellTemplateConfig.
They can also add their own Tinkerbell actions
to make personalized modifications to EKS Anywhere nodes.
The following shows two TinkerbellTemplateConfig examples that you can add to your cluster configuration file to override the values that EKS Anywhere sets: one for Ubuntu and one for Bottlerocket.
Most actions used differ for different operating systems.
NOTE: For the
stream-imageaction,DEST_DISKpoints to the device representing the entire hard disk (for example,/dev/sda). For UEFI-enabled images, such as Ubuntu, write actions useDEST_DISKto point to the second partition (for example,/dev/sda2), with the first being the EFI partition. For the Bottlerocket image, which has 12 partitions,DEST_DISKis partition 12 (for example,/dev/sda12). Device names will be different for different disk types.
Ubuntu TinkerbellTemplateConfig example
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: TinkerbellTemplateConfig
metadata:
name: my-cluster-name
spec:
template:
global_timeout: 6000
id: ""
name: my-cluster-name
tasks:
- actions:
- environment:
COMPRESSED: "true"
DEST_DISK: /dev/sda
IMG_URL: https://my-file-server/ubuntu-v1.23.7-eks-a-12-amd64.gz
image: public.ecr.aws/eks-anywhere/tinkerbell/hub/image2disk:6c0f0d437bde2c836d90b000312c8b25fa1b65e1-eks-a-15
name: stream-image
timeout: 360
- environment:
DEST_DISK: /dev/sda2
DEST_PATH: /etc/netplan/config.yaml
STATIC_NETPLAN: true
DIRMODE: "0755"
FS_TYPE: ext4
GID: "0"
MODE: "0644"
UID: "0"
image: public.ecr.aws/eks-anywhere/tinkerbell/hub/writefile:6c0f0d437bde2c836d90b000312c8b25fa1b65e1-eks-a-15
name: write-netplan
timeout: 90
- environment:
CONTENTS: |
datasource:
Ec2:
metadata_urls: [<admin-machine-ip>, <tinkerbell-ip-from-cluster-config>]
strict_id: false
manage_etc_hosts: localhost
warnings:
dsid_missing_source: off
DEST_DISK: /dev/sda2
DEST_PATH: /etc/cloud/cloud.cfg.d/10_tinkerbell.cfg
DIRMODE: "0700"
FS_TYPE: ext4
GID: "0"
MODE: "0600"
UID: "0"
image: public.ecr.aws/eks-anywhere/tinkerbell/hub/writefile:6c0f0d437bde2c836d90b000312c8b25fa1b65e1-eks-a-15
name: add-tink-cloud-init-config
timeout: 90
- environment:
CONTENTS: |
network:
config: disabled
DEST_DISK: /dev/sda2
DEST_PATH: /etc/cloud/cloud.cfg.d/99-disable-network-config.cfg
DIRMODE: "0700"
FS_TYPE: ext4
GID: "0"
MODE: "0600"
UID: "0"
image: public.ecr.aws/eks-anywhere/tinkerbell/hub/writefile:6c0f0d437bde2c836d90b000312c8b25fa1b65e1-eks-a-15
name: disable-cloud-init-network-capabilities
timeout: 90
- environment:
CONTENTS: |
datasource: Ec2
DEST_DISK: /dev/sda2
DEST_PATH: /etc/cloud/ds-identify.cfg
DIRMODE: "0700"
FS_TYPE: ext4
GID: "0"
MODE: "0600"
UID: "0"
image: public.ecr.aws/eks-anywhere/tinkerbell/hub/writefile:6c0f0d437bde2c836d90b000312c8b25fa1b65e1-eks-a-15
name: add-tink-cloud-init-ds-config
timeout: 90
- environment:
BLOCK_DEVICE: /dev/sda2
FS_TYPE: ext4
image: public.ecr.aws/eks-anywhere/tinkerbell/hub/kexec:6c0f0d437bde2c836d90b000312c8b25fa1b65e1-eks-a-15
name: kexec-image
pid: host
timeout: 90
name: my-cluster-name
volumes:
- /dev:/dev
- /dev/console:/dev/console
- /lib/firmware:/lib/firmware:ro
worker: '{{.device_1}}'
version: "0.1"
Bottlerocket TinkerbellTemplateConfig example
Pay special attention to the BOOTCONFIG_CONTENTS environment section below if you wish to set up console redirection for the kernel and systemd.
If you are only using a direct attached monitor as your primary display device, no additional configuration is needed here.
However, if you need all boot output to be shown via a server’s serial console for example, extra configuration should be provided inside BOOTCONFIG_CONTENTS.
An empty kernel {} key is provided below in the example; inside this key is where you will specify your console devices.
You may specify multiple comma delimited console devices in quotes to a console key as such: console = "tty0", "ttyS0,115200n8".
The order of the devices is significant; systemd will output to the last device specified.
The console key belongs inside the kernel key like so:
kernel {
console = "tty0", "ttyS0,115200n8"
}
The above example will send all kernel output to both consoles, and systemd output to ttyS0.
Additional information about serial console setup can be found in the Linux kernel documentation
.
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: TinkerbellTemplateConfig
metadata:
name: my-cluster-name
spec:
template:
global_timeout: 6000
id: ""
name: my-cluster-name
tasks:
- actions:
- environment:
COMPRESSED: "true"
DEST_DISK: /dev/sda
IMG_URL: https://anywhere-assets.eks.amazonaws.com/releases/bundles/11/artifacts/raw/1-22/bottlerocket-v1.22.10-eks-d-1-22-8-eks-a-11-amd64.img.gz
image: public.ecr.aws/eks-anywhere/tinkerbell/hub/image2disk:6c0f0d437bde2c836d90b000312c8b25fa1b65e1-eks-a-15
name: stream-image
timeout: 360
- environment:
# An example console declaration that will send all kernel output to both consoles, and systemd output to ttyS0.
# kernel {
# console = "tty0", "ttyS0,115200n8"
# }
BOOTCONFIG_CONTENTS: |
kernel {}
DEST_DISK: /dev/sda12
DEST_PATH: /bootconfig.data
DIRMODE: "0700"
FS_TYPE: ext4
GID: "0"
MODE: "0644"
UID: "0"
image: public.ecr.aws/eks-anywhere/tinkerbell/hub/writefile:6c0f0d437bde2c836d90b000312c8b25fa1b65e1-eks-a-15
name: write-bootconfig
timeout: 90
- environment:
CONTENTS: |
# Version is required, it will change as we support
# additional settings
version = 1
# "eno1" is the interface name
# Users may turn on dhcp4 and dhcp6 via boolean
[eno1]
dhcp4 = true
# Define this interface as the "primary" interface
# for the system. This IP is what kubelet will use
# as the node IP. If none of the interfaces has
# "primary" set, we choose the first interface in
# the file
primary = true
DEST_DISK: /dev/sda12
DEST_PATH: /net.toml
DIRMODE: "0700"
FS_TYPE: ext4
GID: "0"
MODE: "0644"
UID: "0"
image: public.ecr.aws/eks-anywhere/tinkerbell/hub/writefile:6c0f0d437bde2c836d90b000312c8b25fa1b65e1-eks-a-15
name: write-netconfig
timeout: 90
- environment:
HEGEL_URL: http://<hegel-ip>:50061
DEST_DISK: /dev/sda12
DEST_PATH: /user-data.toml
DIRMODE: "0700"
FS_TYPE: ext4
GID: "0"
MODE: "0644"
UID: "0"
image: public.ecr.aws/eks-anywhere/tinkerbell/hub/writefile:6c0f0d437bde2c836d90b000312c8b25fa1b65e1-eks-a-15
name: write-user-data
timeout: 90
- name: "reboot"
image: public.ecr.aws/eks-anywhere/tinkerbell/hub/reboot:6c0f0d437bde2c836d90b000312c8b25fa1b65e1-eks-a-15
timeout: 90
volumes:
- /worker:/worker
name: my-cluster-name
volumes:
- /dev:/dev
- /dev/console:/dev/console
- /lib/firmware:/lib/firmware:ro
worker: '{{.device_1}}'
version: "0.1"
TinkerbellTemplateConfig Fields
The values in the TinkerbellTemplateConfig fields are created from the contents of the CSV file used to generate a configuration.
The template contains actions that are performed on a Bare Metal machine when it first boots up to be provisioned.
For advanced users, you can add these fields to your cluster configuration file if you have special needs to do so.
While there are fields that apply to all provisioned operating systems, actions are specific to each operating system. Examples below describe actions for Ubuntu and Bottlerocket operating systems.
template.global_timeout
Sets the timeout value for completing the configuration. Set to 6000 (100 minutes) by default.
template.id
Not set by default.
template.tasks
Within the TinkerbellTemplateConfig template under tasks is a set of actions.
The following descriptions cover the actions shown in the example templates for Ubuntu and Bottlerocket:
template.tasks.actions.name.stream-image (Ubuntu and Bottlerocket)
The stream-image action streams the selected image to the machine you are provisioning. It identifies:
- environment.COMPRESSED: When set to
true, Tinkerbell expectsIMG_URLto be a compressed image, which Tinkerbell will uncompress when it writes the contents to disk. - environment.DEST_DISK: The hard disk on which the operating system is deployed. The default is the first SCSI disk (/dev/sda), but can be changed for other disk types.
- environment.IMG_URL: The operating system tarball (ubuntu or other) to stream to the machine you are configuring.
- image: Container image needed to perform the steps needed by this action.
- timeout: Sets the amount of time (in seconds) that Tinkerbell has to stream the image, uncompress it, and write it to disk before timing out. Consider increasing this limit from the default 600 to a higher limit if this action is timing out.
Ubuntu-specific actions
template.tasks.actions.name.write-netplan (Ubuntu)
The write-netplan action writes Ubuntu network configuration information to the machine (see Netplan
) for details. It identifies:
- environment.CONTENTS.network.version: Identifies the network version.
- environment.CONTENTS.network.renderer: Defines the service to manage networking. By default, the
networkdsystemd service is used. - environment.CONTENTS.network.ethernets: Network interface to external network (eno1, by default) and whether or not to use dhcp4 (true, by default).
- environment.DEST_DISK: Destination block storage device partition where the operating system is copied. By default, /dev/sda2 is used (sda1 is the EFI partition).
- environment.DEST_PATH: File where the networking configuration is written (/etc/netplan/config.yaml, by default).
- environment.DIRMODE: Linux directory permissions bits to use when creating directories (0755, by default)
- environment.FS_TYPE: Type of filesystem on the partition (ext4, by default).
- environment.GID: The Linux group ID to set on file. Set to 0 (root group) by default.
- environment.MODE: The Linux permission bits to set on file (0644, by default).
- environment.UID: The Linux user ID to set on file. Set to 0 (root user) by default.
- image: Container image used to perform the steps needed by this action.
- timeout: Time needed to complete the action, in seconds.
template.tasks.actions.add-tink-cloud-init-config (Ubuntu)
The add-tink-cloud-init-config action configures cloud-init features to further configure the operating system. See cloud-init Documentation
for details. It identifies:
- environment.CONTENTS.datasource: Identifies Ec2 (Ec2.metadata_urls) as the data source and sets
Ec2.strict_id: falseto prevent cloud-init from producing warnings about this datasource. - environment.CONTENTS.system_info: Creates the
tinkuser and gives it administrative group privileges (wheel, adm) and passwordless sudo privileges, and set the default shell (/bin/bash). - environment.CONTENTS.manage_etc_hosts: Updates the system’s
/etc/hostsfile with the hostname. Set tolocalhostby default. - environment.CONTENTS.warnings: Sets dsid_missing_source to
off. - environment.DEST_DISK: Destination block storage device partition where the operating system is located (
/dev/sda2, by default). - environment.DEST_PATH: Location of the cloud-init configuration file on disk (
/etc/cloud/cloud.cfg.d/10_tinkerbell.cfg, by default) - environment.DIRMODE: Linux directory permissions bits to use when creating directories (0700, by default)
- environment.FS_TYPE: Type of filesystem on the partition (ext4, by default).
- environment.GID: The Linux group ID to set on file. Set to 0 (root group) by default.
- environment.MODE: The Linux permission bits to set on file (0600, by default).
- environment.UID: The Linux user ID to set on file. Set to 0 (root user) by default.
- image: Container image used to perform the steps needed by this action.
- timeout: Time needed to complete the action, in seconds.
template.tasks.actions.add-tink-cloud-init-ds-config (Ubuntu)
The add-tink-cloud-init-ds-config action configures cloud-init data store features. This identifies the location of your metadata source once the machine is up and running. It identifies:
- environment.CONTENTS.datasource: Sets the datasource. Uses Ec2, by default.
- environment.DEST_DISK: Destination block storage device partition where the operating system is located (/dev/sda2, by default).
- environment.DEST_PATH: Location of the data store identity configuration file on disk (/etc/cloud/ds-identify.cfg, by default)
- environment.DIRMODE: Linux directory permissions bits to use when creating directories (0700, by default)
- environment.FS_TYPE: Type of filesystem on the partition (ext4, by default).
- environment.GID: The Linux group ID to set on file. Set to 0 (root group) by default.
- environment.MODE: The Linux permission bits to set on file (0600, by default).
- environment.UID: The Linux user ID to set on file. Set to 0 (root user) by default.
- image: Container image used to perform the steps needed by this action.
- timeout: Time needed to complete the action, in seconds.
template.tasks.actions.kexec-image (Ubuntu)
The kexec-image action performs provisioning activities on the machine, then allows kexec to pivot the kernel to use the system installed on disk. This action identifies:
- environment.BLOCK_DEVICE: Disk partition on which the operating system is installed (/dev/sda2, by default)
- environment.FS_TYPE: Type of filesystem on the partition (ext4, by default).
- image: Container image used to perform the steps needed by this action.
- pid: Process ID. Set to host, by default.
- timeout: Time needed to complete the action, in seconds.
- volumes: Identifies mount points that need to be remounted to point to locations in the installed system.
There are known issues related to drivers with some hardware that may make it necessary to replace the kexec-image action with a full reboot. If you require a full reboot, you can change the kexec-image setting as follows:
actions:
- name: "reboot"
image: public.ecr.aws/l0g8r8j6/tinkerbell/hub/reboot-action:latest
timeout: 90
volumes:
- /worker:/worker
Bottlerocket-specific actions
template.tasks.actions.write-bootconfig (Bottlerocket)
The write-bootconfig action identifies the location on the machine to put content needed to boot the system from disk.
- environment.BOOTCONFIG_CONTENTS.kernel: Add kernel parameters that are passed to the kernel when the system boots.
- environment.DEST_DISK: Identifies the block storage device that holds the boot partition.
- environment.DEST_PATH: Identifies the file holding boot configuration data (
/bootconfig.datain this example). - environment.DIRMODE: The Linux permissions assigned to the boot directory.
- environment.FS_TYPE: The filesystem type associated with the boot partition.
- environment.GID: The group ID associated with files and directories created on the boot partition.
- environment.MODE: The Linux permissions assigned to files in the boot partition.
- environment.UID: The user ID associated with files and directories created on the boot partition. UID 0 is the root user.
- image: Container image used to perform the steps needed by this action.
- timeout: Time needed to complete the action, in seconds.
template.tasks.actions.write-netconfig (Bottlerocket)
The write-netconfig action configures networking for the system.
- environment.CONTENTS: Add network values, including:
version = 1(version number),[eno1](external network interface),dhcp4 = true(turns on dhcp4), andprimary = true(identifies this interface as the primary interface used by kubelet). - environment.DEST_DISK: Identifies the block storage device that holds the network configuration information.
- environment.DEST_PATH: Identifies the file holding network configuration data (
/net.tomlin this example). - environment.DIRMODE: The Linux permissions assigned to the directory holding network configuration settings.
- environment.FS_TYPE: The filesystem type associated with the partition holding network configuration settings.
- environment.GID: The group ID associated with files and directories created on the partition. GID 0 is the root group.
- environment.MODE: The Linux permissions assigned to files in the partition.
- environment.UID: The user ID associated with files and directories created on the partition. UID 0 is the root user.
- image: Container image used to perform the steps needed by this action.
template.tasks.actions.write-user-data (Bottlerocket)
The write-user-data action configures the Tinkerbell Hegel service, which provides the metadata store for Tinkerbell.
- environment.HEGEL_URL: The IP address and port number of the Tinkerbell Hegel service.
- environment.DEST_DISK: Identifies the block storage device that holds the network configuration information.
- environment.DEST_PATH: Identifies the file holding network configuration data (
/net.tomlin this example). - environment.DIRMODE: The Linux permissions assigned to the directory holding network configuration settings.
- environment.FS_TYPE: The filesystem type associated with the partition holding network configuration settings.
- environment.GID: The group ID associated with files and directories created on the partition. GID 0 is the root group.
- environment.MODE: The Linux permissions assigned to files in the partition.
- environment.UID: The user ID associated with files and directories created on the partition. UID 0 is the root user.
- image: Container image used to perform the steps needed by this action.
- timeout: Time needed to complete the action, in seconds.
template.tasks.actions.reboot (Bottlerocket)
The reboot action defines how the system restarts to bring up the installed system.
- image: Container image used to perform the steps needed by this action.
- timeout: Time needed to complete the action, in seconds.
- volumes: The volume (directory) to mount into the container from the installed system.
version
Matches the current version of the Tinkerbell template.
Custom Tinkerbell action examples
By creating your own custom Tinkerbell actions, you can add to or modify the installed operating system so those changes take effect when the installed system first starts (from a reboot or pivot).
The following example shows how to add a .deb package (openssl) to an Ubuntu installation:
- environment:
BLOCK_DEVICE: /dev/sda1
CHROOT: "y"
CMD_LINE: apt -y update && apt -y install openssl
DEFAULT_INTERPRETER: /bin/sh -c
FS_TYPE: ext4
image: public.ecr.aws/eks-anywhere/tinkerbell/hub/cexec:6c0f0d437bde2c836d90b000312c8b25fa1b65e1-eks-a-15
name: install-openssl
timeout: 90
The following shows an example of adding a new user (tinkerbell) to an installed Ubuntu system:
- environment:
BLOCK_DEVICE: <block device path> # E.g. /dev/sda1
FS_TYPE: ext4
CHROOT: y
DEFAULT_INTERPRETER: "/bin/sh -c"
CMD_LINE: "useradd --password $(openssl passwd -1 tinkerbell) --shell /bin/bash --create-home --groups sudo tinkerbell"
image: public.ecr.aws/eks-anywhere/tinkerbell/hub/cexec:6c0f0d437bde2c836d90b000312c8b25fa1b65e1-eks-a-15
name: "create-user"
timeout: 90
Look for more examples as they are added to the Tinkerbell examples page.
1.2 - Nutanix configuration
This is a generic template with detailed descriptions below for reference.
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: Cluster
metadata:
name: mgmt
namespace: default
spec:
bundlesRef:
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
name: bundles-2
namespace: eksa-system
clusterNetwork:
cniConfig:
cilium: {}
pods:
cidrBlocks:
- 192.168.0.0/16
services:
cidrBlocks:
- 10.96.0.0/16
controlPlaneConfiguration:
count: 3
endpoint:
host: ""
machineGroupRef:
kind: NutanixMachineConfig
name: mgmt-cp-machine
datacenterRef:
kind: NutanixDatacenterConfig
name: nutanix-cluster
kubernetesVersion: "1.25"
workerNodeGroupConfigurations:
- count: 1
machineGroupRef:
kind: NutanixMachineConfig
name: mgmt-machine
name: md-0
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: NutanixDatacenterConfig
metadata:
name: nutanix-cluster
namespace: default
spec:
endpoint: pc01.cloud.internal
port: 9440
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: NutanixMachineConfig
metadata:
annotations:
anywhere.eks.amazonaws.com/control-plane: "true"
name: mgmt-cp-machine
namespace: default
spec:
cluster:
name: nx-cluster-01
type: name
image:
name: eksa-ubuntu-2004-kube-v1.25
type: name
memorySize: 4Gi
osFamily: ubuntu
subnet:
name: vm-network
type: name
systemDiskSize: 40Gi
project:
type: name
name: my-project
users:
- name: eksa
sshAuthorizedKeys:
- ssh-rsa AAAA…
vcpuSockets: 2
vcpusPerSocket: 1
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: NutanixMachineConfig
metadata:
name: mgmt-machine
namespace: default
spec:
cluster:
name: nx-cluster-01
type: name
image:
name: eksa-ubuntu-2004-kube-v1.25
type: name
memorySize: 4Gi
osFamily: ubuntu
subnet:
name: vm-network
type: name
systemDiskSize: 40Gi
project:
type: name
name: my-project
users:
- name: eksa
sshAuthorizedKeys:
- ssh-rsa AAAA…
vcpuSockets: 2
vcpusPerSocket: 1
---
Cluster Fields
name (required)
Name of your cluster mgmt in this example.
clusterNetwork (required)
Specific network configuration for your Kubernetes cluster.
clusterNetwork.cniConfig (required)
CNI plugin configuration to be used in the cluster. The only supported configuration at the moment is cilium.
clusterNetwork.cniConfig.cilium.policyEnforcementMode
Optionally, you may specify a policyEnforcementMode of default, always, never.
clusterNetwork.pods.cidrBlocks[0] (required)
Subnet used by pods in CIDR notation. Please note that only 1 custom pods CIDR block specification is permitted. This CIDR block should not conflict with the network subnet range selected for the VMs.
clusterNetwork.services.cidrBlocks[0] (required)
Subnet used by services in CIDR notation. Please note that only 1 custom services CIDR block specification is permitted. This CIDR block should not conflict with the network subnet range selected for the VMs.
controlPlaneConfiguration (required)
Specific control plane configuration for your Kubernetes cluster.
controlPlaneConfiguration.count (required)
Number of control plane nodes
controlPlaneConfiguration.machineGroupRef (required)
Refers to the Kubernetes object with Nutanix specific configuration for your nodes. See NutanixMachineConfig fields below.
controlPlaneConfiguration.endpoint.host (required)
A unique IP you want to use for the control plane VM in your EKS Anywhere cluster. Choose an IP in your network range that does not conflict with other VMs.
NOTE: This IP should be outside the network DHCP range as it is a floating IP that gets assigned to one of the control plane nodes for kube-apiserver loadbalancing. Suggestions on how to ensure this IP does not cause issues during cluster creation process are here .
workerNodeGroupConfigurations (required)
This takes in a list of node groups that you can define for your workers. You may define one or more worker node groups.
workerNodeGroupConfigurations.count
Number of worker nodes. Optional if autoscalingConfiguration is used, in which case count will default to autoscalingConfiguration.minCount.
workerNodeGroupConfigurations.machineGroupRef (required)
Refers to the Kubernetes object with Nutanix specific configuration for your nodes. See NutanixMachineConfig fields below.
workerNodeGroupConfigurations.name (required)
Name of the worker node group (default: md-0)
workerNodeGroupConfigurations.autoscalingConfiguration.minCount
Minimum number of nodes for this node group’s autoscaling configuration.
workerNodeGroupConfigurations.autoscalingConfiguration.maxCount
Maximum number of nodes for this node group’s autoscaling configuration.
datacenterRef
Refers to the Kubernetes object with Nutanix environment specific configuration. See NutanixDatacenterConfig fields below.
kubernetesVersion (required)
The Kubernetes version you want to use for your cluster. Supported values: 1.25, 1.24, 1.23, 1.22, 1.21
NutanixDatacenterConfig Fields
endpoint (required)
The Prism Central server fully qualified domain name or IP address. If the server IP is used, the PC SSL certificate must have an IP SAN configured.
port (required)
The Prism Central server port. (Default: 9440)
insecure (optional)
Set insecure to true if the Prism Central server does not have a valid certificate. This is not recommended for production use cases. (Default: false)
additionalTrustBundle (optional; required if using a self-signed PC SSL certificate)
The PEM encoded CA trust bundle.
The additionalTrustBundle needs to be populated with the PEM-encoded x509 certificate of the Root CA that issued the certificate for Prism Central. Suggestions on how to obtain this certificate are here
.
Example:
additionalTrustBundle: |
-----BEGIN CERTIFICATE-----
<certificate string>
-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----
<certificate string>
-----END CERTIFICATE-----
NutanixMachineConfig Fields
cluster
Reference to the Prism Element cluster.
cluster.type
Type to identify the Prism Element cluster. (Permitted values: name or uuid)
cluster.name
Name of the Prism Element cluster.
cluster.uuid
UUID of the Prism Element cluster.
image
Reference to the OS image used for the system disk.
image.type
Type to identify the OS image. (Permitted values: name or uuid)
image.name (name or UUID required)
Name of the image
image.uuid (name or UUID required)
UUID of the image
memorySize
Size of RAM on virtual machines (Default: 4Gi)
osFamily (optional)
Operating System on virtual machines. (Permitted values: ubuntu)
subnet
Reference to the subnet to be assigned to the VMs.
subnet.name (name or UUID required)
Name of the subnet.
subnet.type
Type to identify the subnet. (Permitted values: name or uuid)
subnet.uuid (name or UUID required)
UUID of the subnet.
systemDiskSize
Amount of storage assigned to the system disk. (Default: 40Gi)
vcpuSockets
Amount of vCPU sockets. (Default: 2)
vcpusPerSocket
Amount of vCPUs per socket. (Default: 1)
project (optional)
Reference to an existing project used for the virtual machines.
project.type
Type to identify the project. (Permitted values: name or uuid)
project.name (name or UUID required)
Name of the project
project.uuid (name or UUID required)
UUID of the project
users (optional)
The users you want to configure to access your virtual machines. Only one is permitted at this time.
users[0].name (optional)
The name of the user you want to configure to access your virtual machines through ssh.
The default is eksa if osFamily=ubuntu
users[0].sshAuthorizedKeys (optional)
The SSH public keys you want to configure to access your virtual machines through ssh (as described below). Only 1 is supported at this time.
users[0].sshAuthorizedKeys[0] (optional)
This is the SSH public key that will be placed in authorized_keys on all EKS Anywhere cluster VMs so you can ssh into
them. The user will be what is defined under name above. For example:
ssh -i <private-key-file> <user>@<VM-IP>
The default is generating a key in your $(pwd)/<cluster-name> folder when not specifying a value
1.3 - Snow configuration
This is a generic template with detailed descriptions below for reference. The following additional optional configuration can also be included:
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: Cluster
metadata:
name: my-cluster-name
spec:
clusterNetwork:
cniConfig:
cilium: {}
pods:
cidrBlocks:
- 10.1.0.0/16
services:
cidrBlocks:
- 10.96.0.0/12
controlPlaneConfiguration:
count: 3
endpoint:
host: ""
machineGroupRef:
kind: SnowMachineConfig
name: my-cluster-machines
datacenterRef:
kind: SnowDatacenterConfig
name: my-cluster-datacenter
externalEtcdConfiguration:
count: 3
machineGroupRef:
kind: SnowMachineConfig
name: my-cluster-machines
kubernetesVersion: "1.25"
workerNodeGroupConfigurations:
- count: 1
machineGroupRef:
kind: SnowMachineConfig
name: my-cluster-machines
name: md-0
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: SnowDatacenterConfig
metadata:
name: my-cluster-datacenter
spec: {}
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: SnowMachineConfig
metadata:
name: my-cluster-machines
spec:
amiID: ""
instanceType: sbe-c.large
sshKeyName: ""
osFamily: ubuntu
devices:
- ""
containersVolume:
size: 25
network:
directNetworkInterfaces:
- index: 1
primary: true
ipPoolRef:
kind: SnowIPPool
name: ip-pool-1
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: SnowIPPool
metadata:
name: ip-pool-1
spec:
pools:
- ipStart: 192.168.1.2
ipEnd: 192.168.1.14
subnet: 192.168.1.0/24
gateway: 192.168.1.1
- ipStart: 192.168.1.55
ipEnd: 192.168.1.250
subnet: 192.168.1.0/24
gateway: 192.168.1.1
Cluster Fields
name (required)
Name of your cluster my-cluster-name in this example
clusterNetwork (required)
Specific network configuration for your Kubernetes cluster.
clusterNetwork.cniConfig (required)
CNI plugin configuration to be used in the cluster. The only supported configuration at the moment is cilium.
clusterNetwork.cniConfig.cilium.policyEnforcementMode
Optionally, you may specify a policyEnforcementMode of default, always, never.
clusterNetwork.pods.cidrBlocks[0] (required)
Subnet used by pods in CIDR notation. Please note that only 1 custom pods CIDR block specification is permitted. This CIDR block should not conflict with the network subnet range selected for the devices.
clusterNetwork.services.cidrBlocks[0] (required)
Subnet used by services in CIDR notation. Please note that only 1 custom services CIDR block specification is permitted. This CIDR block should not conflict with the network subnet range selected for the devices.
clusterNetwork.dns.resolvConf.path (optional)
Path to the file with a custom DNS resolver configuration.
controlPlaneConfiguration (required)
Specific control plane configuration for your Kubernetes cluster.
controlPlaneConfiguration.count (required)
Number of control plane nodes
controlPlaneConfiguration.machineGroupRef (required)
Refers to the Kubernetes object with Snow specific configuration for your nodes. See SnowMachineConfig Fields below.
controlPlaneConfiguration.endpoint.host (required)
A unique IP you want to use for the control plane VM in your EKS Anywhere cluster. Choose an IP in your network range that does not conflict with other devices.
NOTE: This IP should be outside the network DHCP range as it is a floating IP that gets assigned to one of the control plane nodes for kube-apiserver loadbalancing.
controlPlaneConfiguration.taints
A list of taints to apply to the control plane nodes of the cluster.
Replaces the default control plane taint. For k8s versions prior to 1.24, it replaces node-role.kubernetes.io/master. For k8s versions 1.24+, it replaces node-role.kubernetes.io/control-plane. The default control plane components will tolerate the provided taints.
Modifying the taints associated with the control plane configuration will cause new nodes to be rolled-out, replacing the existing nodes.
NOTE: The taints provided will be used instead of the default control plane taint. Any pods that you run on the control plane nodes must tolerate the taints you provide in the control plane configuration.
controlPlaneConfiguration.labels
A list of labels to apply to the control plane nodes of the cluster. This is in addition to the labels that EKS Anywhere will add by default.
Modifying the labels associated with the control plane configuration will cause new nodes to be rolled out, replacing the existing nodes.
workerNodeGroupConfigurations (required)
This takes in a list of node groups that you can define for your workers. You may define one or more worker node groups.
workerNodeGroupConfigurations.count
Number of worker nodes. Optional if autoscalingConfiguration is used, in which case count will default to autoscalingConfiguration.minCount.
workerNodeGroupConfigurations.machineGroupRef (required)
Refers to the Kubernetes object with Snow specific configuration for your nodes. See SnowMachineConfig Fields below.
workerNodeGroupConfigurations.name (required)
Name of the worker node group (default: md-0)
workerNodeGroupConfigurations.autoscalingConfiguration.minCount
Minimum number of nodes for this node group’s autoscaling configuration.
workerNodeGroupConfigurations.autoscalingConfiguration.maxCount
Maximum number of nodes for this node group’s autoscaling configuration.
workerNodeGroupConfigurations.taints
A list of taints to apply to the nodes in the worker node group.
Modifying the taints associated with a worker node group configuration will cause new nodes to be rolled-out, replacing the existing nodes associated with the configuration.
At least one node group must not have NoSchedule or NoExecute taints applied to it.
workerNodeGroupConfigurations.labels
A list of labels to apply to the nodes in the worker node group. This is in addition to the labels that EKS Anywhere will add by default.
Modifying the labels associated with a worker node group configuration will cause new nodes to be rolled out, replacing the existing nodes associated with the configuration.
externalEtcdConfiguration.count
Number of etcd members.
externalEtcdConfiguration.machineGroupRef
Refers to the Kubernetes object with Snow specific configuration for your etcd members. See SnowMachineConfig Fields below.
datacenterRef
Refers to the Kubernetes object with Snow environment specific configuration. See SnowDatacenterConfig Fields below.
kubernetesVersion (required)
The Kubernetes version you want to use for your cluster. Supported values: 1.25, 1.24, 1.23, 1.22, 1.21
SnowDatacenterConfig Fields
identityRef
Refers to the Kubernetes secret object with Snow devices credentials used to reconcile the cluster.
SnowMachineConfig Fields
amiID (optional)
AMI ID from which to create the machine instance. Snow provider offers an AMI lookup logic which will look for a suitable AMI ID based on the Kubernetes version and osFamily if the field is empty.
instanceType (optional)
Type of the Snow EC2 machine instance. See Quotas for Compute Instances on a Snowball Edge Device
for supported instance types on Snow (Default: sbe-c.large).
osFamily
Operating System on instance machines. Permitted value: ubuntu.
physicalNetworkConnector (optional)
Type of snow physical network connector to use for creating direct network interfaces. Permitted values: SFP_PLUS, QSFP, RJ45 (Default: SFP_PLUS).
sshKeyName (optional)
Name of the AWS Snow SSH key pair you want to configure to access your machine instances.
The default is eksa-default-{cluster-name}-{uuid}.
devices
A device IP list from which to bootstrap and provision machine instances.
network
Custom network setting for the machine instances. DHCP and static IP configurations are supported.
network.directNetworkInterfaces[0].index (optional)
Index number of a direct network interface (DNI) used to clarify the position in the list. Must be no smaller than 1 and no greater than 8.
network.directNetworkInterfaces[0].primary (optional)
Whether the DNI is primary or not. One and only one primary DNI is required in the directNetworkInterfaces list.
network.directNetworkInterfaces[0].vlanID (optional)
VLAN ID to use for the DNI.
network.directNetworkInterfaces[0].dhcp (optional)
Whether DHCP is to be used to assign IP for the DNI.
network.directNetworkInterfaces[0].ipPoolRef (optional)
Refers to a SnowIPPool object which provides a range of ip addresses. When specified, an IP address selected from the pool will be allocated to the DNI.
containersVolume (optional)
Configuration option for customizing containers data storage volume.
containersVolume.size
Size of the storage for containerd runtime in Gi.
The field is optional for Ubuntu and if specified, the size must be no smaller than 8 Gi.
containersVolume.deviceName (optional)
Containers volume device name.
containersVolume.type (optional)
Type of the containers volume. Permitted values: sbp1, sbg1. (Default: sbp1)
sbp1 stands for capacity-optimized HDD. sbg1 is performance-optimized SSD.
nonRootVolumes (optional)
Configuration options for the non root storage volumes.
nonRootVolumes[0].deviceName
Non root volume device name. Must be specified and cannot have prefix “/dev/sda” as it is reserved for root volume and containers volume.
nonRootVolumes[0].size
Size of the storage device for the non root volume. Must be no smaller than 8 Gi.
nonRootVolumes[0].type (optional)
Type of the non root volume. Permitted values: sbp1, sbg1. (Default: sbp1)
sbp1 stands for capacity-optimized HDD. sbg1 is performance-optimized SSD.
SnowIPPool Fields
pools[0].ipStart
Start address of an IP range.
pools[0].ipEnd
End address of an IP range.
pools[0].subnet
An IP subnet for determining whether an IP is within the subnet.
pools[0].gateway
Gateway of the subnet for routing purpose.
1.4 - vSphere configuration
This is a generic template with detailed descriptions below for reference.
Key: Provider-specific values are in red ; Resources are in green ; Links to field descriptions are in blue
apiVersion: anywhere.eks.amazonaws.com/v1alpha1 kind: Cluster metadata: name: my-cluster-name # Name of the cluster (required) spec: clusterNetwork: # Cluster network configuration (required) cniConfig: # Cluster CNI plugin - default: cilium (required) cilium: {} pods: cidrBlocks: # Subnet CIDR notation for pods (required) - 192.168.0.0/16 services: cidrBlocks: # Subnet CIDR notation for services (required) - 10.96.0.0/12 controlPlaneConfiguration: # Specific cluster control plane config (required) count: 2 # Number of control plane nodes (required) endpoint: # IP for control plane endpoint (required) host: "192.168.0.10" machineGroupRef: # vSphere-specific Kubernetes node config (required) kind: VSphereMachineConfig name: my-cluster-machines taints: # Taints applied to control plane nodes - key: "key1" value: "value1" effect: "NoSchedule" labels: # Labels applied to control plane nodes "key1": "value1" "key2": "value2" datacenterRef: # Kubernetes object with vSphere-specific config kind: VSphereDatacenterConfig name: my-cluster-datacenter externalEtcdConfiguration: count: 3 # Number of etcd members machineGroupRef: # vSphere-specific Kubernetes etcd config kind: VSphereMachineConfig name: my-cluster-machines kubernetesVersion: "1.25" # Kubernetes version to use for the cluster (required) workerNodeGroupConfigurations: # List of node groups you can define for workers (required) - count: 2 # Number of worker nodes machineGroupRef: # vSphere-specific Kubernetes node objects (required) kind: VSphereMachineConfig name: my-cluster-machines name: md-0 # Name of the worker nodegroup (required) taints: # Taints to apply to worker node group nodes - key: "key1" value: "value1" effect: "NoSchedule" labels: # Labels to apply to worker node group nodes "key1": "value1" "key2": "value2" --- apiVersion: anywhere.eks.amazonaws.com/v1alpha1 kind: VSphereDatacenterConfig metadata: name: my-cluster-datacenter spec: datacenter: "datacenter1" # vSphere datacenter name on which to deploy EKS Anywhere (required) disableCSI: false # Set to true to not have EKS Anywhere install and manage vSphere CSI driver server: "myvsphere.local" # FQDN or IP address of vCenter server (required) network: "network1" # Path to the VM network on which to deploy EKS Anywhere (required) insecure: false # Set to true if vCenter does not have a valid certificate thumbprint: "1E:3B:A1:4C:B2:..." # SHA1 thumprint of vCenter server certificate (required if insecure=false) --- apiVersion: anywhere.eks.amazonaws.com/v1alpha1 kind: VSphereMachineConfig metadata: name: my-cluster-machines spec: diskGiB: 25 # Size of disk on VMs, if no snapshots datastore: "datastore1" # Path to vSphere datastore to deploy EKS Anywhere on (required) folder: "folder1" # Path to VM folder for EKS Anywhere cluster VMs (required) numCPUs: 2 # Number of CPUs on virtual machines memoryMiB: 8192 # Size of RAM on VMs osFamily: "bottlerocket" # Operating system on VMs resourcePool: "resourcePool1" # vSphere resource pool for EKS Anywhere VMs (required) storagePolicyName: "storagePolicy1" # Storage policy name associated with VMs template: "bottlerocket-kube-v1-25" # VM template for EKS Anywhere (required for RHEL/Ubuntu-based OVAs) users: # Add users to access VMs via SSH - name: "ec2-user" # Name of each user set to access VMs sshAuthorizedKeys: # SSH keys for user needed to access VMs - "ssh-rsa AAAAB3NzaC1yc2E..." tags: # List of tags to attach to cluster VMs, in URN format - "urn:vmomi:InventoryServiceTag:5b3e951f-4e1d-4511-95b1-5ba1ea97245c:GLOBAL" - "urn:vmomi:InventoryServiceTag:cfee03d0-0189-4f27-8c65-fe75086a86cd:GLOBAL"
The following additional optional configuration can also be included:
Cluster Fields
name (required)
Name of your cluster my-cluster-name in this example
clusterNetwork (required)
Specific network configuration for your Kubernetes cluster.
clusterNetwork.cniConfig (required)
CNI plugin configuration to be used in the cluster. The only supported configuration at the moment is cilium.
clusterNetwork.cniConfig.cilium.policyEnforcementMode
Optionally, you may specify a policyEnforcementMode of default, always, never.
clusterNetwork.pods.cidrBlocks[0] (required)
Subnet used by pods in CIDR notation. Please note that only 1 custom pods CIDR block specification is permitted. This CIDR block should not conflict with the network subnet range selected for the VMs.
clusterNetwork.services.cidrBlocks[0] (required)
Subnet used by services in CIDR notation. Please note that only 1 custom services CIDR block specification is permitted. This CIDR block should not conflict with the network subnet range selected for the VMs.
clusterNetwork.dns.resolvConf.path (optional)
Path to the file with a custom DNS resolver configuration.
controlPlaneConfiguration (required)
Specific control plane configuration for your Kubernetes cluster.
controlPlaneConfiguration.count (required)
Number of control plane nodes
controlPlaneConfiguration.machineGroupRef (required)
Refers to the Kubernetes object with vsphere specific configuration for your nodes. See VSphereMachineConfig Fields below.
controlPlaneConfiguration.endpoint.host (required)
A unique IP you want to use for the control plane VM in your EKS Anywhere cluster. Choose an IP in your network range that does not conflict with other VMs.
NOTE: This IP should be outside the network DHCP range as it is a floating IP that gets assigned to one of the control plane nodes for kube-apiserver loadbalancing. Suggestions on how to ensure this IP does not cause issues during cluster creation process are here
controlPlaneConfiguration.taints
A list of taints to apply to the control plane nodes of the cluster.
Replaces the default control plane taint. For k8s versions prior to 1.24, it replaces node-role.kubernetes.io/master. For k8s versions 1.24+, it replaces node-role.kubernetes.io/control-plane. The default control plane components will tolerate the provided taints.
Modifying the taints associated with the control plane configuration will cause new nodes to be rolled-out, replacing the existing nodes.
NOTE: The taints provided will be used instead of the default control plane taint. Any pods that you run on the control plane nodes must tolerate the taints you provide in the control plane configuration.
controlPlaneConfiguration.labels
A list of labels to apply to the control plane nodes of the cluster. This is in addition to the labels that EKS Anywhere will add by default.
Modifying the labels associated with the control plane configuration will cause new nodes to be rolled out, replacing the existing nodes.
workerNodeGroupConfigurations (required)
This takes in a list of node groups that you can define for your workers. You may define one or more worker node groups.
workerNodeGroupConfigurations.count
Number of worker nodes. Optional if autoscalingConfiguration is used, in which case count will default to autoscalingConfiguration.minCount.
workerNodeGroupConfigurations.machineGroupRef (required)
Refers to the Kubernetes object with vsphere specific configuration for your nodes. See VSphereMachineConfig Fields below.
workerNodeGroupConfigurations.name (required)
Name of the worker node group (default: md-0)
workerNodeGroupConfigurations.autoscalingConfiguration.minCount
Minimum number of nodes for this node group’s autoscaling configuration.
workerNodeGroupConfigurations.autoscalingConfiguration.maxCount
Maximum number of nodes for this node group’s autoscaling configuration.
workerNodeGroupConfigurations.taints
A list of taints to apply to the nodes in the worker node group.
Modifying the taints associated with a worker node group configuration will cause new nodes to be rolled-out, replacing the existing nodes associated with the configuration.
At least one node group must not have NoSchedule or NoExecute taints applied to it.
workerNodeGroupConfigurations.labels
A list of labels to apply to the nodes in the worker node group. This is in addition to the labels that EKS Anywhere will add by default.
Modifying the labels associated with a worker node group configuration will cause new nodes to be rolled out, replacing the existing nodes associated with the configuration.
externalEtcdConfiguration.count
Number of etcd members
externalEtcdConfiguration.machineGroupRef
Refers to the Kubernetes object with vsphere specific configuration for your etcd members. See VSphereMachineConfig Fields below.
datacenterRef
Refers to the Kubernetes object with vsphere environment specific configuration. See VSphereDatacenterConfig Fields below.
kubernetesVersion (required)
The Kubernetes version you want to use for your cluster. Supported values: 1.25, 1.24, 1.23, 1.22, 1.21
VSphereDatacenterConfig Fields
datacenter (required)
The name of the vSphere datacenter to deploy the EKS Anywhere cluster on. For example SDDC-Datacenter.
network (required)
The path to the VM network to deploy your EKS Anywhere cluster on. For example, /<DATACENTER>/network/<NETWORK_NAME>.
Use govc find -type n to see a list of networks.
server (required)
The vCenter server fully qualified domain name or IP address. If the server IP is used, the thumbprint must be set
or insecure must be set to true.
insecure (optional)
Set insecure to true if the vCenter server does not have a valid certificate. (Default: false)
thumbprint (required if insecure=false)
The SHA1 thumbprint of the vCenter server certificate which is only required if you have a self signed certificate.
There are several ways to obtain your vCenter thumbprint. The easiest way is if you have govc installed, you
can run:
govc about.cert -thumbprint -k
Another way is from the vCenter web UI, go to Administration/Certificate Management and click view details of the
machine certificate. The format of this thumbprint does not exactly match the format required though and you will
need to add : to separate each hexadecimal value.
Another way to get the thumbprint is use this command with your servers certificate in a file named ca.crt:
openssl x509 -sha1 -fingerprint -in ca.crt -noout
If you specify the wrong thumbprint, an error message will be printed with the expected thumbprint. If no valid
certificate is being used, insecure must be set to true.
disableCSI (optional)
Set disableCSI to true if you don’t want to have EKS Anywhere install and manage the vSphere CSI driver for you.
More details on the driver are here
NOTE: If you upgrade a cluster and disable the vSphere CSI driver after it has already been installed by EKS Anywhere, you will need to remove the resources manually from the cluster. Delete the
DaemonSetandDeploymentfirst, as they rely on the other resources. This should be done after settingdisableCSItotrueand runningupgrade cluster.These are the resources you would need to delete:
vsphere-csi-controller-role(kind: ClusterRole)vsphere-csi-controller-binding(kind: ClusterRoleBinding)csi.vsphere.vmware.com(kind: CSIDriver)These are the resources you would need to delete in the
kube-systemnamespace:
vsphere-csi-controller(kind: ServiceAccount)csi-vsphere-config(kind: Secret)vsphere-csi-node(kind: DaemonSet)vsphere-csi-controller(kind: Deployment)These are the resources you would need to delete in the
eksa-systemnamespace from the management cluster.
<cluster-name>-csi(kind: ClusterResourceSet)Note: If your cluster is self-managed, you would delete
<cluster-name>-csi(kind: ClusterResourceSet) from the same cluster.
VSphereMachineConfig Fields
memoryMiB (optional)
Size of RAM on virtual machines (Default: 8192)
numCPUs (optional)
Number of CPUs on virtual machines (Default: 2)
osFamily (optional)
Operating System on virtual machines. Permitted values: bottlerocket, ubuntu, redhat (Default: bottlerocket)
diskGiB (optional)
Size of disk on virtual machines if snapshots aren’t included (Default: 25)
users (optional)
The users you want to configure to access your virtual machines. Only one is permitted at this time
users[0].name (optional)
The name of the user you want to configure to access your virtual machines through ssh.
The default is ec2-user if osFamily=bottlrocket and capv if osFamily=ubuntu
users[0].sshAuthorizedKeys (optional)
The SSH public keys you want to configure to access your virtual machines through ssh (as described below). Only 1 is supported at this time.
users[0].sshAuthorizedKeys[0] (optional)
This is the SSH public key that will be placed in authorized_keys on all EKS Anywhere cluster VMs so you can ssh into
them. The user will be what is defined under name above. For example:
ssh -i <private-key-file> <user>@<VM-IP>
The default is generating a key in your $(pwd)/<cluster-name> folder when not specifying a value
template (optional)
The VM template to use for your EKS Anywhere cluster. This template was created when you imported the OVA file into vSphere . This is a required field if you are using Ubuntu-based or RHEL-based OVAs.
datastore (required)
The path to the vSphere datastore
to deploy your EKS Anywhere cluster on, for example /<DATACENTER>/datastore/<DATASTORE_NAME>.
Use govc find -type s to get a list of datastores.
folder (required)
The path to a VM folder for your EKS Anywhere cluster VMs. This allows you to organize your VMs. If the folder does not exist,
it will be created for you. If the folder is blank, the VMs will go in the root folder.
For example /<DATACENTER>/vm/<FOLDER_NAME>/....
Use govc find -type f to get a list of existing folders.
resourcePool (required)
The vSphere Resource pools for your VMs in the EKS Anywhere cluster. Examples of resource pool values include:
- If there is no resource pool:
/<datacenter>/host/<cluster-name>/Resources - If there is a resource pool:
/<datacenter>/host/<cluster-name>/Resources/<resource-pool-name> - The wild card option
*/Resourcesalso often works.
Use govc find -type p to get a list of available resource pools.
storagePolicyName (optional)
The storage policy name associated with your VMs. Generally this can be left blank.
Use govc storage.policy.ls to get a list of available storage policies.
tags (optional)
Optional list of tags to attach to your cluster VMs in the URN format.
Example:
tags:
- urn:vmomi:InventoryServiceTag:8e0ce079-0675-47d6-8665-16ada4e6dabd:GLOBAL
Optional VSphere Credentials
Use the following environment variables to configure Cloud Provider and CSI Driver with different credentials.
EKSA_VSPHERE_CP_USERNAME
Username for Cloud Provider (Default: $EKSA_VSPHERE_USERNAME).
EKSA_VSPHERE_CP_PASSWORD
Password for Cloud Provider (Default: $EKSA_VSPHERE_PASSWORD).
EKSA_VSPHERE_CSI_USERNAME
Username for CSI Driver (Default: $EKSA_VSPHERE_USERNAME).
EKSA_VSPHERE_CSI_PASSWORD
Password for CSI Driver (Default: $EKSA_VSPHERE_PASSWORD).
1.5 - CloudStack configuration
This is a generic template with detailed descriptions below for reference. The following additional optional configuration can also be included:
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: Cluster
metadata:
name: my-cluster-name
spec:
clusterNetwork:
cniConfig:
cilium: {}
pods:
cidrBlocks:
- 192.168.0.0/16
services:
cidrBlocks:
- 10.96.0.0/12
controlPlaneConfiguration:
count: 3
endpoint:
host: ""
machineGroupRef:
kind: CloudStackMachineConfig
name: my-cluster-name-cp
taints:
- key: ""
value: ""
effect: ""
labels:
"<key1>": ""
"<key2>": ""
datacenterRef:
kind: CloudStackDatacenterConfig
name: my-cluster-name
externalEtcdConfiguration:
count: 3
machineGroupRef:
kind: CloudStackMachineConfig
name: my-cluster-name-etcd
kubernetesVersion: "1.23"
managementCluster:
name: my-cluster-name
workerNodeGroupConfigurations:
- count: 2
machineGroupRef:
kind: CloudStackMachineConfig
name: my-cluster-name
taints:
- key: ""
value: ""
effect: ""
labels:
"<key1>": ""
"<key2>": ""
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: CloudStackDatacenterConfig
metadata:
name: my-cluster-name-datacenter
spec:
availabilityZones:
- account: admin
credentialsRef: global
domain: domain1
managementApiEndpoint: ""
name: az-1
zone:
name: zone1
network:
name: "net1"
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: CloudStackMachineConfig
metadata:
name: my-cluster-name-cp
spec:
computeOffering:
name: "m4-large"
users:
- name: capc
sshAuthorizedKeys:
- ssh-rsa AAAA...
template:
name: "rhel8-k8s-118"
diskOffering:
name: "Small"
mountPath: "/data-small"
device: "/dev/vdb"
filesystem: "ext4"
label: "data_disk"
symlinks:
/var/log/kubernetes: /data-small/var/log/kubernetes
affinityGroupIds:
- control-plane-anti-affinity
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: CloudStackMachineConfig
metadata:
name: my-cluster-name
spec:
computeOffering:
name: "m4-large"
users:
- name: capc
sshAuthorizedKeys:
- ssh-rsa AAAA...
template:
name: "rhel8-k8s-118"
diskOffering:
name: "Small"
mountPath: "/data-small"
device: "/dev/vdb"
filesystem: "ext4"
label: "data_disk"
symlinks:
/var/log/pods: /data-small/var/log/pods
/var/log/containers: /data-small/var/log/containers
affinityGroupIds:
- worker-affinity
userCustomDetails:
foo: bar
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: CloudStackMachineConfig
metadata:
name: my-cluster-name-etcd
spec:
computeOffering: {}
name: "m4-large"
users:
- name: "capc"
sshAuthorizedKeys:
- "ssh-rsa AAAAB3N...
template:
name: "rhel8-k8s-118"
diskOffering:
name: "Small"
mountPath: "/data-small"
device: "/dev/vdb"
filesystem: "ext4"
label: "data_disk"
symlinks:
/var/lib: /data-small/var/lib
affinityGroupIds:
- etcd-affinity
---
Cluster Fields
name (required)
Name of your cluster my-cluster-name in this example
clusterNetwork (required)
Specific network configuration for your Kubernetes cluster.
clusterNetwork.cniConfig (required)
CNI plugin configuration to be used in the cluster. The only supported configuration at the moment is cilium.
clusterNetwork.cniConfig.cilium.policyEnforcementMode
Optionally, you may specify a policyEnforcementMode of default, always, never.
clusterNetwork.pods.cidrBlocks[0] (required)
Subnet used by pods in CIDR notation. Please note that only 1 custom pods CIDR block specification is permitted. This CIDR block should not conflict with the network subnet range selected for the VMs.
clusterNetwork.services.cidrBlocks[0] (required)
Subnet used by services in CIDR notation. Please note that only 1 custom services CIDR block specification is permitted. This CIDR block should not conflict with the network subnet range selected for the VMs.
controlPlaneConfiguration (required)
Specific control plane configuration for your Kubernetes cluster.
controlPlaneConfiguration.count (required)
Number of control plane nodes
controlPlaneConfiguration.endpoint.host (required)
A unique IP you want to use for the control plane VM in your EKS Anywhere cluster. Choose an IP in your network range that does not conflict with other VMs.
NOTE: This IP should be outside the network DHCP range as it is a floating IP that gets assigned to one of the control plane nodes for kube-apiserver loadbalancing. Suggestions on how to ensure this IP does not cause issues during cluster creation process are here
controlPlaneConfiguration.machineGroupRef (required)
Refers to the Kubernetes object with CloudStack specific configuration for your nodes. See CloudStackMachineConfig Fields below.
controlPlaneConfiguration.taints
A list of taints to apply to the control plane nodes of the cluster.
Replaces the default control plane taint, node-role.kubernetes.io/master. The default control plane components will tolerate the provided taints.
Modifying the taints associated with the control plane configuration will cause new nodes to be rolled-out, replacing the existing nodes.
NOTE: The taints provided will be used instead of the default control plane taint
node-role.kubernetes.io/master. Any pods that you run on the control plane nodes must tolerate the taints you provide in the control plane configuration.
controlPlaneConfiguration.labels
A list of labels to apply to the control plane nodes of the cluster. This is in addition to the labels that EKS Anywhere will add by default.
A special label value is supported by the CAPC provider:
labels:
cluster.x-k8s.io/failure-domain: ds.meta_data.failuredomain
The ds.meta_data.failuredomain value will be replaced with a failuredomain name where the node is deployed, such as az-1.
Modifying the labels associated with the control plane configuration will cause new nodes to be rolled out, replacing the existing nodes.
datacenterRef
Refers to the Kubernetes object with CloudStack environment specific configuration. See CloudStackDatacenterConfig Fields below.
externalEtcdConfiguration.count
Number of etcd members
externalEtcdConfiguration.machineGroupRef
Refers to the Kubernetes object with CloudStack specific configuration for your etcd members. See CloudStackMachineConfig Fields below.
kubernetesVersion (required)
The Kubernetes version you want to use for your cluster. Supported values: 1.24, 1.23, 1.22, 1.21
managementCluster (required)
Identifies the name of the management cluster. If this is a standalone cluster or if it were serving as the management cluster for other workload clusters, this will be the same as the cluster name.
workerNodeGroupConfigurations (required)
This takes in a list of node groups that you can define for your workers. You may define one or more worker node groups.
workerNodeGroupConfigurations.count
Number of worker nodes. Optional if autoscalingConfiguration is used, in which case count will default to autoscalingConfiguration.minCount.
workerNodeGroupConfigurations.machineGroupRef (required)
Refers to the Kubernetes object with CloudStack specific configuration for your nodes. See CloudStackMachineConfig Fields below.
workerNodeGroupConfigurations.name (required)
Name of the worker node group (default: md-0)
workerNodeGroupConfigurations.autoscalingConfiguration.minCount
Minimum number of nodes for this node group’s autoscaling configuration.
workerNodeGroupConfigurations.autoscalingConfiguration.maxCount
Maximum number of nodes for this node group’s autoscaling configuration.
workerNodeGroupConfigurations.taints
A list of taints to apply to the nodes in the worker node group.
Modifying the taints associated with a worker node group configuration will cause new nodes to be rolled-out, replacing the existing nodes associated with the configuration.
At least one node group must not have NoSchedule or NoExecute taints applied to it.
workerNodeGroupConfigurations.labels
A list of labels to apply to the nodes in the worker node group. This is in addition to the labels that EKS Anywhere will add by default. A special label value is supported by the CAPC provider:
labels:
cluster.x-k8s.io/failure-domain: ds.meta_data.failuredomain
The ds.meta_data.failuredomain value will be replaced with a failuredomain name where the node is deployed, such as az-1.
Modifying the labels associated with a worker node group configuration will cause new nodes to be rolled out, replacing the existing nodes associated with the configuration.
CloudStackDatacenterConfig
availabilityZones.account (optional)
Account used to access CloudStack.
As long as you pass valid credentials, through availabilityZones.credentialsRef, this value is not required.
availabilityZones.credentialsRef (required)
If you passed credentials through the environment variable EKSA_CLOUDSTACK_B64ENCODED_SECRET noted in Create CloudStack production cluster
, you can identify those credentials here.
For that example, you would use the profile name global.
You can instead use a previously created secret on the Kubernetes cluster in the eksa-system namespace.
availabilityZones.domain (optional)
CloudStack domain to deploy the cluster. The default is ROOT.
availabilityZones.managementApiEndpoint (required)
Location of the CloudStack API management endpoint. For example, http://10.11.0.2:8080/client/api.
availabilityZones.{id,name} (required)
Name or ID of the CloudStack zone on which to deploy the cluster.
availabilityZones.zone.network.{id,name} (required)
CloudStack network name or ID to use with the cluster.
CloudStackMachineConfig
In the example above, there are separate CloudStackMachineConfig sections for the control plane (my-cluster-name-cp), worker (my-cluster-name) and etcd (my-cluster-name-etcd) nodes.
computeOffering.{id,name} (required)
Name or ID of the CloudStack compute instance.
users[0].name (optional)
The name of the user you want to configure to access your virtual machines through ssh. You can add as many users object as you want.
The default is capc.
users[0].sshAuthorizedKeys (optional)
The SSH public keys you want to configure to access your virtual machines through ssh (as described below). Only 1 is supported at this time.
users[0].sshAuthorizedKeys[0] (optional)
This is the SSH public key that will be placed in authorized_keys on all EKS Anywhere cluster VMs so you can ssh into
them. The user will be what is defined under name above. For example:
ssh -i <private-key-file> <user>@<VM-IP>
The default is generating a key in your $(pwd)/<cluster-name> folder when not specifying a value.
template.{id,name} (required)
The VM template to use for your EKS Anywhere cluster. Currently, a VM based on RHEL 8.6 is required. This can be a name or ID. See the Artifacts page for instructions for building RHEL-based images.
diskOffering (optional)
Name representing a disk you want to mount into nodes for this CloudStackMachineConfig
diskOffering.mountPath (optional)
Mount point on which to mount the disk.
diskOffering.device (optional)
Device name of the disk partition to mount.
diskOffering.filesystem (optional)
File system type used to format the filesystem on the disk.
diskOffering.label (optional)
Label to apply to the disk partition.
symlinks (optional)
Symbolic link of a directory or file you want to mount from the host filesystem to the mounted filesystem.
userCustomDetails (optional)
Add key/value pairs to nodes in a CloudStackMachineConfig.
These can be used for things like identifying sets of nodes that you want to add to a security group that opens selected ports.
affinityGroupIDs (optional)
Group ID to attach to the set of host systems to indicate how affinity is done for services on those systems.
affinity (optional)
Allows you to set pro and anti affinity for the CloudStackMachineConfig.
This can be used in a mutually exclusive fashion with the affinityGroupIDs field.
1.6 - Optional configuration
1.6.1 - Autoscaling configuration
Cluster Autoscaling (Optional)
Cluster Autoscaler configuration in EKS Anywhere cluster spec
EKS Anywhere supports autoscaling worker node groups using the Kubernetes Cluster Autoscaler
’s clusterapi cloudProvider.
- Configure a worker node group to be picked up by a cluster autoscaler deployment by adding a
autoscalingConfigurationblock to theworkerNodeGroupConfiguration:apiVersion: anywhere.eks.amazonaws.com/v1alpha1 kind: Cluster metadata: name: my-cluster-name spec: workerNodeGroupConfigurations: - autoscalingConfiguration: minCount: 1 maxCount: 5 machineGroupRef: kind: VSphereMachineConfig name: worker-machine-a name: md-0 - count: 1 autoscalingConfiguration: minCount: 1 maxCount: 3 machineGroupRef: kind: VSphereMachineConfig name: worker-machine-b name: md-1
Note that if no count is specified it will default to the minCount value.
EKS Anywhere will automatically apply the following annotations to your MachineDeployment objects:
cluster.x-k8s.io/cluster-api-autoscaler-node-group-max-size: <minCount>
cluster.x-k8s.io/cluster-api-autoscaler-node-group-max-size: <maxCount>
After deploying the Kubernetes Cluster Autoscaler from upstream or as a curated package , the deployment will pick up your MachineDeployment and scale the nodes as per your min and max count values.
Cluster Autoscaler Deployment Topologies
The Kubernetes Cluster Autoscaler can only scale a single cluster per deployment.
This means that each cluster you want to scale will need its own cluster autoscaler deployment.
We support three deployment topologies:
- Cluster Autoscaler deployed in the management cluster to autoscale the management cluster itself
- Cluster Autoscaler deployed in the management cluster to autoscale a remote workload cluster
- Cluster Autoscaler deployed in the workload cluster to autoscale the workload cluster itself
If your cluster architecture supports management clusters with resources to run additional workloads, you may want to consider using deployment topologies (1) and (2). Instructions for using this topology can be found here .
If your deployment topology runs small management clusters though, you may want to follow deployment topology (3) and deploy the cluster autoscaler to run in a workload cluster .
1.6.2 - CNI plugin configuration
Specifying CNI Plugin in EKS Anywhere cluster spec
EKS Anywhere currently supports two CNI plugins: Cilium and Kindnet. Only one of them can be selected
for a cluster, and the plugin cannot be changed once the cluster is created.
Up until the 0.7.x releases, the plugin had to be specified using the cni field on cluster spec.
Starting with release 0.8, the plugin should be specified using the new cniConfig field as follows:
-
For selecting Cilium as the CNI plugin:
apiVersion: anywhere.eks.amazonaws.com/v1alpha1 kind: Cluster metadata: name: my-cluster-name spec: clusterNetwork: pods: cidrBlocks: - 192.168.0.0/16 services: cidrBlocks: - 10.96.0.0/12 cniConfig: cilium: {}EKS Anywhere selects this as the default plugin when generating a cluster config.
-
Or for selecting Kindnetd as the CNI plugin:
apiVersion: anywhere.eks.amazonaws.com/v1alpha1 kind: Cluster metadata: name: my-cluster-name spec: clusterNetwork: pods: cidrBlocks: - 192.168.0.0/16 services: cidrBlocks: - 10.96.0.0/12 cniConfig: kindnetd: {}
NOTE: EKS Anywhere allows specifying only 1 plugin for a cluster and does not allow switching the plugins after the cluster is created.
Policy Configuration options for Cilium plugin
Cilium accepts policy enforcement modes from the users to determine the allowed traffic between pods.
The allowed values for this mode are: default, always and never.
Please refer the official Cilium documentation
for more details on how each mode affects
the communication within the cluster and choose a mode accordingly.
You can choose to not set this field so that cilium will be launched with the default mode.
Starting release 0.8, Cilium’s policy enforcement mode can be set through the cluster spec
as follows:
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: Cluster
metadata:
name: my-cluster-name
spec:
clusterNetwork:
pods:
cidrBlocks:
- 192.168.0.0/16
services:
cidrBlocks:
- 10.96.0.0/12
cniConfig:
cilium:
policyEnforcementMode: "always"
Please note that if the always mode is selected, all communication between pods is blocked unless
NetworkPolicy objects allowing communication are created.
In order to ensure that the cluster gets created successfully, EKS Anywhere will create the required
NetworkPolicy objects for all its core components. But it is up to the user to create the NetworkPolicy
objects needed for the user workloads once the cluster is created.
Network policies created by EKS Anywhere for “always” mode
As mentioned above, if Cilium is configured with policyEnforcementMode set to always,
EKS Anywhere creates NetworkPolicy objects to enable communication between
its core components. EKS Anywhere will create NetworkPolicy resources in the following namespaces allowing all ingress/egress traffic by default:
- kube-system
- eksa-system
- All core Cluster API namespaces:
- capi-system
- capi-kubeadm-bootstrap-system
- capi-kubeadm-control-plane-system
- etcdadm-bootstrap-provider-system
- etcdadm-controller-system
- cert-manager
- Infrastructure provider’s namespace (for instance, capd-system OR capv-system)
- If Gitops is enabled, then the gitops namespace (flux-system by default)
This is the NetworkPolicy that will be created in these namespaces for the cluster:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-ingress-egress
namespace: test
spec:
podSelector: {}
ingress:
- {}
egress:
- {}
policyTypes:
- Ingress
- Egress
Switching the Cilium policy enforcement mode
The policy enforcement mode for Cilium can be changed as a part of cluster upgrade through the cli upgrade command.
-
Switching to
alwaysmode: When switching fromdefault/nevertoalwaysmode, EKS Anywhere will create the required NetworkPolicy objects for its core components (listed above). This will ensure that the cluster gets upgraded successfully. But it is up to the user to create the NetworkPolicy objects required for the user workloads. -
Switching from
alwaysmode: When switching fromalwaystodefaultmode, EKS Anywhere will not delete any of the existing NetworkPolicy objects, including the ones required for EKS Anywhere components (listed above). The user must delete NetworkPolicy objects as needed.
Node IPs configuration option
Starting with release v0.10, the node-cidr-mask-size flag
for Kubernetes controller manager (kube-controller-manager) is configurable via the EKS anywhere cluster spec. The clusterNetwork.nodes being an optional field,
is not generated in the EKS Anywhere spec using generate clusterconfig command. This block for nodes will need to be manually added to the cluster spec under the
clusterNetwork section:
clusterNetwork:
pods:
cidrBlocks:
- 192.168.0.0/16
services:
cidrBlocks:
- 10.96.0.0/12
cniConfig:
cilium: {}
nodes:
cidrMaskSize: 24
If the user does not specify the clusterNetwork.nodes field in the cluster yaml spec, the value for this flag defaults to 24 for IPv4.
Please note that this mask size needs to be greater than the pods CIDR mask size. In the above spec, the pod CIDR mask size is 16
and the node CIDR mask size is 24. This ensures the cluster 256 blocks of /24 networks. For example, node1 will get
192.168.0.0/24, node2 will get 192.168.1.0/24, node3 will get 192.168.2.0/24 and so on.
To support more than 256 nodes, the cluster CIDR block needs to be large, and the node CIDR mask size needs to be small, to support that many IPs. For instance, to support 1024 nodes, a user can do any of the following things
- Set the pods cidr blocks to
192.168.0.0/16and node cidr mask size to 26 - Set the pods cidr blocks to
192.168.0.0/15and node cidr mask size to 25
Please note that the node-cidr-mask-size needs to be large enough to accommodate the number of pods you want to run on each node.
A size of 24 will give enough IP addresses for about 250 pods per node, however a size of 26 will only give you about 60 IPs.
This is an immutable field, and the value can’t be updated once the cluster has been created.
1.6.3 - IAM Roles for Service Accounts configuration
IAM Role for Service Account on EKS Anywhere clusters with self-hosted signing keys
IAM Roles for Service Account (IRSA) enables applications running in clusters to authenticate with AWS services using IAM roles. The current solution for leveraging this in EKS Anywhere involves creating your own OIDC provider for the cluster, and hosting your cluster’s public service account signing key. The public keys along with the OIDC discovery document should be hosted somewhere that AWS STS can discover it. The steps below assume the keys will be hosted on a publicly accessible S3 bucket. Refer this doc to ensure that the s3 bucket is publicly accessible.
The steps below are based on the guide for configuring IRSA for DIY Kubernetes, with modifications specific to EKS Anywhere’s cluster provisioning workflow. The main modification is the process of generating the keys.json document. As per the original guide, the user has to create the service account signing keys, and then use that to create the keys.json document prior to cluster creation. This order is reversed for EKS Anywhere clusters, so you will create the cluster first, and then retrieve the service account signing key generated by the cluster, and use it to create the keys.json document. The sections below show how to do this in detail.
Create an OIDC provider and make its discovery document publicly accessible
-
Create an s3 bucket to host the public signing keys and OIDC discovery document for your cluster as per this section. Ensure you follow all the steps and save the
$HOSTNAMEand$ISSUER_HOSTPATH. -
Create the OIDC discovery document as follows:
cat <<EOF > discovery.json { "issuer": "https://$ISSUER_HOSTPATH", "jwks_uri": "https://$ISSUER_HOSTPATH/keys.json", "authorization_endpoint": "urn:kubernetes:programmatic_authorization", "response_types_supported": [ "id_token" ], "subject_types_supported": [ "public" ], "id_token_signing_alg_values_supported": [ "RS256" ], "claims_supported": [ "sub", "iss" ] } EOF -
Upload it to the publicly accessible S3 bucket:
aws s3 cp --acl public-read ./discovery.json s3://$S3_BUCKET/.well-known/openid-configuration -
Create an OIDC provider for your cluster. Set the
Provider URLtohttps://$ISSUER_HOSTPATH, and audience tosts.amazonaws.com. -
Note down the
Providerfield of OIDC provider after it is created. -
Assign an IAM role to this OIDC provider.
-
From the IAM console, select and click on the OIDC provider created from above, and click on Assign role at the top right.
-
Select Create a new role.
-
In the Select type of trusted entity section, choose Web identity.
-
In the Choose a web identity provider section:
- For Identity provider, choose the auto selected Identity Provider URL for your cluster.
- For Audience, choose sts.amazonaws.com.
-
Choose Next: Permissions.
-
In the Attach Policy section, select the IAM policy that has the permissions that you want your applications running in the pods to use.
-
Continue with the next sections of adding tags if desired and a suitable name for this role and create the role.
-
Below is a sample trust policy of IAM role for your pods. Remember to replace
Account IDandISSUER_HOSTPATHwith required values.{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Federated": "arn:aws:iam::111122223333:oidc-provider/ISSUER_HOSTPATH" }, "Action": "sts:AssumeRoleWithWebIdentity", "Condition": { "__doc_comment": "scope the role to the service account (optional)", "StringEquals": { "ISSUER_HOSTPATH:sub": "system:serviceaccount:default:my-serviceaccount" }, "__doc_comment": "OR scope the role to a namespace (optional)", "StringLike": { "ISSUER_HOSTPATH/CLUSTER_ID:sub": ["system:serviceaccount:default:*","system:serviceaccount:observability:*"] } } } ] } -
After the role is created, note down the name of this IAM Role as
OIDC_IAM_ROLE. -
Once the cluster is created, you can create service accounts and grant them this role by editing the trust relationship of this role. You can use
StringLikecondition to add required service accounts, as mentioned in the above sample. Please also refer to section Configure the trust relationship for the OIDC provider’s IAM Role .
-
Create the EKS Anywhere cluster
- When creating the EKS Anywhere cluster, you need to configure the kube-apiserver’s
service-account-issuerflag so it can issue and mount projected service account tokens in pods. For this, use the value obtained in the first section for$ISSUER_HOSTPATHas theservice-account-issuer. Configure the kube-apiserver by setting this value through the EKS Anywhere cluster spec as follows:apiVersion: anywhere.eks.amazonaws.com/v1alpha1 kind: Cluster metadata: name: my-cluster-name spec: podIamConfig: serviceAccountIssuer: https://$ISSUER_HOSTPATH
Set the remaining fields in cluster spec
as required and create the cluster using the eksctl anywhere create cluster command.
Generate keys.json and make it publicly accessible
-
The cluster provisioning workflow generates a pair of service account signing keys. Retrieve the public signing key generated and used by the cluster, and create a keys.json document containing the public signing key.
git clone https://github.com/aws/amazon-eks-pod-identity-webhook cd amazon-eks-pod-identity-webhook kubectl get secret ${CLUSTER_NAME}-sa -n eksa-system -o jsonpath={.data.tls\\.crt} | base64 --decode > ${CLUSTER_NAME}-sa.pub go run ./hack/self-hosted/main.go -key ${CLUSTER_NAME}-sa.pub | jq '.keys += [.keys[0]] | .keys[1].kid = ""' > keys.json -
Upload the keys.json document to the s3 bucket.
aws s3 cp --acl public-read ./keys.json s3://$S3_BUCKET/keys.json
Deploy pod identity webhook
-
After hosting the service account public signing key and OIDC discovery documents, the applications running in pods can start accessing the desired AWS resources, as long as the pod is mounted with the right service account tokens. This part of configuring the pods with the right service account tokens and env vars is automated by the amazon pod identity webhook . Once the webhook is deployed, it mutates any pods launched using service accounts annotated with
eks.amazonaws.com/role-arn -
Clone amazon-eks-pod-identity-webhook if not done already.
-
Set the $KUBECONFIG env var to the path of the EKS Anywhere cluster.
-
Create
my-service-account.yamlwithOIDC_IAM_ROLEand other annotations as mentioned in sample below.apiVersion: v1 kind: ServiceAccount metadata: name: my-serviceaccount namespace: default annotations: # set this with value of OIDC_IAM_ROLE eks.amazonaws.com/role-arn: "arn:aws:iam::111122223333:role/s3-reader" # optional: Defaults to "sts.amazonaws.com" if not set eks.amazonaws.com/audience: "sts.amazonaws.com" # optional: When set to "true", adds AWS_STS_REGIONAL_ENDPOINTS env var # to containers eks.amazonaws.com/sts-regional-endpoints: "true" # optional: Defaults to 86400 for expirationSeconds if not set # Note: This value can be overwritten if specified in the pod # annotation as shown in the next step. eks.amazonaws.com/token-expiration: "86400" -
Run the following command to apply the manifests for the amazon-eks-pod-identity-webhook. The image used here will be pulled from docker.io. Optionally, the image can be imported into (or proxied through) your private registry. Change the IMAGE= argument here to your private registry if needed.
make cluster-up IMAGE=amazon/amazon-eks-pod-identity-webhook:latest -
Finally, apply the
my-service-account.yamlfile to create your service account.kubectl apply -f my-service-account.yaml -
You can validate IRSA by using test steps mentioned here . Ensure awscli pod is deployed in same namespace of ServiceAccount pod-identity-webhook.
Configure the trust relationship for the OIDC provider’s IAM Role
In order to grant certain service accounts access to the desired AWS resources, edit the trust relationship for the OIDC provider’s IAM Role (OIDC_IAM_ROLE) created in the first section, and add in the desired service accounts.
-
Choose the role in the console to open it for editing.
-
Choose the Trust relationships tab, and then choose Edit trust relationship.
-
Find the line that looks similar to the following:
"$ISSUER_HOSTPATH:aud": "sts.amazonaws.com" -
Change the line to look like the following line. Replace
audwithsuband replaceKUBERNETES_SERVICE_ACCOUNT_NAMESPACEandKUBERNETES_SERVICE_ACCOUNT_NAMEwith the name of your Kubernetes service account and the Kubernetes namespace that the account exists in."$ISSUER_HOSTPATH:sub": "system:serviceaccount:KUBERNETES_SERVICE_ACCOUNT_NAMESPACE:KUBERNETES_SERVICE_ACCOUNT_NAME" -
Refer this doc for different ways of configuring one or multiple service accounts through the condition operators in the trust relationship.
-
Choose Update Trust Policy to finish.
1.6.4 - etcd configuration
NOTE: Currently, the Unstacked etcd topology is not supported with the Amazon EKS Anywhere Bare Metal and Nutanix deployment options.
Unstacked etcd topology (recommended)
There are two types of etcd topologies for configuring a Kubernetes cluster:
- Stacked: The etcd members and control plane components are colocated (run on the same node/machines)
- Unstacked/External: With the unstacked or external etcd topology, etcd members have dedicated machines and are not colocated with control plane components
The unstacked etcd topology is recommended for a HA cluster for the following reasons:
- External etcd topology decouples the control plane components and etcd member. So if a control plane-only node fails, or if there is a memory leak in a component like kube-apiserver, it won’t directly impact an etcd member.
- Etcd is resource intensive, so it is safer to have dedicated nodes for etcd, since it could use more disk space or higher bandwidth. Having a separate etcd cluster for these reasons could ensure a more resilient HA setup.
EKS Anywhere supports both topologies. In order to configure a cluster with the unstacked/external etcd topology, you need to configure your cluster by updating the configuration file before creating the cluster. This is a generic template with detailed descriptions below for reference:
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: Cluster
metadata:
name: my-cluster-name
spec:
clusterNetwork:
pods:
cidrBlocks:
- 192.168.0.0/16
services:
cidrBlocks:
- 10.96.0.0/12
cniConfig:
cilium: {}
controlPlaneConfiguration:
count: 1
endpoint:
host: ""
machineGroupRef:
kind: VSphereMachineConfig
name: my-cluster-name-cp
datacenterRef:
kind: VSphereDatacenterConfig
name: my-cluster-name
# etcd configuration
externalEtcdConfiguration:
count: 3
machineGroupRef:
kind: VSphereMachineConfig
name: my-cluster-name-etcd
kubernetesVersion: "1.19"
workerNodeGroupConfigurations:
- count: 1
machineGroupRef:
kind: VSphereMachineConfig
name: my-cluster-name
name: md-0
externalEtcdConfiguration (under Cluster)
This field accepts any configuration parameters for running external etcd.
count (required)
This determines the number of etcd members in the cluster. The recommended number is 3.
machineGroupRef (required)
1.6.5 - AWS IAM Authenticator configuration
AWS IAM Authenticator support (optional)
EKS Anywhere can create clusters that support AWS IAM Authenticator-based api server authentication. In order to add IAM Authenticator support, you need to configure your cluster by updating the configuration file before creating the cluster. This is a generic template with detailed descriptions below for reference:
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: Cluster
metadata:
name: my-cluster-name
spec:
...
# IAM Authenticator support
identityProviderRefs:
- kind: AWSIamConfig
name: aws-iam-auth-config
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: AWSIamConfig
metadata:
name: aws-iam-auth-config
spec:
awsRegion: ""
backendMode:
- ""
mapRoles:
- roleARN: arn:aws:iam::XXXXXXXXXXXX:role/myRole
username: myKubernetesUsername
groups:
- ""
mapUsers:
- userARN: arn:aws:iam::XXXXXXXXXXXX:user/myUser
username: myKubernetesUsername
groups:
- ""
partition: ""
identityProviderRefs (Under Cluster)
List of identity providers you want configured for the Cluster.
This would include a reference to the AWSIamConfig object with the configuration below.
awsRegion (required)
- Description: awsRegion can be any region in the aws partition that the IAM roles exist in.
- Type: string
backendMode (required)
- Description: backendMode configures the IAM authenticator server’s backend mode (i.e. where to source mappings from). We support EKSConfigMap and CRD modes supported by AWS IAM Authenticator, for more details refer to backendMode
- Type: string
mapRoles, mapUsers (recommended for EKSConfigMap backend)
-
Description: When using
EKSConfigMapbackendMode, we recommend providing eithermapRolesormapUsersto set the IAM role mappings at the time of creation. This input is added to an EKS style ConfigMap. For more details refer to EKS IAM -
Type: list object
roleARN, userARN (required)
- Description: IAM ARN to authenticate to the cluster.
roleARNspecifies an IAM role anduserARNspecifies an IAM user. - Type: string
username (required)
- Description: The Kubernetes username the IAM ARN is mapped to in the cluster. The ARN gets mapped to the Kubernetes cluster permissions associated with the username.
- Type: string
groups
- Description: List of kubernetes user groups that the mapped IAM ARN is given permissions to.
- Type: list string
- Description: IAM ARN to authenticate to the cluster.
partition
- Description: This field is used to set the aws partition that the IAM roles are present in. Default value is
aws. - Type: string
1.6.6 - OIDC configuration
OIDC support (optional)
EKS Anywhere can create clusters that support api server OIDC authentication.
In order to add OIDC support, you need to configure your cluster by updating the configuration file to include the details below. The OIDC configuration can be added at cluster creation time, or introduced via a cluster upgrade in VMware and CloudStack.
This is a generic template with detailed descriptions below for reference:
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: Cluster
metadata:
name: my-cluster-name
spec:
...
# OIDC support
identityProviderRefs:
- kind: OIDCConfig
name: my-cluster-name
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: OIDCConfig
metadata:
name: my-cluster-name
spec:
clientId: ""
groupsClaim: ""
groupsPrefix: ""
issuerUrl: "https://x"
requiredClaims:
- claim: ""
value: ""
usernameClaim: ""
usernamePrefix: ""
identityProviderRefs (Under Cluster)
List of identity providers you want configured for the Cluster.
This would include a reference to the OIDCConfig object with the configuration below.
clientId (required)
- Description: ClientId defines the client ID for the OpenID Connect client
- Type: string
groupsClaim (optional)
- Description: GroupsClaim defines the name of a custom OpenID Connect claim for specifying user groups
- Type: string
groupsPrefix (optional)
- Description: GroupsPrefix defines a string to be prefixed to all groups to prevent conflicts with other authentication strategies
- Type: string
issuerUrl (required)
- Description: IssuerUrl defines the URL of the OpenID issuer, only HTTPS scheme will be accepted
- Type: string
requiredClaims (optional)
List of RequiredClaim objects listed below. Only one is supported at this time.
requiredClaims[0] (optional)
- Description: RequiredClaim defines a key=value pair that describes a required claim in the ID Token
- claim
- type: string
- value
- type: string
- claim
- Type: object
usernameClaim (optional)
- Description: UsernameClaim defines the OpenID claim to use as the user name. Note that claims other than the default (‘sub’) is not guaranteed to be unique and immutable
- Type: string
usernamePrefix (optional)
- Description: UsernamePrefix defines a string to be prefixed to all usernames. If not provided, username claims other than ‘email’ are prefixed by the issuer URL to avoid clashes. To skip any prefixing, provide the value ‘-’.
- Type: string
1.6.7 - GitOpsConfig configuration
GitOps Support (Optional)
EKS Anywhere can create clusters that supports GitOps configuration management with Flux.
In order to add GitOps support, you need to configure your cluster by specifying the configuration file with gitOpsRef field when creating or upgrading the cluster.
We currently support two types of configurations: FluxConfig and GitOpsConfig.
Flux Configuration
The flux configuration spec has three optional fields, regardless of the chosen git provider.
Flux Configuration Spec Details
systemNamespace (optional)
- Description: Namespace in which to install the gitops components in your cluster. Defaults to
flux-system - Type: string
clusterConfigPath (optional)
- Description: The path relative to the root of the git repository where EKS Anywhere will store the cluster configuration files. Defaults to the cluster name
- Type: string
branch (optional)
- Description: The branch to use when committing the configuration. Defaults to
main - Type: string
EKS Anywhere currently supports two git providers for FluxConfig: Github and Git.
Github provider
Please note that for the Flux config to work successfully with the Github provider, the environment variable EKSA_GITHUB_TOKEN needs to be set with a valid GitHub PAT
.
This is a generic template with detailed descriptions below for reference:
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: Cluster
metadata:
name: my-cluster-name
namespace: default
spec:
...
#GitOps Support
gitOpsRef:
name: my-github-flux-provider
kind: FluxConfig
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: FluxConfig
metadata:
name: my-github-flux-provider
namespace: default
spec:
systemNamespace: "my-alternative-flux-system-namespace"
clusterConfigPath: "path-to-my-clusters-config"
branch: "main"
github:
personal: true
repository: myClusterGitopsRepo
owner: myGithubUsername
---
github Configuration Spec Details
repository (required)
- Description: The name of the repository where EKS Anywhere will store your cluster configuration, and sync it to the cluster. If the repository exists, we will clone it from the git provider; if it does not exist, we will create it for you.
- Type: string
owner (required)
- Description: The owner of the Github repository; either a Github username or Github organization name. The Personal Access Token used must belong to the owner if this is a personal repository, or have permissions over the organization if this is not a personal repository.
- Type: string
personal (optional)
- Description: Is the repository a personal or organization repository?
If personal, this value is
true; otherwise,false. If using an organizational repository (e.g.personalisfalse) theownerfield will be used as theorganizationwhen authenticating to github.com - Default: true
- Type: boolean
Git provider
Before you create a cluster using the Git provider, you will need to set and export the EKSA_GIT_KNOWN_HOSTS and EKSA_GIT_PRIVATE_KEY environment variables.
EKSA_GIT_KNOWN_HOSTS
EKS Anywhere uses the provided known hosts file to verify the identity of the git provider when connecting to it with SSH.
The EKSA_GIT_KNOWN_HOSTS environment variable should be a path to a known hosts file containing entries for the git server to which you’ll be connecting.
For example, if you wanted to provide a known hosts file which allows you to connect to and verify the identity of github.com using a private key based on the key algorithm ecdsa, you can use the OpenSSH utility ssh-keyscan
to obtain the known host entry used by github.com for the ecdsa key type.
EKS Anywhere supports ecdsa, rsa, and ed25519 key types, which can be specified via the sshKeyAlgorithm field of the git provider config.
ssh-keyscan -t ecdsa github.com >> my_eksa_known_hosts
This will produce a file which contains known-hosts entries for the ecdsa key type supported by github.com, mapping the host to the key-type and public key.
github.com ecdsa-sha2-nistp256 AAAAE2VjZHNhLXNoYTItbmlzdHAyNTYAAAAIbmlzdHAyNTYAAABBBEmKSENjQEezOmxkZMy7opKgwFB9nkt5YRrYMjNuG5N87uRgg6CLrbo5wAdT/y6v0mKV0U2w0WZ2YB/++Tpockg=
EKS Anywhere will use the content of the file at the path EKSA_GIT_KNOWN_HOSTS to verify the identity of the remote git server, and the provided known hosts file must contain an entry for the remote host and key type.
EKSA_GIT_PRIVATE_KEY
The EKSA_GIT_PRIVATE_KEY environment variable should be a path to the private key file associated with a valid SSH public key registered with your Git provider.
This key must have permission to both read from and write to your repository.
The key can use the key algorithms rsa, ecdsa, and ed25519.
This key file must have restricted file permissions, allowing only the owner to read and write, such as octal permissions 600.
If your private key file is passphrase protected, you must also set EKSA_GIT_SSH_KEY_PASSPHRASE with that value.
This is a generic template with detailed descriptions below for reference:
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: Cluster
metadata:
name: my-cluster-name
namespace: default
spec:
...
#GitOps Support
gitOpsRef:
name: my-git-flux-provider
kind: FluxConfig
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: FluxConfig
metadata:
name: my-git-flux-provider
namespace: default
spec:
systemNamespace: "my-alternative-flux-system-namespace"
clusterConfigPath: "path-to-my-clusters-config"
branch: "main"
git:
repositoryUrl: ssh://git@github.com/myAccount/myClusterGitopsRepo.git
sshKeyAlgorithm: ecdsa
---
git Configuration Spec Details
repositoryUrl (required)
NOTE: The
repositoryUrlvalue for private SSH repositories is of the formatssh://git@provider.com/$REPO_OWNER/$REPO_NAME.git. This may differ from the default SSH URL given by your provider. For example, the github.com user interface provides an SSH URL containing a:before the repository owner, rather than a/. Make sure to replace this:with a/, if present.
- Description: The URL of an existing repository where EKS Anywhere will store your cluster configuration and sync it to the cluster. For private repositories, the SSH URL will be of the format
ssh://git@provider.com/$REPO_OWNER/$REPO_NAME.git - Type: string
sshKeyAlgorithm (optional)
- Description: The SSH key algorithm of the private key specified via
EKSA_PRIVATE_KEY_FILE. Defaults toecdsa - Type: string
Supported SSH key algorithm types are ecdsa, rsa, and ed25519.
Be sure that this SSH key algorithm matches the private key file provided by EKSA_GIT_PRIVATE_KEY_FILE and that the known hosts entry for the key type is present in EKSA_GIT_KNOWN_HOSTS.
GitOps Configuration
Warning
GitOps Config will be deprecated in v0.11.0 in lieu of using the Flux Config described above.Please note that for the GitOps config to work successfully the environment variable EKSA_GITHUB_TOKEN needs to be set with a valid GitHub PAT
. This is a generic template with detailed descriptions below for reference:
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: Cluster
metadata:
name: my-cluster-name
namespace: default
spec:
...
#GitOps Support
gitOpsRef:
name: my-gitops
kind: GitOpsConfig
---
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: GitOpsConfig
metadata:
name: my-gitops
namespace: default
spec:
flux:
github:
personal: true
repository: myClusterGitopsRepo
owner: myGithubUsername
fluxSystemNamespace: ""
clusterConfigPath: ""
GitOps Configuration Spec Details
flux (required)
- Description: our supported gitops provider is
flux. This is the only supported value. - Type: object
Flux Configuration Spec Details
github (required)
- Description:
githubis the only currently supported git provider. This defines your github configuration to be used by EKS Anywhere and flux. - Type: object
github Configuration Spec Details
repository (required)
- Description: The name of the repository where EKS Anywhere will store your cluster configuration, and sync it to the cluster. If the repository exists, we will clone it from the git provider; if it does not exist, we will create it for you.
- Type: string
owner (required)
- Description: The owner of the Github repository; either a Github username or Github organization name.
The Personal Access Token used must belong to the
ownerif this is apersonalrepository, or have permissions over the organization if this is not apersonalrepository. - Type: string
personal (optional)
- Description: Is the repository a personal or organization repository?
If personal, this value is
true; otherwise,false. If using an organizational repository (e.g.personalisfalse) theownerfield will be used as theorganizationwhen authenticating to github.com - Default:
true - Type: boolean
clusterConfigPath (optional)
- Description: The path relative to the root of the git repository where EKS Anywhere will store the cluster configuration files.
- Default:
clusters/$MANAGEMENT_CLUSTER_NAME - Type: string
fluxSystemNamespace (optional)
- Description: Namespace in which to install the gitops components in your cluster.
- Default:
flux-system. - Type: string
branch (optional)
- Description: The branch to use when committing the configuration.
- Default:
main - Type: string
1.6.8 - Proxy configuration
Proxy support (optional)
You can configure EKS Anywhere to use a proxy to connect to the Internet. This is the generic template with proxy configuration for your reference:
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: Cluster
metadata:
name: my-cluster-name
spec:
...
proxyConfiguration:
httpProxy: http-proxy-ip:port
httpsProxy: https-proxy-ip:port
noProxy:
- list of no proxy endpoints
Configuring Docker daemon
EKS Anywhere will proxy for you given the above configuration file. However, to successfully use EKS Anywhere you will also need to ensure your Docker daemon is configured to use the proxy.
This generally means updating your daemon to launch with the HTTPS_PROXY, HTTP_PROXY, and NO_PROXY environment variables.
For an example of how to do this with systemd, please see Docker’s documentation here .
Configuring EKS Anywhere proxy without config file
For commands using a cluster config file, EKS Anywhere will derive its proxy config from the cluster configuration file.
However, for commands that do not utilize a cluster config file, you can set the following environment variables:
export HTTPS_PROXY=https-proxy-ip:port
export HTTP_PROXY=http-proxy-ip:port
export NO_PROXY=no-proxy-domain.com,another-domain.com,localhost
Proxy Configuration Spec Details
proxyConfiguration (required)
- Description: top level key; required to use proxy.
- Type: object
httpProxy (required)
- Description: HTTP proxy to use to connect to the internet; must be in the format IP:port
- Type: string
- Example:
httpProxy: 192.168.0.1:3218
httpsProxy (required)
- Description: HTTPS proxy to use to connect to the internet; must be in the format IP:port
- Type: string
- Example:
httpsProxy: 192.168.0.1:3218
noProxy (optional)
- Description: list of endpoints that should not be routed through the proxy; can be an IP, CIDR block, or a domain name
- Type: list of strings
- Example
noProxy:
- localhost
- 192.168.0.1
- 192.168.0.0/16
- .example.com
1.6.9 - Registry Mirror configuration
Registry Mirror Support (optional)
You can configure EKS Anywhere to use a private registry as a mirror for pulling the required images.
The following cluster spec shows an example of how to configure registry mirror:
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: Cluster
metadata:
name: my-cluster-name
spec:
...
registryMirrorConfiguration:
endpoint: <private registry IP or hostname>
port: <private registry port>
ociNamespaces:
- registry: <upstream registry IP or hostname>
namespace: <namespace in private registry>
...
caCertContent: |
-----BEGIN CERTIFICATE-----
MIIF1DCCA...
...
es6RXmsCj...
-----END CERTIFICATE-----
Registry Mirror Configuration Spec Details
registryMirrorConfiguration (required)
- Description: top level key; required to use a private registry.
- Type: object
endpoint (required)
- Description: IP address or hostname of the private registry for pulling images
- Type: string
- Example:
endpoint: 192.168.0.1
port (optional)
- Description: port for the private registry. This is an optional field. If a port
is not specified, the default HTTPS port
443is used - Type: string
- Example:
port: 443
ociNamespaces (optional)
- Description: mapping from upstream registries to the locations of the private registry. When specified, the artifacts pulled from an upstream registry will be put in its corresponding location/namespace in the private registry. The target location/namespace must be already existing.
- Type: array
- Example:
ociNamespaces: - registry: "public.ecr.aws" namespace: "eks-anywhere" - registry: "783794618700.dkr.ecr.us-west-2.amazonaws.com" namespace: "curated-packages"
caCertContent (optional)
-
Description: certificate Authority (CA) Certificate for the private registry . When using self-signed certificates it is necessary to pass this parameter in the cluster spec. This must be the individual public CA cert used to sign the registry certificate. This will be added to the cluster nodes so that they are able to pull images from the private registry.
It is also possible to configure CACertContent by exporting an environment variable:
export EKSA_REGISTRY_MIRROR_CA="/path/to/certificate-file" -
Type: string
-
Example:
CACertContent: | -----BEGIN CERTIFICATE----- MIIF1DCCA... ... es6RXmsCj... -----END CERTIFICATE-----
authenticate (optional)
- Description: optional field to authenticate with a private registry. When using private registries that
require authentication, it is necessary to set this parameter to
truein the cluster spec. - Type: boolean
- Example:
authenticate: true
To use an authenticated private registry, please also set the following environment variables:
export REGISTRY_USERNAME=<username>
export REGISTRY_PASSWORD=<password>
insecureSkipVerify (optional)
- Description: optional field to skip the registry certificate verification. Only use this solution for isolated testing or in a tightly controlled, air-gapped environment. Currently only supported for Ubuntu OS.
- Type: boolean
Import images into a private registry
You can use the download images and import images commands to pull images from public.ecr.aws and push them to your
private registry.
The copy packages must be used if you want to copy EKS Anywhere Curated Packages to your registry mirror.
The download images command also pulls the cilium chart from public.ecr.aws and pushes it to the registry mirror. It requires the registry credentials for performing a login. Set the following environment variables for the login:
export REGISTRY_ENDPOINT=<registry_endpoint>
export REGISTRY_USERNAME=<username>
export REGISTRY_PASSWORD=<password>
Download the EKS Anywhere artifacts to get the EKS Anywhere bundle:
eksctl anywhere download artifacts
tar -xzf eks-anywhere-downloads.tar.gz
Download and import EKS Anywhere images:
eksctl anywhere download images -o eks-anywhere-images.tar
docker login https://${REGISTRY_ENDPOINT}
...
eksctl anywhere import images -i eks-anywhere-images.tar --bundles eks-anywhere-downloads/bundle-release.yaml --registry ${REGISTRY_ENDPOINT}
Use the EKS Anywhere bundle to copy packages:
eksctl anywhere copy packages --bundle ./eks-anywhere-downloads/bundle-release.yaml --dst-cert rootCA.pem ${REGISTRY_ENDPOINT}
Docker configurations
It is necessary to add the private registry’s CA Certificate to the list of CA certificates on the admin machine if your registry uses self-signed certificates.
For Linux
, you can place your certificate here: /etc/docker/certs.d/<private-registry-endpoint>/ca.crt
For Mac , you can follow this guide to add the certificate to your keychain: https://docs.docker.com/desktop/mac/#add-tls-certificates
Note
You may need to restart Docker after adding the certificates.Registry configurations
Depending on what registry you decide to use, you will need to create the following projects:
bottlerocket
eks-anywhere
eks-distro
isovalent
cilium-chart
For example, if a registry is available at private-registry.local, then the following
projects will have to be created:
https://private-registry.local/bottlerocket
https://private-registry.local/eks-anywhere
https://private-registry.local/eks-distro
https://private-registry.local/isovalent
https://private-registry.local/cilium-chart
1.6.10 - Package controller configuration
Package Controller Configuration (optional)
You can configure EKS Anywhere controller configuration.
The following cluster spec shows an example of how to configure registry mirror:
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: Cluster
metadata:
name: my-cluster-name
spec:
...
packages:
disable: false
controller:
resources:
requests:
cpu: 100m
memory: 50Mi
limits:
cpu: 750m
memory: 450Mi
Package Controller Configuration Spec Details
packages (optional)
- Description: Top level key; required controller configuration.
- Type: object
packages.disable (optional)
- Description: Disable the package controller.
- Type: bool
- Example:
disable: true
packages.controller (optional)
- Description: Disable the package controller.
- Type: object
packages.controller.resources (optional)
- Description: Resources for the package controller.
- Type: object
packages.controller.resources.limits (optional)
- Description: Resource limits.
- Type: object
packages.controller.resources.limits.cpu (optional)
- Description: CPU limit.
- Type: string
packages.controller.resources.limits.memory (optional)
- Description: Memory limit.
- Type: string
packages.controller.resources.requests (optional)
- Description: Requested resources.
- Type: object
packages.controller.resources.requests.cpu (optional)
- Description: Requested cpu.
- Type: string
packages.controller.resources.limits.memory (optional)
- Description: Requested memory.
- Type: string
packages.cronjob (optional)
- Description: Disable the package controller.
- Type: object
packages.cronjob.disable (optional)
- Description: Disable the cron job.
- Type: bool
- Example:
disable: true
packages.cronjob.resources (optional)
- Description: Resources for the package controller.
- Type: object
packages.cronjob.resources.limits (optional)
- Description: Resource limits.
- Type: object
packages.cronjob.resources.limits.cpu (optional)
- Description: CPU limit.
- Type: string
packages.cronjob.resources.limits.memory (optional)
- Description: Memory limit.
- Type: string
packages.cronjob.resources.requests (optional)
- Description: Requested resources.
- Type: object
packages.cronjob.resources.requests.cpu (optional)
- Description: Requested cpu.
- Type: string
packages.cronjob.resources.limits.memory (optional)
- Description: Requested memory.
- Type: string
2 - Bare Metal
2.1 - Requirements for EKS Anywhere on Bare Metal
To run EKS Anywhere on Bare Metal, you need to meet the hardware and networking requirements described below.
Administrative machine
Set up an Administrative machine as described in Install EKS Anywhere .
Compute server requirements
The minimum number of physical machines needed to run EKS Anywhere on bare metal is 1. To configure EKS Anywhere to run on a single server, set controlPlaneConfiguration.count to 1, and omit workerNodeGroupConfigurations from your cluster configuration.
The recommended number of physical machines for production is at least:
- Control plane physical machines: 3
- Worker physical machines: 2
The compute hardware you need for your Bare Metal cluster must meet the following capacity requirements:
- vCPU: 2
- Memory: 8GB RAM
- Storage: 25GB
Upgrade requirements
If you are running a standalone cluster with only one control plane node, you will need at least one additional, temporary machine for each control plane node grouping. For cluster with multiple control plane nodes, you can perform a rolling upgrade with or without an extra temporary machine. For worker node upgrades, you can perform a rolling upgrade with or without an extra temporary machine.
When upgrading without an extra machine, keep in mind that your control plane and your workload must be able to tolerate node unavailability. When upgrading with extra machine(s), you will need additional temporary machine(s) for each control plane and worker node grouping. Refer to Upgrade Bare Metal Cluster and Advanced configuration for rolling upgrade .
NOTE: For single node clusters that require an additional temporary machine for upgrading, if you don’t want to set up the extra hardware, you may recreate the cluster for upgrading and handle data recovery manually.
Network requirements
Each machine should include the following features:
- Network Interface Cards: At least one NIC is required. It must be capable of network booting.
- BMC integration (recommended): An IPMI or Redfish implementation (such a Dell iDRAC, RedFish-compatible, legacy or HP iLO) on the computer’s motherboard or on a separate expansion card. This feature is used to allow remote management of the machine, such as turning the machine on and off.
NOTE: BMC integration is not required for an EKS Anywhere cluster. However, without BMC integration, upgrades are not supported and you will have to physically turn machines off and on when appropriate.
Here are other network requirements:
-
All EKS Anywhere machines, including the Admin, control plane and worker machines, must be on the same layer 2 network and have network connectivity to the BMC (IPMI, Redfish, and so on).
-
You must be able to run DHCP on the control plane/worker machine network.
NOTE:: If you have another DHCP service running on the network, you need to prevent it from interfering with the EKS Anywhere DHCP service. You can do that by configuring the other DHCP service to explicitly block all MAC addresses and exclude all IP addresses that you plan to use with your EKS Anywhere clusters.
-
The administrative machine and the target workload environment will need network access to:
- public.ecr.aws
- anywhere-assets.eks.amazonaws.com: To download the EKS Anywhere binaries, manifests and OVAs
- distro.eks.amazonaws.com: To download EKS Distro binaries and manifests
- d2glxqk2uabbnd.cloudfront.net: For EKS Anywhere and EKS Distro ECR container images
-
Two IP addresses routable from the cluster, but excluded from DHCP offering. One IP address is to be used as the Control Plane Endpoint IP. The other is for the Tinkerbell IP address on the target cluster. Below are some suggestions to ensure that these IP addresses are never handed out by your DHCP server. You may need to contact your network engineer to manage these addresses.
- Pick IP addresses reachable from the cluster subnet that are excluded from the DHCP range or
- Create an IP reservation for these addresses on your DHCP server. This is usually accomplished by adding a dummy mapping of this IP address to a non-existent mac address.
NOTE: When you set up your cluster configuration YAML file, the endpoint and Tinkerbell addresses are set in the
ControlPlaneConfiguration.endpoint.hostandtinkerbellIPfields, respectively.
- Ports must be open to the Admin machine and cluster machines as described in Ports and protocols .
Validated hardware
Through extensive testing in a variety of on premises customer environments during our beta phase, we expect Amazon EKS Anywhere on bare metal to run on most generic hardware that meets the above requirements. In addition, we have collaborated with our hardware original equipment manufacturer (OEM) partners to provide you a list of validated hardware:
| Bare metal servers | BMC | NIC | OS |
|---|---|---|---|
| Dell PowerEdge R740 | iDRAC9 | Mellanox ConnectX-4 LX 25GbE | Validated with Ubuntu v20.04.1 |
| Dell PowerEdge R7525 (NVIDIA Tesla™ T4 GPU’s) | iDRAC9 | Mellanox ConnectX-4 LX 25GbE & Intel Ethernet 10G 4P X710 OCP | Validated with Ubuntu v20.04.1 |
| Dell PowerFlex (R640) | iDRAC9 | Mellanox ConnectX-4 LX 25GbE | Validated with Ubuntu v20.04.1 |
| SuperServer SYS-510P-M | IPMI2.0/Redfish API | Intel® Ethernet Controller i350 2x 1GbE | Validated with Ubuntu v20.04.1 and Bottlerocket v1.8.0 |
| Dell PowerEdge R240 | iDRAC9 | Broadcom 57414 Dual Port 10/25GbE | Validated with Ubuntu v20.04 and Bottlerocket v1.8.0 |
| HPE ProLiant DL20 | iLO5 | HPE 361i 1G | Validated with Ubuntu v20.04 and Bottlerocket v1.8.0 |
| HPE ProLiant DL160 Gen10 | iLO5 | HPE Eth 10/25Gb 2P 640SFP28 A | Validated with Ubuntu v20.04.1 |
| Dell PowerEdge R340 | iDRAC9 | Broadcom 57416 Dual Port 10GbE | Validated with Ubuntu v20.04.1 and Bottlerocket v1.8.0 |
| HPE ProLiant DL360 | iLO5 | HPE Ethernet 1Gb 4-port 331i | Validated with Ubuntu v20.04.1 |
| Lenovo ThinkSystem SR650 V2 | XClarity Controller Enterprise v7.92 |
|
Validated with Ubuntu v20.04.1 |
2.2 - Preparing Bare Metal for EKS Anywhere
After gathering hardware described in Bare Metal Requirements , you need to prepare the hardware and create a CSV file describing that hardware.
Prepare hardware
To prepare your computer hardware for EKS Anywhere, you need to connect your computer hardware and do some configuration. Once the hardware is in place, you need to:
- Obtain IP and MAC addresses for your machines' NICs.
- Obtain IP addresses for your machines' BMC interfaces.
- Obtain the gateway address for your network to reach the Internet.
- Obtain the IP address for your DNS servers.
- Make sure the following settings are in place:
- UEFI is enabled on all target cluster machines, unless you are provisioning RHEL systems. Enable legacy BIOS on any RHEL machines.
- Netboot (PXE or HTTP) boot is enabled for the NIC on each machine for which you provided the MAC address. This is the interface on which the operating system will be provisioned.
- IPMI over LAN and/or Redfish is enabled on all BMC interfaces.
- Go to the BMC settings for each machine and set the IP address (bmc_ip), username (bmc_username), and password (bmc_password) to use later in the CSV file.
Prepare hardware inventory
Create a CSV file to provide information about all physical machines that you are ready to add to your target Bare Metal cluster. This file will be used:
- When you generate the hardware file to be included in the cluster creation process described in the Create Bare Metal production cluster Getting Started guide.
- To provide information that is passed to each machine from the Tinkerbell DHCP server when the machine is initially network booted.
The following is an example of an EKS Anywhere Bare Metal hardware CSV file:
hostname,bmc_ip,bmc_username,bmc_password,mac,ip_address,netmask,gateway,nameservers,labels,disk
eksa-cp01,10.10.44.1,root,PrZ8W93i,CC:48:3A:00:00:01,10.10.50.2,255.255.254.0,10.10.50.1,8.8.8.8|8.8.4.4,type=cp,/dev/sda
eksa-cp02,10.10.44.2,root,Me9xQf93,CC:48:3A:00:00:02,10.10.50.3,255.255.254.0,10.10.50.1,8.8.8.8|8.8.4.4,type=cp,/dev/sda
eksa-cp03,10.10.44.3,root,Z8x2M6hl,CC:48:3A:00:00:03,10.10.50.4,255.255.254.0,10.10.50.1,8.8.8.8|8.8.4.4,type=cp,/dev/sda
eksa-wk01,10.10.44.4,root,B398xRTp,CC:48:3A:00:00:04,10.10.50.5,255.255.254.0,10.10.50.1,8.8.8.8|8.8.4.4,type=worker,/dev/sda
eksa-wk02,10.10.44.5,root,w7EenR94,CC:48:3A:00:00:05,10.10.50.6,255.255.254.0,10.10.50.1,8.8.8.8|8.8.4.4,type=worker,/dev/sda
The CSV file is a comma-separated list of values in a plain text file, holding information about the physical machines in the datacenter that are intended to be a part of the cluster creation process. Each line represents a physical machine (not a virtual machine).
The following sections describe each value.
hostname
The hostname assigned to the machine.
bmc_ip (optional)
The IP address assigned to the BMC interface on the machine.
bmc_username (optional)
The username assigned to the BMC interface on the machine.
bmc_password (optional)
The password associated with the bmc_username assigned to the BMC interface on the machine.
mac
The MAC address of the network interface card (NIC) that provides access to the host computer.
ip_address
The IP address providing access to the host computer.
netmask
The netmask associated with the ip_address value.
In the example above, a /23 subnet mask is used, allowing you to use up to 510 IP addresses in that range.
gateway
IP address of the interface that provides access (the gateway) to the Internet.
nameservers
The IP address of the server that you want to provide DNS service to the cluster.
labels
The optional labels field can consist of a key/value pair to use in conjunction with the hardwareSelector field when you set up your Bare Metal configuration
.
The key/value pair is connected with an equal (=) sign.
For example, a TinkerbellMachineConfig with a hardwareSelector containing type: cp will match entries in the CSV containing type=cp in its label definition.
disk
The device name of the disk on which the operating system will be installed.
For example, it could be /dev/sda for the first SCSI disk or /dev/nvme0n1 for the first NVME storage device.
2.3 - Netbooting and Tinkerbell for Bare Metal
EKS Anywhere uses Tinkerbell to provision machines for a Bare Metal cluster. Understanding what Tinkerbell is and how it works with EKS Anywhere can help you take advantage of advanced provisioning features or overcome provisioning problems you encounter.
As someone deploying an EKS Anywhere cluster on Bare Metal, you have several opportunities to interact with Tinkerbell:
- Create a hardware CSV file: You are required to create a hardware CSV file that contains an entry for every physical machine you want to add at cluster creation time.
- Create an EKS Anywhere cluster: By modifying the Bare Metal configuration file used to create a cluster, you can change some Tinkerbell settings or add actions to define how the operating system on each machine is configured.
- Monitor provisioning: You can follow along with the Tinkerbell Overview in this page to monitor the progress of your hardware provisioning, as Tinkerbell finds machines and attempts to network boot, configure, and restart them.
Using Tinkerbell on EKS Anywhere
The sections below step through how Tinkerbell is integrated with EKS Anywhere to deploy a Bare Metal cluster. While based on features described in Tinkerbell Documentation , EKS Anywhere has modified and added to Tinkerbell components such that the entire Tinkerbell stack is now Kubernetes-friendly and can run on a Kubernetes cluster.
Create bare metal CSV file
The information that Tinkerbell uses to provision machines for the target EKS Anywhere cluster needs to be gathered in a CSV file with the following format:
hostname,bmc_ip,bmc_username,bmc_password,mac,ip_address,netmask,gateway,nameservers,labels,disk
eksa-cp01,10.10.44.1,root,PrZ8W93i,CC:48:3A:00:00:01,10.10.50.2,255.255.254.0,10.10.50.1,8.8.8.8,type=cp,/dev/sda
...
Each physical, bare metal machine is represented by a comma-separated list of information on a single line. It includes information needed to identify each machine (the NIC’s MAC address), network boot the machine, point to the disk to install on, and then configure and start the installed system. See Preparing hardware inventory for details on the content and format of that file.
Modify the cluster specification file
Before you create a cluster using the Bare Metal configuration file, you can make Tinkerbell-related changes to that file. In particular, TinkerbellDatacenterConfig fields , TinkerbellMachineConfig fields , and Tinkerbell Actions can be added or modified.
Tinkerbell actions vary based on the operating system you choose for your EKS Anywhere cluster. Actions are stored internally and not shown in the generated cluster specification file, so you must add those sections yourself to change from the defaults (see Ubuntu TinkerbellTemplateConfig example and Bottlerocket TinkerbellTemplateConfig example for details).
In most cases, you don’t need to touch the default actions.
However, you might want to modify an action (for example to change kexec to a reboot action if the hardware requires it) or add an action to further configure the installed system.
Examples in Advanced Bare Metal cluster configuration
show a few actions you might want to add.
Once you have made all your modifications, you can go ahead and create the cluster. The next section describes how Tinkerbell works during cluster creation to provision your Bare Metal machines and prepare them to join the EKS Anywhere cluster.
Overview of Tinkerbell in EKS Anywhere
When you run the command to create an EKS Anywhere Bare Metal cluster, a set of Tinkerbell components start up on the Admin machine. One of these components runs in a container on Docker, while other components run as either controllers or services in pods on the Kubernetes kind cluster that is started up on the Admin machine. Tinkerbell components include Boots, Hegel, Rufio, and Tink.
Tinkerbell Boots service
The Boots service runs in a single container to handle the DHCP service and network booting activities. In particular, Boots hands out IP addresses, serves iPXE binaries via HTTP and TFTP, delivers an iPXE script to the provisioned machines, and runs a syslog server.
Boots is different from the other Tinkerbell services because the DHCP service it runs must listen directly to layer 2 traffic. (The kind cluster running on the Admin machine doesn’t have the ability to have pods listening on layer 2 networks, which is why Boots is run directly on Docker instead, with host networking enabled.)
Because Boots is running as a container in Docker, you can see the output in the logs for the Boots container by running:
docker logs boots
From the logs output, you will see iPXE try to network boot each machine. If the process doesn’t get all the information it wants from the DHCP server, it will time out. You can see iPXE loading variables, loading a kernel and initramfs (via DHCP), then booting into that kernel and initramfs: in other words, you will see everything that happens with iPXE before it switches over to the kernel and initramfs. The kernel, initramfs, and all images retrieved later are obtained remotely over HTTP and HTTPS.
Tinkerbell Hegel, Rufio, and Tink components
After Boots comes up on Docker, a small Kubernetes kind cluster starts up on the Admin machine. Other Tinkerbell components run as pods on that kind cluster. Those components include:
- Hegel: Manages Tinkerbell’s metadata service. The Hegel service gets its metadata from the hardware specification stored in Kubernetes in the form of custom resources. The format that it serves is similar to an Ec2 metadata format.
- Rufio: Handles talking to BMCs (which manages things like starting and stopping systems with IPMI or Redfish). The Rufio Kubernetes controller sets things such as power state, persistent boot order. BMC authentication is managed with Kubernetes secrets.
- Tink: The Tink service consists of three components: Tink server, Tink controller, and Tink worker. The Tink controller manages hardware data, templates you want to execute, and the workflows that each target specific hardware you are provisioning. The Tink worker is a small binary that runs inside of HookOS and talks to the Tink server. The worker sends the Tink server its MAC address and asks the server for workflows to run. The Tink worker will then go through each action, one-by-one, and try to execute it.
To see those services and controllers running on the kind bootstrap cluster, type:
kubectl get pods -n eksa-system
NAME READY STATUS RESTARTS AGE
hegel-sbchp 1/1 Running 0 3d
rufio-controller-manager-5dcc568c79-9kllz 1/1 Running 0 3d
tink-controller-manager-54dc786db6-tm2c5 1/1 Running 0 3d
tink-server-5c494445bc-986sl 1/1 Running 0 3d
Provisioning hardware with Tinkerbell
After you start up the cluster create process, the following is the general workflow that Tinkerbell performs to begin provisioning the bare metal machines and prepare them to become part of the EKS Anywhere target cluster. You can set up kubectl on the Admin machine to access the bootstrap cluster and follow along:
export KUBECONFIG=${PWD}/${CLUSTER_NAME}/generated/${CLUSTER_NAME}.kind.kubeconfig
Power up the nodes
Tinkerbell starts by finding a node from the hardware list (based on MAC address) and contacting it to identify a baseboard management job (job.bmc) that runs a set of baseboard management tasks (task.bmc).
To see that information, type:
kubectl get job.bmc -A
NAMESPACE NAME AGE
eksa-system mycluster-md-0-1656099863422-vxvh2-provision 12m
kubectl get tasks.bmc -A
NAMESPACE NAME AGE
eksa-system mycluster-md-0-1656099863422-vxh2-provision-task-0 55s
eksa-system mycluster-md-0-1656099863422-vxh2-provision-task-1 51s
eksa-system mycluster-md-0-1656099863422-vxh2-provision-task-2 47s
The following shows snippets from the tasks.bmc output that represent the three tasks: Power Off, enable network boot, and Power On.
kubectl describe tasks.bmc -n eksa-system eksa-system mycluster-md-0-1656099863422-vxh2-provision-task-0
...
Task:
Power Action: Off
Status:
Completion Time: 2022-06-27T20:32:59Z
Conditions:
Status: True
Type: Completed
kubectl describe tasks.bmc -n eksa-system eksa-system mycluster-md-0-1656099863422-vxh2-provision-task-1
...
Task:
One Time Boot Device Action:
Device:
pxe
Efi Boot: true
Status:
Completion Time: 2022-06-27T20:33:04Z
Conditions:
Status: True
Type: Completed
kubectl describe tasks.bmc -n eksa-system eksa-system mycluster-md-0-1656099863422-vxh2-provision-task-2
Task:
Power Action: on
Status:
Completion Time: 2022-06-27T20:33:10Z
Conditions:
Status: True
Type: Completed
Rufio converts the baseboard management jobs into task objects, then goes ahead and executes each task. To see Rufio logs, type:
kubectl logs -n eksa-system rufio-controller-manager-5dcc568c79-9kllz | less
Network booting the nodes
Next the Boots service netboots the machine and begins streaming the HookOS (vmlinuz and initramfs) to the machine.
HookOS runs in memory and provides the installation environment.
To watch the Boots log messages as each node powers up, type:
docker logs boots
You can search the output for vmlinuz and initramfs to watch as the HookOS is downloaded and booted from memory on each machine.
Running workflows
Once the HookOS is up, Tinkerbell begins running the tasks and actions contained in the workflows. This is coordinated between the Tink worker, running in memory within the HookOS on the machine, and the Tink server on the kind cluster. To see the workflows being run, type the following:
kubectl get workflows.tinkerbell.org -n eksa-system
NAME TEMPLATE STATE
mycluster-md-0-1656099863422-vxh2 mycluster-md-0-1656099863422-vxh2 STATE_RUNNING
This shows the workflow for the first machine that is being provisioned.
Add -o yaml to see details of that workflow template:
kubectl get workflows.tinkerbell.org -n eksa-system -o yaml
...
status:
state: STATE_RUNNING
tasks:
- actions
- environment:
COMPRESSED: "true"
DEST_DISK: /dev/sda
IMG_URL: https://anywhere-assets.eks.amazonaws.com/releases/bundles/11/artifacts/raw/1-22/bottlerocket-v1.22.10-eks-d-1-22-8-eks-a-11-amd64.img.gz
image: public.ecr.aws/eks-anywhere/tinkerbell/hub/image2disk:6c0f0d437bde2c836d90b000312c8b25fa1b65e1-eks-a-15
name: stream-image
seconds: 35
startedAt: "2022-06-27T20:37:39Z"
status: STATE_SUCCESS
...
You can see that the first action in the workflow is to stream (stream-image) the operating system to the destination disk (DEST_DISK) on the machine.
In this example, the Bottlerocket operating system that will be copied to disk (/dev/sda) is being served from the location specified by IMG_URL.
The action was successful (STATE_SUCCESS) and it took 35 seconds.
Each action and its status is shown in this output for the whole workflow. To see details of the default actions for each supported operating system, see the Ubuntu TinkerbellTemplateConfig example and Bottlerocket TinkerbellTemplateConfig example .
In general, the actions include:
- Streaming the operating system image to disk on each machine.
- Configuring the network interfaces on each machine.
- Setting up the cloud-init or similar service to add users and otherwise configure the system.
- Identifying the data source to add to the system.
- Setting the kernel to pivot to the installed system (using kexec) or having the system reboot to bring up the installed system from disk.
If all goes well, you will see all actions set to STATE_SUCCESS, except for the kexec-image action. That should show as STATE_RUNNING for as long as the machine is running.
You can review the CAPT logs to see provisioning activity. For example, at the start of a new provisioning event, you would see something like the following:
kubectl logs -n capt-system capt-controller-manager-9f8b95b-frbq | less
..."Created BMCJob to get hardware ready for provisioning"...
You can follow this output to see the machine as it goes through the provisioning process.
After the node is initialized, completes all the Tinkerbell actions, and is booted into the installed operating system (Ubuntu or Bottlerocket), the new system starts cloud-init to do further configuration. At this point, the system will reach out to the Tinkerbell Hegel service to get its metadata.
If something goes wrong, viewing Hegel files can help you understand why a stuck system that has booted into Ubuntu or Bottlerocket has not joined the cluster yet. To see the Hegel logs, get the internal IP address for one of the new nodes. Then check for the names of Hegel logs and display the contents of one of those logs, searching for the IP address of the node:
kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP ...
eksa-da04 Ready control-plane,master 9m5s v1.22.10-eks-7dc61e8 10.80.30.23
kubectl get logs -n eksa-system | grep hegel
hegel-n7ngs
kubectl logs -n eksa-system hegel-n7ngs
..."Retrieved IP peer IP..."userIP":"10.80.30.23...
If the log shows you are getting requests from the node, the problem is not a cloud-init issue.
After the first machine successfully completes the workflow, each other machine repeats the same process until the initial set of machines is all up and running.
Tinkerbell moves to target cluster
Once the initial set of machines is up and the EKS Anywhere cluster is running, all the Tinkerbell services and components (including Boots) are moved to the new target cluster and run as pods on that cluster. Those services are deleted on the kind cluster on the Admin machine.
Reviewing the status
At this point, you can change your kubectl credentials to point at the new target cluster to get information about Tinkerbell services on the new cluster. For example:
export KUBECONFIG=${PWD}/${CLUSTER_NAME}/${CLUSTER_NAME}-eks-a-cluster.kubeconfig
First check that the Tinkerbell pods are all running by listing pods from the eksa-system namespace:
kubectl get pods -n eksa-system
NAME READY STATUS RESTARTS AGE
boots-5dc66b5d4-klhmj 1/1 Running 0 3d
hegel-sbchp 1/1 Running 0 3d
rufio-controller-manager-5dcc568c79-9kllz 1/1 Running 0 3d
tink-controller-manager-54dc786db6-tm2c5 1/1 Running 0 3d
tink-server-5c494445bc-986sl 1/1 Running 0 3d
Next, check the list of Tinkerbell machines.
If all of the machines were provisioned successfully, you should see true under the READY column for each one.
kubectl get tinkerbellmachine -A
NAMESPACE NAME CLUSTER STATE READY INSTANCEID MACHINE
eksa-system mycluster-control-plane-template-1656099863422-pqq2q mycluster true tinkerbell://eksa-system/eksa-da04 mycluster-72p72
You can also check the machines themselves. Watch the PHASE change from Provisioning to Provisioned to Running. The Running phase indicates that the machine is now running as a node on the new cluster:
kubectl get machines -n eksa-system
NAME CLUSTER NODENAME PROVIDERID PHASE AGE VERSION
mycluster-72p72 mycluster eksa-da04 tinkerbell://eksa-system/eksa-da04 Running 7m25s v1.22.10-eks-1-22-8
Once you have confirmed that all your machines are successfully running as nodes on the target cluster, there is not much for Tinkerbell to do. It stays around to continue running the DHCP service and to be available to add more machines to the cluster.
2.4 - Customize HookOS for EKS Anywhere on Bare Metal
To initially network boot bare metal machines used in EKS Anywhere clusters, Tinkerbell acquires a kernel and initial ramdisk that is referred to as the HookOS. A default HookOS is provided when you create an EKS Anywhere cluster. However, there may be cases where you want to override the default HookOS, such as to add drivers required to boot your particular type of hardware.
The following procedure describes how to get the Tinkerbell stack’s Hook/Linuxkit OS built locally. For more information on Tinkerbell’s Hook Installation Environment, see the Tinkerbell Hook repo .
-
Clone the hook repo or your fork of that repo:
git clone https://github.com/tinkerbell/hook.git cd hook/ -
Pull down the commit that EKS Anywhere is tracking for Hook:
git checkout -b <new-branch> 03a67729d895635fe3c612e4feca3400b9336cc9NOTE: This commit number can be obtained from the EKS-A build tooling repo .
-
Make changes shown in the following
diffin theMakefilelocated in the root of the repo using your favorite editor.diff --git a/Makefile b/Makefile index e7fd844..8e87c78 100644 --- a/Makefile +++ b/Makefile @@ -2,7 +2,7 @@ ### !!NOTE!! # If this is changed then a fresh output dir is required (`git clean -fxd` or just `rm -rf out`) # Handling this better shows some of make's suckiness compared to newer build tools (redo, tup ...) where the command lines to tools invoked isn't tracked by make -ORG := quay.io/tinkerbell +ORG := localhost:5000/tinkerbell # makes sure there's no trailing / so we can just add them in the recipes which looks nicer ORG := $(shell echo "${ORG}" | sed 's|/*$$||')Changes above change the ORG variable to use a local registry (
localhost:5000) -
Make changes shown in the following
diffin therules.mklocated in the root of the repo using your favorite editor.diff --git a/rules.mk b/rules.mk index b2c5133..64e32b1 100644 --- a/rules.mk +++ b/rules.mk @@ -22,7 +22,7 @@ ifeq ($(ARCH),aarch64) ARCH = arm64 endif -arches := amd64 arm64 +arches := amd64 modes := rel dbg hook-bootkit-deps := $(wildcard hook-bootkit/*) @@ -87,13 +87,12 @@ push-hook-bootkit push-hook-docker: docker buildx build --platform $$platforms --push -t $(ORG)/$(container):$T $(container) .PHONY: dist -dist: out/$T/rel/amd64/hook.tar out/$T/rel/arm64/hook.tar ## Build tarballs for distribution +dist: out/$T/rel/amd64/hook.tar ## Build tarballs for distribution dbg-dist: out/$T/dbg/$(ARCH)/hook.tar ## Build debug enabled tarball dist dbg-dist: for f in $^; do case $$f in *amd64*) arch=x86_64 ;; - *arm64*) arch=aarch64 ;; *) echo unknown arch && exit 1;; esac d=$$(dirname $$(dirname $$f))Above changes are for the
docker buildcommand to only build for the immediately required platform (amd64 in this case) to save time. -
Modify the
hook.yamlfile located in the root of the repo with the following changes:diff --git a/hook.yaml b/hook.yaml index 0c5d789..b51b35e 100644 net: host --- a/hook.yaml +++ b/hook.yaml @@ -1,5 +1,5 @@ kernel: - image: quay.io/tinkerbell/hook-kernel:5.10.85 (http://quay.io/tinkerbell/hook-kernel:5.10.85) + image: localhost:5000/tinkerbell/hook-kernel:5.10.85 cmdline: "console=tty0 console=ttyS0 console=ttyAMA0 console=ttysclp0" init: - linuxkit/init:v0.8 @@ -42,7 +42,7 @@ services: binds: - /var/run:/var/run - name: docker - image: quay.io/tinkerbell/hook-docker:0.0 (http://quay.io/tinkerbell/hook-docker:0.0) + image: localhost:5000/tinkerbell/hook-docker:0.0 capabilities: - all net: host @@ -64,7 +64,7 @@ services: - /var/run/docker - /var/run/worker - name: bootkit - image: quay.io/tinkerbell/hook-bootkit:0.0 (http://quay.io/tinkerbell/hook-bootkit:0.0) + image: localhost:5000/tinkerbell/hook-bootkit:0.0 capabilities: - allThe changes above are for using local registry (localhost:5000) for hook-docker, hook-bootkit, and hook-kernel.
NOTE: You may also need to modify the
hook.yamlfile if you want to add or change components that are used to build up the image. So far, for example, we have needed to change versions ofinitandgettyand inject SSH keys. Take a look at the LinuxKit Examples site for examples. -
Make any planned custom modifications to the files under
hook, if you are only making changes tobootkitortink-docker. -
If you are modifying the kernel, such as to change kernel config parameters to add or modify drivers, follow these steps:
- Change into kernel directory and make a local image for amd64 architecture:
cd kernel; make kconfig_amd64- Run the image
docker run --rm -ti -v $(pwd):/src:z quay.io/tinkerbell/kconfig- You can now navigate to the source code and run the UI for configuring the kernel:
cd linux-5-10 make menuconfig- Once you have changed the necessary kernel configuration parameters, copy the new configuration:
cp .config /src/config-5.10.x-x86_64Exit out of container into the repo’s kernel directory and run make:
/linux-5.10.85 # exit user1 % make -
Install Linuxkit based on instructions from the LinuxKit page.
-
Ensure that the
linuxkittool is in your PATH:export PATH=$PATH:/home/tink/linuxkit/bin -
Start a local registry:
docker run -d -p 5000:5000 -—name registry registry:2 -
Compile by running the following in the root of the repo:
make dist -
Artifacts will be put under the
distdirectory in the repo’s root:./initramfs-aarch64 ./initramfs-x86_64 ./vmlinuz-aarch64 ./vmlinuz-x86_64 -
To use the kernel (
vmlinuz) and initial ram disk (initramfs) when you build your cluster, see the description of thehookImagesURLPathfield in your Bare Metal configuration file.
3 - CloudStack
3.1 - Requirements for EKS Anywhere on CloudStack
To run EKS Anywhere, you will need:
Prepare Administrative machine
Set up an Administrative machine as described in Install EKS Anywhere .
Prepare a CloudStack environment
To prepare a CloudStack environment to run EKS Anywhere, you need the following:
-
A CloudStack 4.14 or later environment. CloudStack 4.16 is used for examples in these docs.
-
Capacity to deploy 6-10 VMs.
-
One shared network in CloudStack to use for the cluster. EKS Anywhere clusters need access to CloudStack through the network to enable self-managing and storage capabilities.
-
A Red Hat Enterprise Linux qcow2 image built using the
image-buildertool as described in artifacts . -
User credentials (CloudStack API key and Secret key) to create VMs and attach networks in CloudStack.
-
One IP address routable from the cluster but excluded from DHCP offering. This IP address is to be used as the Control Plane Endpoint IP. Below are some suggestions to ensure that this IP address is never handed out by your DHCP server. You may need to contact your network engineer.
- Pick an IP address reachable from the cluster subnet which is excluded from DHCP range OR
- Alter DHCP ranges to leave out an IP address(s) at the top and/or the bottom of the range OR
- Create an IP reservation for this IP on your DHCP server. This is usually accomplished by adding a dummy mapping of this IP address to a non-existent mac address.
Each VM will require:
- 2 vCPUs
- 8GB RAM
- 25GB Disk
The administrative machine and the target workload environment will need network access to:
- CloudStack endpoint (must be accessible to EKS Anywhere clusters)
- public.ecr.aws
- anywhere-assets.eks.amazonaws.com (http://anywhere-assets.eks.amazonaws.com/ ) (to download the EKS Anywhere binaries and manifests)
- distro.eks.amazonaws.com (http://distro.eks.amazonaws.com/ ) (to download EKS Distro binaries and manifests)
- d2glxqk2uabbnd.cloudfront.net (http://d2glxqk2uabbnd.cloudfront.net/ ) (for EKS Anywhere and EKS Distro ECR container images)
- api.ecr.us-west-2.amazonaws.com (http://api.ecr.us-west-2.amazonaws.com/ ) (for EKS Anywhere package authentication matching your region)
- d5l0dvt14r5h8.cloudfront.net (http://d5l0dvt14r5h8.cloudfront.net/ ) (for EKS Anywhere package ECR container images)
- api.github.com (http://api.github.com/ ) (only if GitOps is enabled)
CloudStack information needed before creating the cluster
You need at least the following information before creating the cluster. See CloudStack configuration for a complete list of options and Preparing CloudStack for instructions on creating the assets.
- Static IP Addresses: You will need one IP address for the management cluster control plane endpoint, and a separate one for the controlplane of each workload cluster you add.
Let’s say you are going to have the management cluster and two workload clusters. For those, you would need three IP addresses, one for each. All of those addresses will be configured the same way in the configuration file you will generate for each cluster.
A static IP address will be used for each control plane VM in your EKS Anywhere cluster. Choose IP addresses in your network range that do not conflict with other VMs and make sure they are excluded from your DHCP offering. An IP address will be the value of the property controlPlaneConfiguration.endpoint.host in the config file of the management cluster. A separate IP address must be assigned for each workload cluster.
- CloudStack datacenter: You need the name of the CloudStack Datacenter plus the following for each Availability Zone (availabilityZones). Most items can be represented by name or ID:
- Account (account): Account with permission to create a cluster (optional, admin by default).
- Credentials (credentialsRef): Credentials provided in an ini file used to access the CloudStack API endpoint. See CloudStack Getting started for details.
- Domain (domain): The CloudStack domain in which to deploy the cluster (optional, ROOT by default)
- Management endpoint (managementApiEndpoint): Endpoint for a cloudstack client to make API calls to client.
- Zone network (zone.network): Either name or ID of the network.
- CloudStack machine configuration: For each set of machines (for example, you could configure separate set of machines for control plane, worker, and etcd nodes), obtain the following information. This must be predefined in the cloudStack instance and identified by name or ID:
- Compute offering (computeOffering): Choose an existing compute offering (such as
large-instance), reflecting the amount of resources to apply to each VM. - Operating system (template): Identifies the operating system image to use (such as rhel8-k8s-118).
- Users (users.name): Identifies users and SSH keys needed to access the VMs.
- Compute offering (computeOffering): Choose an existing compute offering (such as
3.2 - Preparing CloudStack for EKS Anywhere
Before you can create an EKS Anywhere cluster in CloudStack, you must do some setup on your CloudStack environment. This document helps you get what you need to fulfill the prerequisites described in the Requirements and values you need for CloudStack configuration .
Set up a domain and user credentials
Either use the ROOT domain or create a new domain to deploy your EKS Anywhere cluster. One or more users are grouped under a domain. This example creates a user account for the domain with a Domain Administrator role. From the apachecloudstack console:
-
Select Domains.
-
Select Add Domain.
-
Fill in the Name for the domain (
eksain this example) and select OK. -
Select Accounts -> Add Account, then fill in the form to add a user with
DomainAdminrole, as shown in the following figure: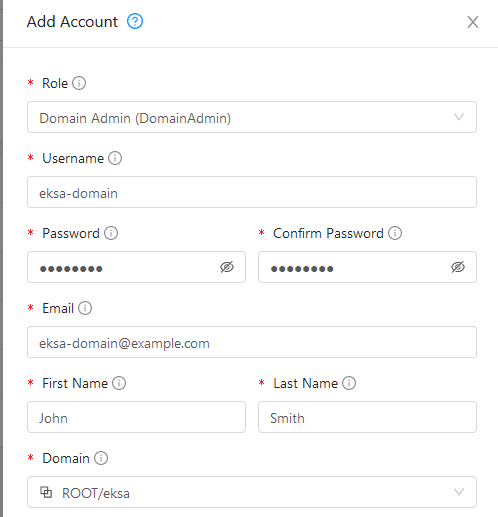
-
To generate API credentials for the user, select Accounts->
-> View Users -> and select the Generate Keys button. -
Select OK to confirm key generation. The API Key and Secret Key should appear as shown in the following figure:
-
Copy the API Key and Secret Key to a credentials file to use when you generate your cluster. For example:
[Global] api-url = http://10.0.0.2:8080/client/api api-key = OI7pm0xrPMYjLlMfqrEEj... secret-key = tPsgAECJwTHzbU4wMH...
Import template
You need to build at least one operating system image and import it as a template to use for your cluster nodes. Currently, only Red Hat Enterprise Linux 8 images are supported. To build a RHEL-based image to use with EKS Anywhere, see Build node images .
-
Make your image accessible from you local machine or from a URL that is accessible to your CloudStack setup.
-
Select Images -> Templates, then select either Register Template from URL or Select local Template. The following figure lets you register a template from URL:
This example imports a RHEL image (QCOW2), identifies the zone from which it will be available, uses KVM as the hypervisor, uses the osdefault Root disk controller, and identifies the OS Type as Red Hat Enterprise Linux 8.0. Select OK to save the template.
-
Note the template name and zone so you can use it later when you deploy your cluster.
Create CloudStack configurations
Take a look at the following CloudStack configuration settings before creating your EKS Anywhere cluster. You will need to identify many of these assets when you create you cluster specification:
DatacenterConfig information
Here is how to get information to go into the CloudStackDatacenterConfig section of the CloudStack cluster configuration file:
-
Domain: Select Domains, then select your domain name from under the ROOT domain. Select View Users, not the user with the Domain Admin role, and consider setting limits to what each user can consume from the Resources and Configure Limits tabs.
-
Zones: Select Infrastructure -> Zones. Find a Zone where you can deploy your cluster or create a new one.
-
Network: Select Network -> Guest networks. Choose a network to use for your cluster or create a new one.
Here is what some of that information would look like in a cluster configuration:
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: CloudStackDatacenterConfig
metadata:
name: my-cluster-name-datacenter
spec:
availabilityZones:
- account: admin
credentialsRef: global
domain: eksa
managementApiEndpoint: ""
name: az-1
zone:
name: Zone2
network:
name: "SharedNet2"
MachineConfig information
Here is how to get information to go into CloudStackMachineConfig sections of the CloudStack cluster configuration file:
-
computeOffering: Select Service Offerings -> Compute Offerings to see a list of available combinations of CPU cores, CPU, and memory to apply to your node instances. See the following figure for an example:
-
template: Select Images -> Templates to see available operating system image templates.
-
diskOffering: Select Storage -> Volumes, the select Create Volume, if you want to create disk storage to attach to your nodes (optional). You can use this to store logs or other data you want saved outside of the nodes. When you later create the cluster configuration, you can identify things like where you want the device mounted, the type of file system, labels and other information.
-
AffinityGroupIds: Select Compute -> Affinity Groups, then select Add new affinity group (optional). By creating an affinity group, you can tell all VMs from a set of instances to either all run on different physical hosts (anti-affinity) or just run anywhere they can (affinity).
Here is what some of that information would look like in a cluster configuration:
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: CloudStackMachineConfig
metadata:
name: my-cluster-name-cp
spec:
computeOffering:
name: "Medium Instance"
template:
name: "rhel8-kube-1.23-eksa"
diskOffering:
name: "Small"
mountPath: "/data-small"
device: "/dev/vdb"
filesystem: "ext4"
label: "data_disk"
symlinks:
/var/log/kubernetes: /data-small/var/log/kubernetes
affinityGroupIds:
- control-plane-anti-affinity
4 - Nutanix
See Create Nutanix production cluster to learn how to set up EKS Anywhere on Nutanix. Documents below describe how to prepare your Nutanix environment.
4.1 - Requirements for EKS Anywhere on Nutanix Cloud Infrastructure
To run EKS Anywhere, you will need:
Prepare Administrative machine
Set up an Administrative machine as described in Install EKS Anywhere .
Prepare a Nutanix environment
To prepare a Nutanix environment to run EKS Anywhere, you need the following:
-
A Nutanix environment running AOS 5.20.4+ with AHV and Prism Central 2022.1+
-
Capacity to deploy 6-10 VMs
-
DHCP service or Nutanix IPAM running in your environment in the primary VM network for your workload cluster
-
One network in AOS to use for the cluster. EKS Anywhere clusters need access to Prism Central through the network to enable self-managing and storage capabilities.
-
A VM image imported into the Prism Image Service for the workload VMs
-
User credentials to create VMs and attach networks, etc
-
One IP address routable from cluster but excluded from DHCP/IPAM offering. This IP address is to be used as the Control Plane Endpoint IP
Below are some suggestions to ensure that this IP address is never handed out by your DHCP server.
You may need to contact your network engineer.
- Pick an IP address reachable from cluster subnet which is excluded from DHCP range OR
- Alter DHCP ranges to leave out an IP address(s) at the top and/or the bottom of the range OR
- Create an IP reservation for this IP on your DHCP server. This is usually accomplished by adding a dummy mapping of this IP address to a non-existent mac address.
- Block an IP address from the Nutanix IPAM managed network using aCLI
Each VM will require:
- 2 vCPUs
- 4GB RAM
- 40GB Disk
The administrative machine and the target workload environment will need network access to:
- Prism Central endpoint (must be accessible to EKS Anywhere clusters)
- Prism Element Data Services IP and CVM endpoints (for CSI storage connections)
- public.ecr.aws (for pulling EKS Anywhere container images)
- anywhere-assets.eks.amazonaws.com (to download the EKS Anywhere binaries and manifests)
- distro.eks.amazonaws.com (to download EKS Distro binaries and manifests)
- d2glxqk2uabbnd.cloudfront.net (for EKS Anywhere and EKS Distro ECR container images)
- api.ecr.us-west-2.amazonaws.com (for EKS Anywhere package authentication matching your region)
- d5l0dvt14r5h8.cloudfront.net (for EKS Anywhere package ECR container images)
- api.github.com (only if GitOps is enabled)
Nutanix information needed before creating the cluster
You need to get the following information before creating the cluster:
-
Static IP Addresses: You will need one IP address for the management cluster control plane endpoint, and a separate one for the controlplane of each workload cluster you add.
Let’s say you are going to have the management cluster and two workload clusters. For those, you would need three IP addresses, one for each. All of those addresses will be configured the same way in the configuration file you will generate for each cluster.
A static IP address will be used for control plane API server HA in each of your EKS Anywhere clusters. Choose IP addresses in your network range that do not conflict with other VMs and make sure they are excluded from your DHCP offering.
An IP address will be the value of the property
controlPlaneConfiguration.endpoint.hostin the config file of the management cluster. A separate IP address must be assigned for each workload cluster.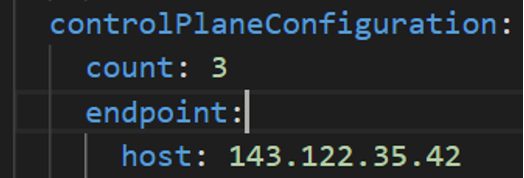
-
Prism Central FQDN or IP Address: The Prism Central fully qualified domain name or IP address.
-
Prism Element Cluster Name: The AOS cluster to deploy the EKS Anywhere cluster on.
-
VM Subnet Name: The VM network to deploy your EKS Anywhere cluster on.
-
Machine Template Image Name: The VM image to use for your EKS Anywhere cluster.
-
additionalTrustBundle (required if using a self-signed PC SSL certificate): The PEM encoded CA trust bundle of the root CA that issued the certificate for Prism Central.
4.2 - Preparing Nutanix Cloud Infrastructure for EKS Anywhere
Certain resources must be in place with appropriate user permissions to create an EKS Anywhere cluster using the Nutanix provider.
Configuring Nutanix User
You need a Prism Admin user to create EKS Anywhere clusters on top of your Nutanix cluster.
Build Nutanix AHV node images
Follow the steps outlined in artifacts to create a Ubuntu-based image for Nutanix AHV and import it into the AOS Image Service.
4.3 -
- Prism Central endpoint (must be accessible to EKS Anywhere clusters)
- Prism Element Data Services IP and CVM endpoints (for CSI storage connections)
- public.ecr.aws (for pulling EKS Anywhere container images)
- anywhere-assets.eks.amazonaws.com (to download the EKS Anywhere binaries and manifests)
- distro.eks.amazonaws.com (to download EKS Distro binaries and manifests)
- d2glxqk2uabbnd.cloudfront.net (for EKS Anywhere and EKS Distro ECR container images)
- api.ecr.us-west-2.amazonaws.com (for EKS Anywhere package authentication matching your region)
- d5l0dvt14r5h8.cloudfront.net (for EKS Anywhere package ECR container images)
- api.github.com (only if GitOps is enabled)
5 - VMware vSphere
5.1 - Requirements for EKS Anywhere on VMware vSphere
To run EKS Anywhere, you will need:
Prepare Administrative machine
Set up an Administrative machine as described in Install EKS Anywhere .
Prepare a VMware vSphere environment
To prepare a VMware vSphere environment to run EKS Anywhere, you need the following:
-
A vSphere 7+ environment running vCenter
-
Capacity to deploy 6-10 VMs
-
DHCP service running in vSphere environment in the primary VM network for your workload cluster
-
One network in vSphere to use for the cluster. EKS Anywhere clusters need access to vCenter through the network to enable self-managing and storage capabilities.
-
An OVA imported into vSphere and converted into a template for the workload VMs
-
User credentials to create VMs and attach networks, etc
-
One IP address routable from cluster but excluded from DHCP offering. This IP address is to be used as the Control Plane Endpoint IP
Below are some suggestions to ensure that this IP address is never handed out by your DHCP server.
You may need to contact your network engineer.
- Pick an IP address reachable from cluster subnet which is excluded from DHCP range OR
- Alter DHCP ranges to leave out an IP address(s) at the top and/or the bottom of the range OR
- Create an IP reservation for this IP on your DHCP server. This is usually accomplished by adding a dummy mapping of this IP address to a non-existent mac address.
Each VM will require:
- 2 vCPUs
- 8GB RAM
- 25GB Disk
The administrative machine and the target workload environment will need network access to:
- vCenter endpoint (must be accessible to EKS Anywhere clusters)
- public.ecr.aws
- anywhere-assets.eks.amazonaws.com (to download the EKS Anywhere binaries, manifests and OVAs)
- distro.eks.amazonaws.com (to download EKS Distro binaries and manifests)
- d2glxqk2uabbnd.cloudfront.net (for EKS Anywhere and EKS Distro ECR container images)
- api.ecr.us-west-2.amazonaws.com (for EKS Anywhere package authentication matching your region)
- d5l0dvt14r5h8.cloudfront.net (for EKS Anywhere package ECR container images)
- api.github.com (only if GitOps is enabled)
vSphere information needed before creating the cluster
You need to get the following information before creating the cluster:
-
Static IP Addresses: You will need one IP address for the management cluster control plane endpoint, and a separate one for the controlplane of each workload cluster you add.
Let’s say you are going to have the management cluster and two workload clusters. For those, you would need three IP addresses, one for each. All of those addresses will be configured the same way in the configuration file you will generate for each cluster.
A static IP address will be used for each control plane VM in your EKS Anywhere cluster. Choose IP addresses in your network range that do not conflict with other VMs and make sure they are excluded from your DHCP offering.
An IP address will be the value of the property
controlPlaneConfiguration.endpoint.hostin the config file of the management cluster. A separate IP address must be assigned for each workload cluster. -
vSphere Datacenter Name: The vSphere datacenter to deploy the EKS Anywhere cluster on.
-
VM Network Name: The VM network to deploy your EKS Anywhere cluster on.
-
vCenter Server Domain Name: The vCenter server fully qualified domain name or IP address. If the server IP is used, the thumbprint must be set or insecure must be set to true.

-
thumbprint (required if insecure=false): The SHA1 thumbprint of the vCenter server certificate which is only required if you have a self-signed certificate for your vSphere endpoint.
There are several ways to obtain your vCenter thumbprint. If you have govc installed , you can run the following command in the Administrative machine terminal, and take a note of the output:
govc about.cert -thumbprint -k -
template: The VM template to use for your EKS Anywhere cluster. This template was created when you imported the OVA file into vSphere.
-
datastore: The vSphere datastore to deploy your EKS Anywhere cluster on.
-
folder: The folder parameter in VSphereMachineConfig allows you to organize the VMs of an EKS Anywhere cluster. With this, each cluster can be organized as a folder in vSphere. You will have a separate folder for the management cluster and each cluster you are adding.
-
resourcePool: The vSphere Resource pools for your VMs in the EKS Anywhere cluster. If there is a resource pool:
/<datacenter>/host/<resource-pool-name>/Resources
5.2 - Preparing vSphere for EKS Anywhere
Certain resources must be in place with appropriate user permissions to create an EKS Anywhere cluster using the vSphere provider.
Configuring Folder Resources
Create a VM folder:
For each user that needs to create workload clusters, have the vSphere administrator create a VM folder. That folder will host:
- The VMs of the Control plane and Data plane nodes of each cluster.
- A nested folder for the management cluster and another one for each workload cluster.
- Each cluster VM in its own nested folder under this folder.
Follow these steps to create the user’s vSphere folder:
- From vCenter, select the Menus/VM and Template tab.
- Select either a datacenter or another folder as a parent object for the folder that you want to create.
- Right-click the parent object and click New Folder.
- Enter a name for the folder and click OK. For more details, see the vSphere Create a Folder documentation.
Configuring vSphere User, Group, and Roles
You need a vSphere user with the right privileges to let you create EKS Anywhere clusters on top of your vSphere cluster.
Configure via EKSA CLI
To configure a new user via CLI, you will need two things:
- a set of vSphere admin credentials with the ability to create users and groups. If you do not have the rights to create new groups and users, you can invoke govc commands directly as outlined here.
- a
user.yamlfile:
apiVersion: "eks-anywhere.amazon.com/v1"
kind: vSphereUser
spec:
username: "eksa" # optional, default eksa
group: "MyExistingGroup" # optional, default EKSAUsers
globalRole: "MyGlobalRole" # optional, default EKSAGlobalRole
userRole: "MyUserRole" # optional, default EKSAUserRole
adminRole: "MyEKSAAdminRole" # optional, default EKSACloudAdminRole
datacenter: "MyDatacenter"
vSphereDomain: "vsphere.local" # this should be the domain used when you login, e.g. YourUsername@vsphere.local
connection:
server: "https://my-vsphere.internal.acme.com"
insecure: false
objects:
networks:
- !!str "/MyDatacenter/network/My Network"
datastores:
- !!str "/MyDatacenter/datastore/MyDatastore2"
resourcePools:
- !!str "/MyDatacenter/host/Cluster-03/MyResourcePool" # NOTE: see below if you do not want to use a resource pool
folders:
- !!str "/MyDatacenter/vm/OrgDirectory/MyVMs"
templates:
- !!str "/MyDatacenter/vm/Templates/MyTemplates"
NOTE: if you do not want to create a resource pool, you can instead specify the cluster directly as /MyDatacenter/host/Cluster-03 in user.yaml, where Cluster-03 is your cluster name. In your cluster spec, you will need to specify /MyDatacenter/host/Cluster-03/Resources for the resourcePool field.
Set the admin credentials as environment variables:
export EKSA_VSPHERE_USERNAME=<ADMIN_VSPHERE_USERNAME>
export EKSA_VSPHERE_PASSWORD=<ADMIN_VSPHERE_PASSWORD>
If the user does not already exist, you can create the user and all the specified group and role objects by running:
eksctl anywhere exp vsphere setup user -f user.yaml --password '<NewUserPassword>'
If the user or any of the group or role objects already exist, use the force flag instead to overwrite Group-Role-Object mappings for the group, roles, and objects specified in the user.yaml config file:
eksctl anywhere exp vsphere setup user -f user.yaml --force
Please note that there is one more manual step to configure global permissions here .
Configure via govc
If you do not have the rights to create a new user, you can still configure the necessary roles and permissions using the govc cli .
#! /bin/bash
# govc calls to configure a user with minimal permissions
set -x
set -e
EKSA_USER='<Username>@<UserDomain>'
USER_ROLE='EKSAUserRole'
GLOBAL_ROLE='EKSAGlobalRole'
ADMIN_ROLE='EKSACloudAdminRole'
FOLDER_VM='/YourDatacenter/vm/YourVMFolder'
FOLDER_TEMPLATES='/YourDatacenter/vm/Templates'
NETWORK='/YourDatacenter/network/YourNetwork'
DATASTORE='/YourDatacenter/datastore/YourDatastore'
RESOURCE_POOL='/YourDatacenter/host/Cluster-01/Resources/YourResourcePool'
govc role.create "$GLOBAL_ROLE" $(curl https://raw.githubusercontent.com/aws/eks-anywhere/main/pkg/config/static/globalPrivs.json | jq .[] | tr '\n' ' ' | tr -d '"')
govc role.create "$USER_ROLE" $(curl https://raw.githubusercontent.com/aws/eks-anywhere/main/pkg/config/static/eksUserPrivs.json | jq .[] | tr '\n' ' ' | tr -d '"')
govc role.create "$ADMIN_ROLE" $(curl https://raw.githubusercontent.com/aws/eks-anywhere/main/pkg/config/static/adminPrivs.json | jq .[] | tr '\n' ' ' | tr -d '"')
govc permissions.set -group=false -principal "$EKSA_USER" -role "$GLOBAL_ROLE" /
govc permissions.set -group=false -principal "$EKSA_USER" -role "$ADMIN_ROLE" "$FOLDER_VM"
govc permissions.set -group=false -principal "$EKSA_USER" -role "$ADMIN_ROLE" "$FOLDER_TEMPLATES"
govc permissions.set -group=false -principal "$EKSA_USER" -role "$USER_ROLE" "$NETWORK"
govc permissions.set -group=false -principal "$EKSA_USER" -role "$USER_ROLE" "$DATASTORE"
govc permissions.set -group=false -principal "$EKSA_USER" -role "$USER_ROLE" "$RESOURCE_POOL"
NOTE: if you do not want to create a resource pool, you can instead specify the cluster directly as /MyDatacenter/host/Cluster-03 in user.yaml, where Cluster-03 is your cluster name. In your cluster spec, you will need to specify /MyDatacenter/host/Cluster-03/Resources for the resourcePool field.
Please note that there is one more manual step to configure global permissions here .
Configure via UI
Add a vCenter User
Ask your VSphere administrator to add a vCenter user that will be used for the provisioning of the EKS Anywhere cluster in VMware vSphere.
- Log in with the vSphere Client to the vCenter Server.
- Specify the user name and password for a member of the vCenter Single Sign-On Administrators group.
- Navigate to the vCenter Single Sign-On user configuration UI.
- From the Home menu, select Administration.
- Under Single Sign On, click Users and Groups.
- If vsphere.local is not the currently selected domain, select it from the drop-down menu. You cannot add users to other domains.
- On the Users tab, click Add.
- Enter a user name and password for the new user.
- The maximum number of characters allowed for the user name is 300.
- You cannot change the user name after you create a user. The password must meet the password policy requirements for the system.
- Click Add.
For more details, see vSphere Add vCenter Single Sign-On Users documentation.
Create and define user roles
When you add a user for creating clusters, that user initially has no privileges to perform management operations. So you have to add this user to groups with the required permissions, or assign a role or roles with the required permission to this user.
Three roles are needed to be able to create the EKS Anywhere cluster:
-
Create a global custom role: For example, you could name this EKS Anywhere Global. Define it for the user on the vCenter domain level and its children objects. Create this role with the following privileges:
> Content Library * Add library item * Check in a template * Check out a template * Create local library * Update files > vSphere Tagging * Assign or Unassign vSphere Tag * Assign or Unassign vSphere Tag on Object * Create vSphere Tag * Create vSphere Tag Category * Delete vSphere Tag * Delete vSphere Tag Category * Edit vSphere Tag * Edit vSphere Tag Category * Modify UsedBy Field For Category * Modify UsedBy Field For Tag > Sessions * Validate session -
Create a user custom role: The second role is also a custom role that you could call, for example, EKSAUserRole. Define this role with the following objects and children objects.
- The pool resource level and its children objects. This resource pool that our EKS Anywhere VMs will be part of.
- The storage object level and its children objects. This storage that will be used to store the cluster VMs.
- The network VLAN object level and its children objects. This network that will host the cluster VMs.
- The VM and Template folder level and its children objects.
Create this role with the following privileges:
> Content Library * Add library item * Check in a template * Check out a template * Create local library > Datastore * Allocate space * Browse datastore * Low level file operations > Folder * Create folder > vSphere Tagging * Assign or Unassign vSphere Tag * Assign or Unassign vSphere Tag on Object * Create vSphere Tag * Create vSphere Tag Category * Delete vSphere Tag * Delete vSphere Tag Category * Edit vSphere Tag * Edit vSphere Tag Category * Modify UsedBy Field For Category * Modify UsedBy Field For Tag > Network * Assign network > Resource * Assign virtual machine to resource pool > Scheduled task * Create tasks * Modify task * Remove task * Run task > Profile-driven storage * Profile-driven storage view > Storage views * View > vApp * Import > Virtual machine * Change Configuration - Add existing disk - Add new disk - Add or remove device - Advanced configuration - Change CPU count - Change Memory - Change Settings - Configure Raw device - Extend virtual disk - Modify device settings - Remove disk * Edit Inventory - Create from existing - Create new - Remove * Interaction - Power off - Power on * Provisioning - Clone template - Clone virtual machine - Create template from virtual machine - Customize guest - Deploy template - Mark as template - Read customization specifications * Snapshot management - Create snapshot - Remove snapshot - Revert to snapshot -
Create a default Administrator role: The third role is the default system role Administrator that you define to the user on the folder level and its children objects (VMs and OVA templates) that was created by the VSphere admistrator for you.
To create a role and define privileges check Create a vCenter Server Custom Role and Defined Privileges pages.
Manually set Global Permissions role in Global Permissions UI
vSphere does not currently support a public API for setting global permissions. Because of this, you will need to manually assign the Global Role you created to your user or group in the Global Permissions UI.
Deploy an OVA Template
If the user creating the cluster has permission and network access to create and tag a template, you can skip these steps because EKS Anywhere will automatically download the OVA and create the template if it can. If the user does not have the permissions or network access to create and tag the template, follow this guide. The OVA contains the operating system (Ubuntu, Bottlerocket, or RHEL) for a specific EKS Distro Kubernetes release and EKS Anywhere version. The following example uses Ubuntu as the operating system, but a similar workflow would work for Bottlerocket or RHEL.
Steps to deploy the OVA
- Go to the artifacts page and download or build the OVA template with the newest EKS Distro Kubernetes release to your computer.
- Log in to the vCenter Server.
- Right-click the folder you created above and select Deploy OVF Template. The Deploy OVF Template wizard opens.
- On the Select an OVF template page, select the Local file option, specify the location of the OVA template you downloaded to your computer, and click Next.
- On the Select a name and folder page, enter a unique name for the virtual machine or leave the default generated name, if you do not have other templates with the same name within your vCenter Server virtual machine folder. The default deployment location for the virtual machine is the inventory object where you started the wizard, which is the folder you created above. Click Next.
- On the Select a compute resource page, select the resource pool where to run the deployed VM template, and click Next.
- On the Review details page, verify the OVF or OVA template details and click Next.
- On the Select storage page, select a datastore to store the deployed OVF or OVA template and click Next.
- On the Select networks page, select a source network and map it to a destination network. Click Next.
- On the Ready to complete page, review the page and click Finish. For details, see Deploy an OVF or OVA Template
To build your own Ubuntu OVA template check the Building your own Ubuntu OVA section in the following link .
To use the deployed OVA template to create the VMs for the EKS Anywhere cluster, you have to tag it with specific values for the os and eksdRelease keys.
The value of the os key is the operating system of the deployed OVA template, which is ubuntu in our scenario.
The value of the eksdRelease holds kubernetes and the EKS-D release used in the deployed OVA template.
Check the following Customize OVAs
page for more details.
Steps to tag the deployed OVA template:
- Go to the artifacts page and take notes of the tags and values associated with the OVA template you deployed in the previous step.
- In the vSphere Client, select Menu > Tags & Custom Attributes.
- Select the Tags tab and click Tags.
- Click New.
- In the Create Tag dialog box, copy the
ostag name associated with your OVA that you took notes of, which in our case isos:ubuntuand paste it as the name for the first tag required. - Specify the tag category
osif it exist or create it if it does not exist. - Click Create.
- Repeat steps 2-4.
- In the Create Tag dialog box, copy the
ostag name associated with your OVA that you took notes of, which in our case iseksdRelease:kubernetes-1-21-eks-8and paste it as the name for the second tag required. - Specify the tag category
eksdReleaseif it exist or create it if it does not exist. - Click Create.
- Navigate to the VM and Template tab.
- Select the folder that was created.
- Select deployed template and click Actions.
- From the drop-down menu, select Tags and Custom Attributes > Assign Tag.
- Select the tags we created from the list and confirm the operation.
5.3 - Customize OVAs: Ubuntu
There may be a need to make specific configuration changes on the imported ova template before using it to create/update EKS-A clusters.
Set up SSH Access for Imported OVA
SSH user and key need to be configured in order to allow SSH login to the VM template
Clone template to VM
Create an environment variable to hold the name of modified VM/template
export VM=<vm-name>
Clone the imported OVA template to create VM
govc vm.clone -on=false -vm=<full-path-to-imported-template> - folder=<full-path-to-folder-that-will-contain-the-VM> -ds=<datastore> $VM
Configure VM with cloud-init and the VMX GuestInfo datasource
Create a metadata.yaml file
instance-id: cloud-vm
local-hostname: cloud-vm
network:
version: 2
ethernets:
nics:
match:
name: ens*
dhcp4: yes
Create a userdata.yaml file
#cloud-config
users:
- default
- name: <username>
primary_group: <username>
sudo: ALL=(ALL) NOPASSWD:ALL
groups: sudo, wheel
ssh_import_id: None
lock_passwd: true
ssh_authorized_keys:
- <user's ssh public key>
Export environment variable containing the cloud-init metadata and userdata
export METADATA=$(gzip -c9 <metadata.yaml | { base64 -w0 2>/dev/null || base64; }) \
USERDATA=$(gzip -c9 <userdata.yaml | { base64 -w0 2>/dev/null || base64; })
Assign metadata and userdata to VM’s guestinfo
govc vm.change -vm "${VM}" \
-e guestinfo.metadata="${METADATA}" \
-e guestinfo.metadata.encoding="gzip+base64" \
-e guestinfo.userdata="${USERDATA}" \
-e guestinfo.userdata.encoding="gzip+base64"
Power the VM on
govc vm.power -on “$VM”
Customize the VM
Once the VM is powered on and fetches an IP address, ssh into the VM using your private key corresponding to the public key specified in userdata.yaml
ssh -i <private-key-file> username@<VM-IP>
At this point, you can make the desired configuration changes on the VM. The following sections describe some of the things you may want to do:
Add a Certificate Authority
Copy your CA certificate under /usr/local/share/ca-certificates and run sudo update-ca-certificates which will place the certificate under the /etc/ssl/certs directory.
Add Authentication Credentials for a Private Registry
If /etc/containerd/config.toml is not present initially, the default configuration can be generated by running the containerd config default > /etc/containerd/config.toml command. To configure a credential for a specific registry, create/modify the /etc/containerd/config.toml as follows:
# explicitly use v2 config format
version = 2
# The registry host has to be a domain name or IP. Port number is also
# needed if the default HTTPS or HTTP port is not used.
[plugins."io.containerd.grpc.v1.cri".registry.configs."registry1-host:port".auth]
username = ""
password = ""
auth = ""
identitytoken = ""
# The registry host has to be a domain name or IP. Port number is also
# needed if the default HTTPS or HTTP port is not used.
[plugins."io.containerd.grpc.v1.cri".registry.configs."registry2-host:port".auth]
username = ""
password = ""
auth = ""
identitytoken = ""
Restart containerd service with the sudo systemctl restart containerd command.
Convert VM to a Template
After you have customized the VM, you need to convert it to a template.
Cleanup the machine and power off the VM
This step is needed because of a known issue in Ubuntu which results in the clone VMs getting the same DHCP IP
sudo su
echo -n > /etc/machine-id
rm /var/lib/dbus/machine-id
ln -s /etc/machine-id /var/lib/dbus/machine-id
cloud-init clean -l --machine-id
Delete the hostname from file
/etc/hostname
Delete the networking config file
rm -rf /etc/netplan/50-cloud-init.yaml
Edit the cloud init config to turn preserve_hostname to false
vi /etc/cloud/cloud.cfg
Power the VM down
govc vm.power -off "$VM"
Take a snapshot of the VM
It is recommended to take a snapshot of the VM as it reduces the provisioning time for the machines and makes cluster creation faster.
If you do snapshot the VM, you will not be able to customize the disk size of your cluster VMs. If you prefer not to take a snapshot, skip this step.
govc snapshot.create -vm "$VM" root
Convert VM to template
govc vm.markastemplate $VM
Tag the template appropriately as described here
Use this customized template to create/upgrade EKS Anywhere clusters
5.4 - Import OVAs
If you want to specify an OVA template, you will need to import OVA files into vSphere before you can use it in your EKS Anywhere cluster. This guide was written using VMware Cloud on AWS, but the VMware OVA import guide can be found here .
Note
If you don’t specify a template in the cluster spec file, EKS Anywhere will use the proper default one for the Kubernetes minor version and OS family you specified in the spec file. If the template doesn’t exist, it will import the appropriate OVA into vSphere and add the necessary tags.
The default OVA for a Kubernetes minor version + OS family will change over time, for example, when a new EKS Distro version is released. In that case, new clusters will use the new OVA (EKS Anywhere will import it automatically).
Warning
Do not power on the imported OVA directly as it can cause some undesired configurations on the OS template and affect cluster creation. If you want to explore or modify the OS, please follow the instructions to customize the OVA.EKS Anywhere supports the following operating system families
- Bottlerocket (default)
- Ubuntu
- RHEL
A list of OVAs for this release can be found on the artifacts page .
Using vCenter Web User Interface
-
Right click on your Datacenter, select Deploy OVF Template
-
Select an OVF template using URL or selecting a local OVF file and click on Next. If you are not able to select an OVF template using URL, download the file and use Local file option.
Note: If you are using Bottlerocket OVAs, please select local file option.
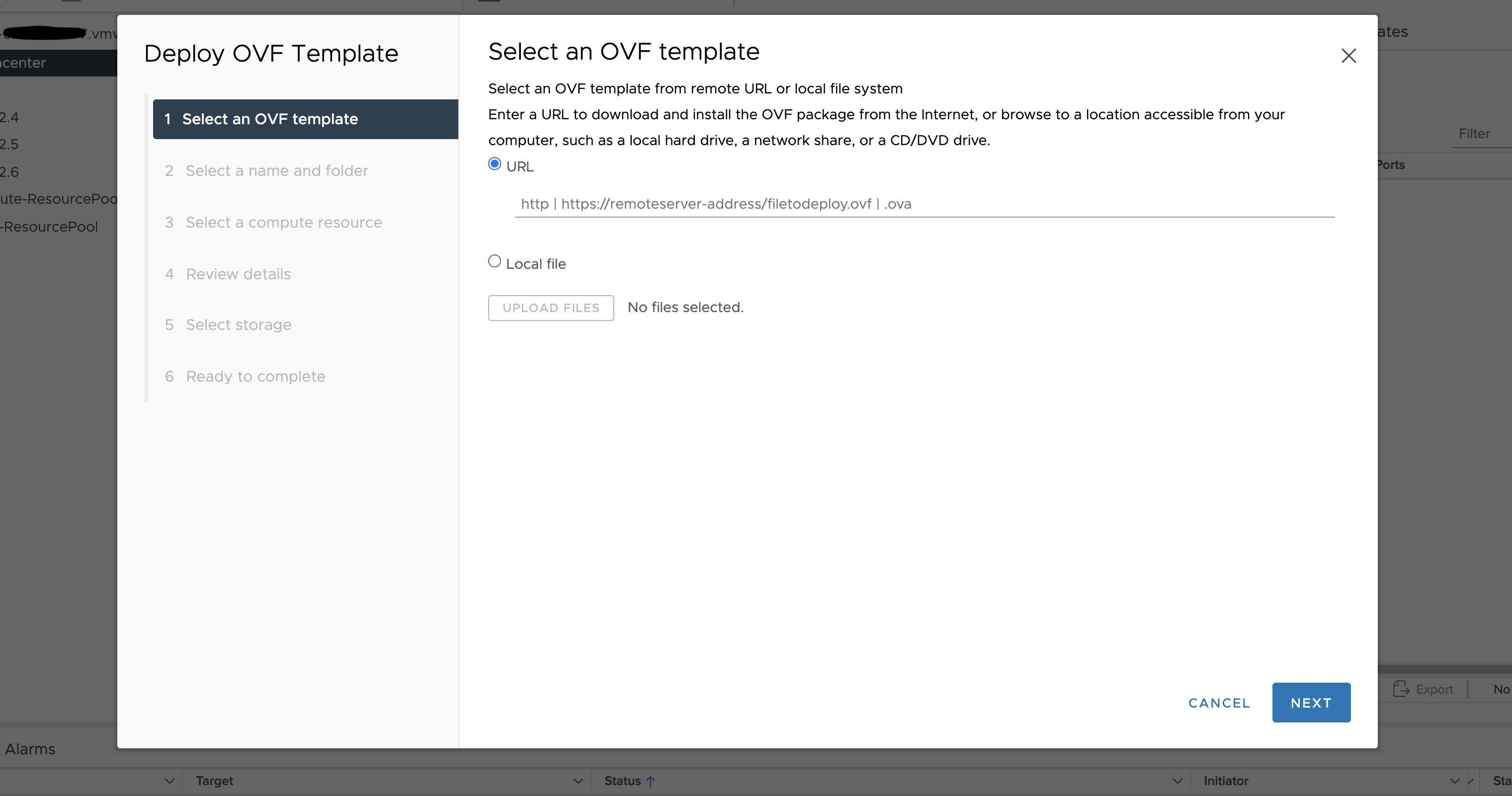
-
Select a folder where you want to deploy your OVF package (most of our OVF templates are under SDDC-Datacenter directory) and click on Next. You cannot have an OVF template with the same name in one directory. For workload VM templates, leave the Kubernetes version in the template name for reference. A workload VM template will support at least one prior Kubernetes major versions.
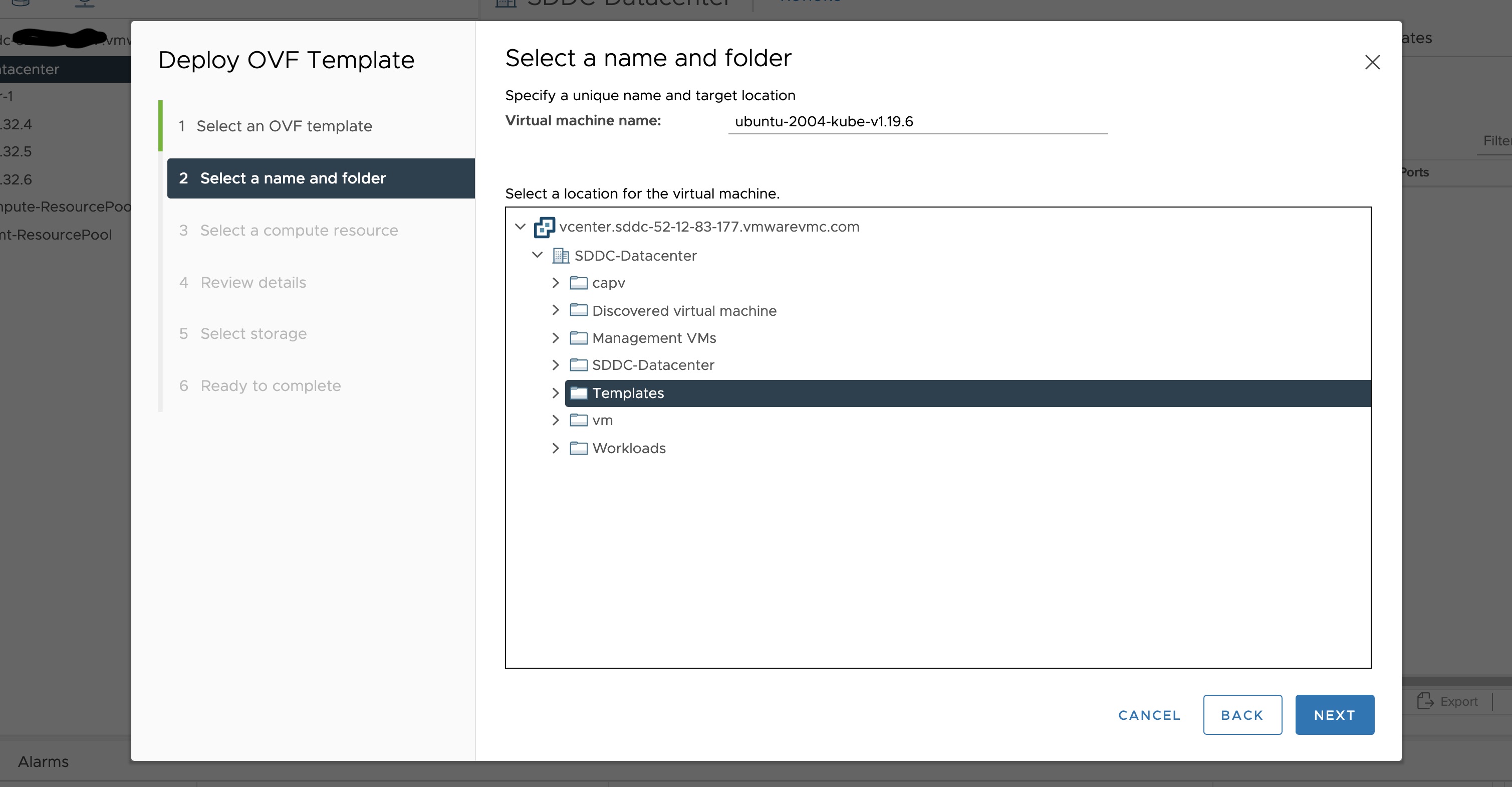
-
Select any compute resource to run (from cluster-1, 10.2.34.5, etc..) the deployed VM and click on Next
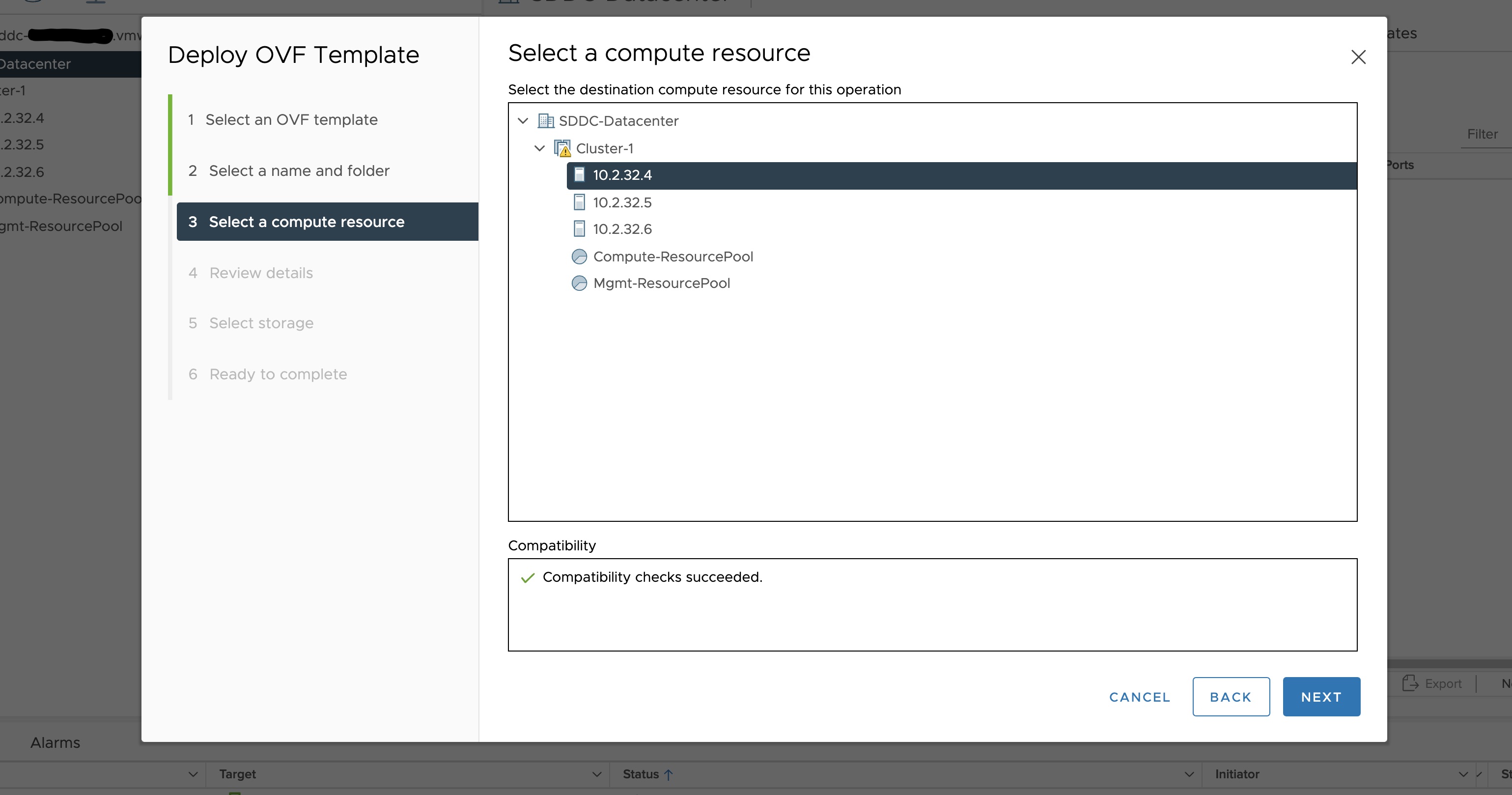
-
Review the details and click Next.
-
Accept the agreement and click Next.
-
Select the appropriate storage (e.g. “WorkloadDatastore“) and click Next.
-
Select destination network (e.g. “sddc-cgw-network-1”) and click Next.
-
Finish.
-
Snapshot the VM. Right click on the imported VM and select Snapshots -> Take Snapshot… (It is highly recommended that you snapshot the VM. This will reduce the time it takes to provision machines and cluster creation will be faster. If you prefer not to take snapshot, skip to step 13)
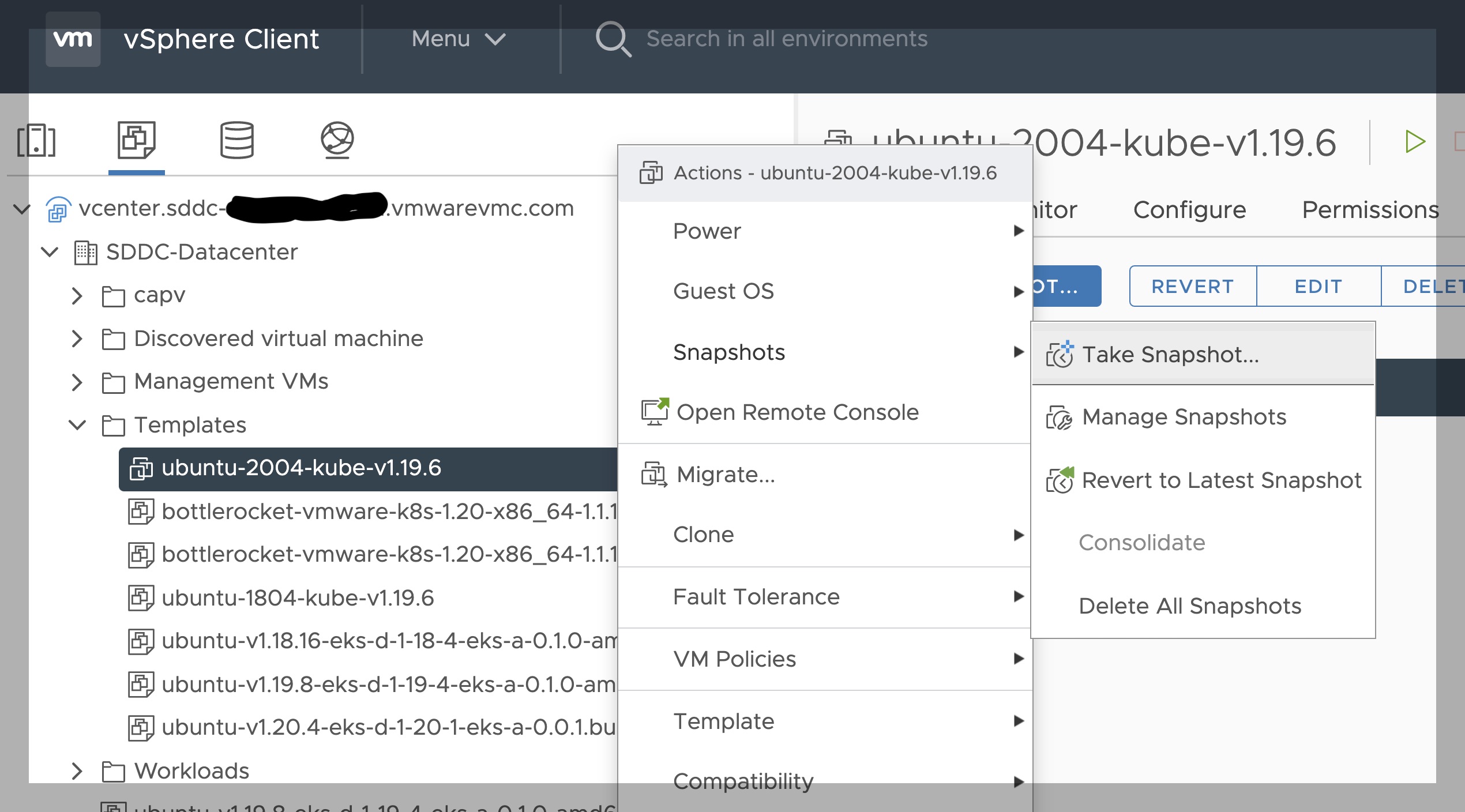
-
Name your template (e.g. “root”) and click Create.
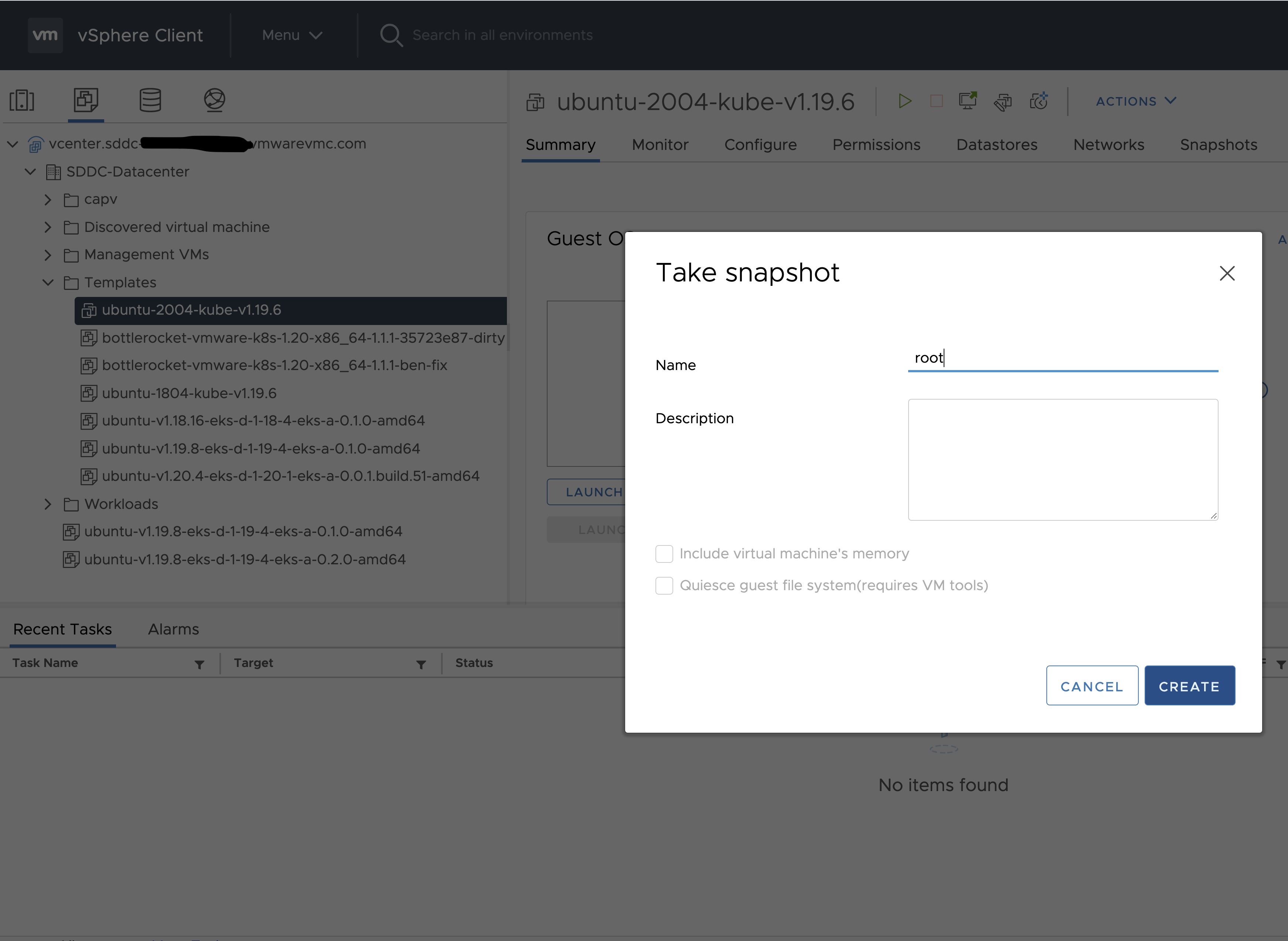
-
Snapshots for the imported VM should now show up under the Snapshots tab for the VM.
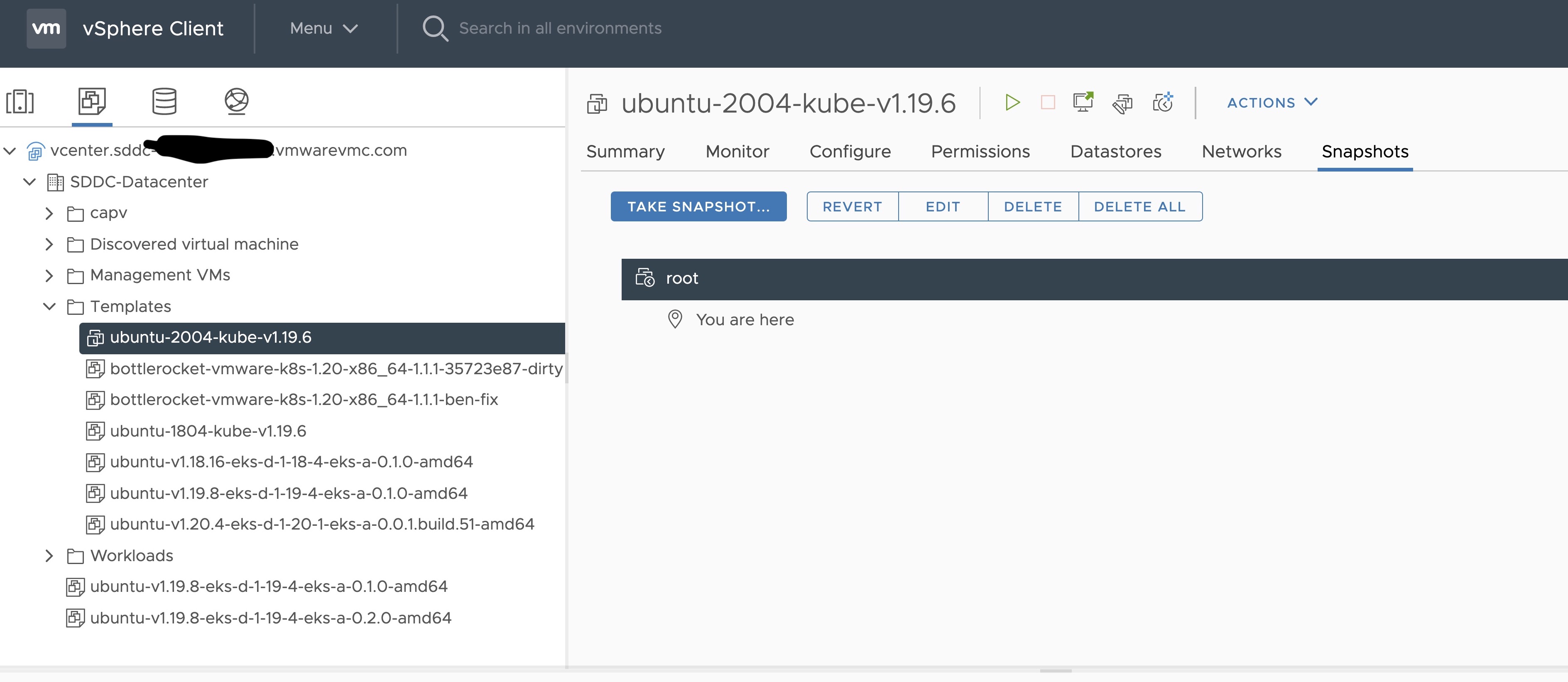
-
Right click on the imported VM and select Template and Convert to Template
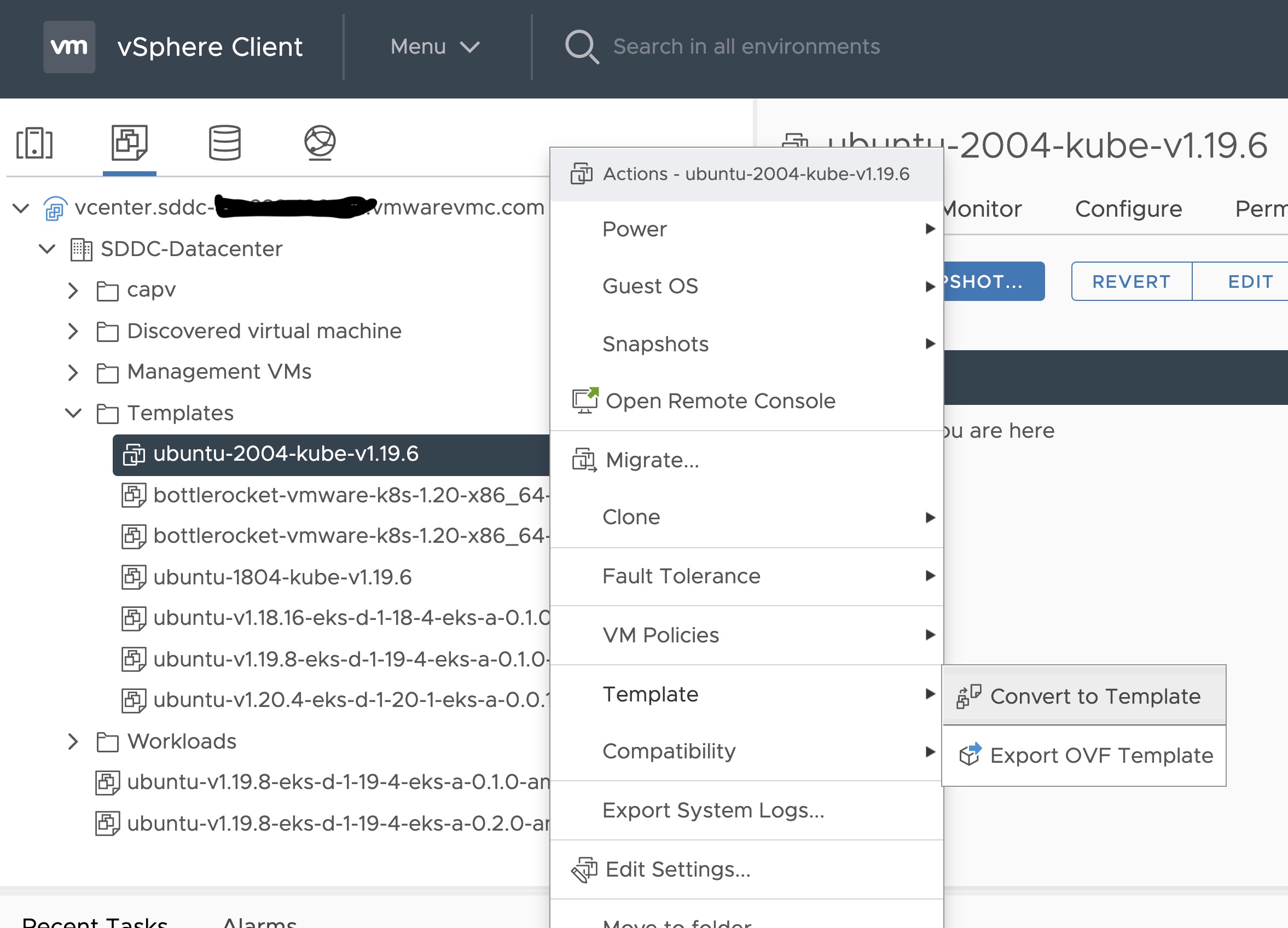
Steps to deploy a template using GOVC (CLI)
To deploy a template using govc, you must first ensure that you have
GOVC installed
. You need to set and export three
environment variables to run govc GOVC_USERNAME, GOVC_PASSWORD and GOVC_URL.
-
Import the template to a content library in vCenter using URL or selecting a local OVA file
Using URL:
govc library.import -k -pull <library name> <URL for the OVA file>Using a file from the local machine:
govc library.import <library name> <path to OVA file on local machine> -
Deploy the template
govc library.deploy -pool <resource pool> -folder <folder location to deploy template> /<library name>/<template name> <name of new VM>2a. If using Bottlerocket template for newer Kubernetes version than 1.21, resize disk 1 to 22G
govc vm.disk.change -vm <template name> -disk.label "Hard disk 1" -size 22G2b. If using Bottlerocket template for Kubernetes version 1.21, resize disk 2 to 20G
govc vm.disk.change -vm <template name> -disk.label "Hard disk 2" -size 20G -
Take a snapshot of the VM (It is highly recommended that you snapshot the VM. This will reduce the time it takes to provision machines and cluster creation will be faster. If you prefer not to take snapshot, skip this step)
govc snapshot.create -vm ubuntu-2004-kube-v1.25.6 root -
Mark the new VM as a template
govc vm.markastemplate <name of new VM>
Important Additional Steps to Tag the OVA
Using vCenter UI
Tag to indicate OS family
- Select the template that was newly created in the steps above and navigate to Summary -> Tags.
- Click Assign -> Add Tag to create a new tag and attach it
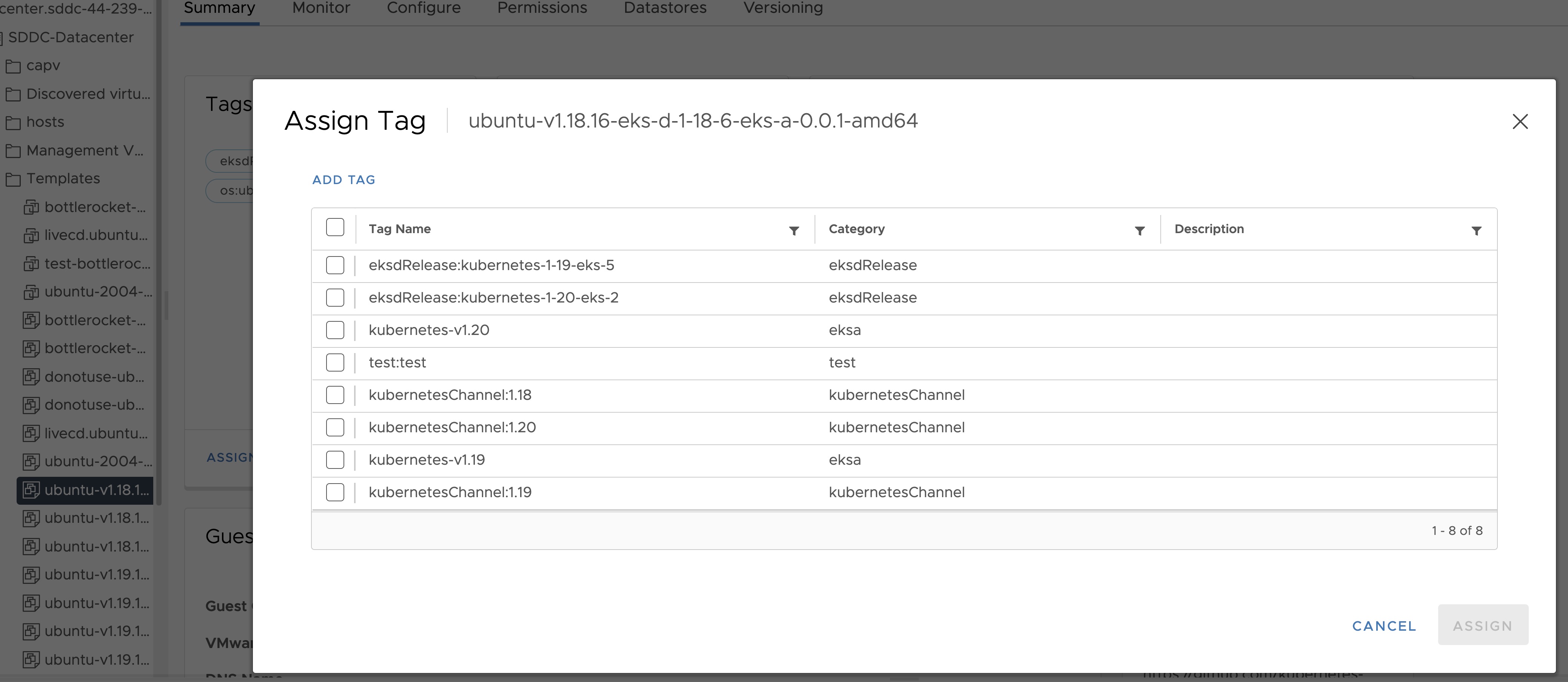
- Name the tag os:ubuntu or os:bottlerocket
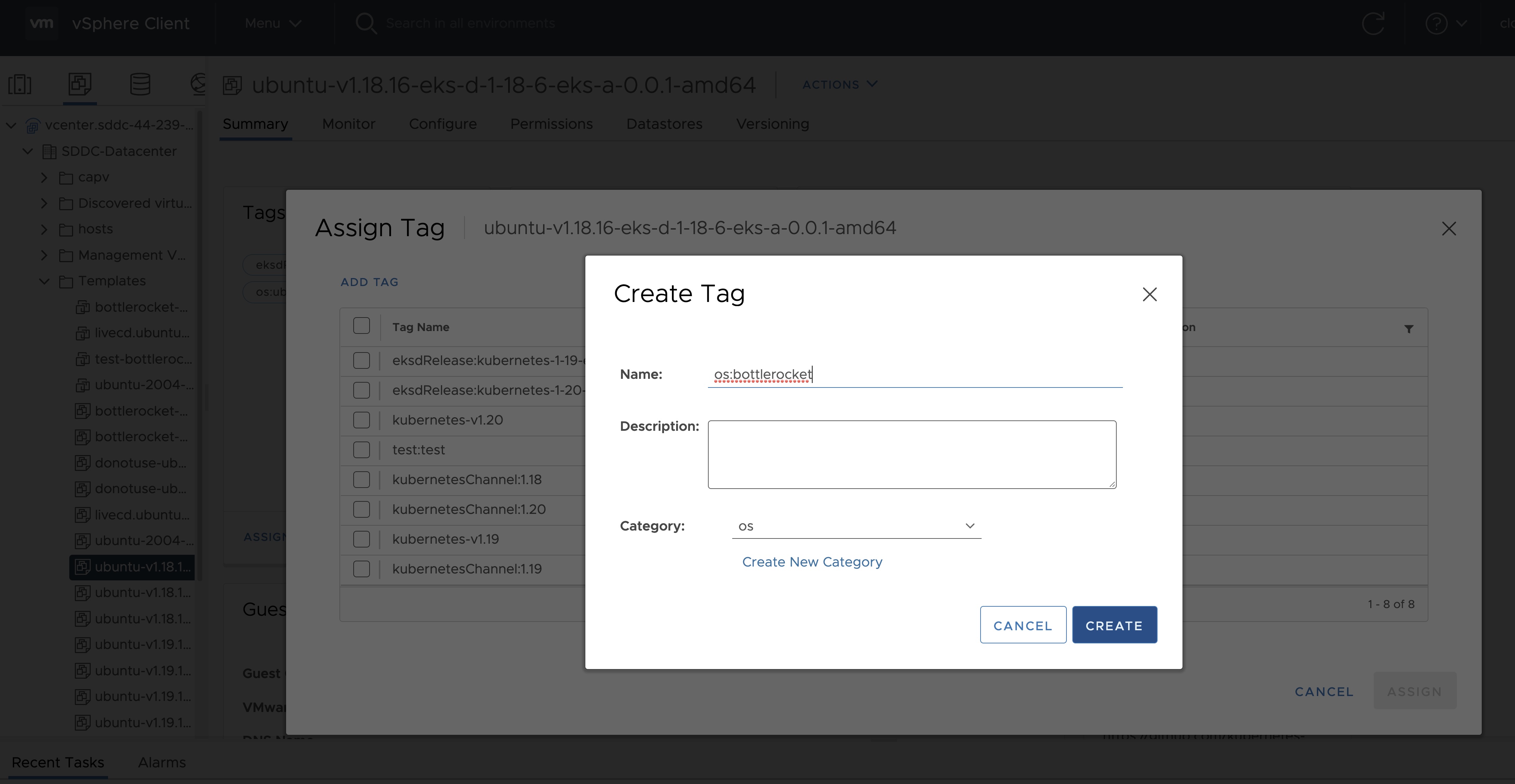
Tag to indicate eksd release
- Select the template that was newly created in the steps above and navigate to Summary -> Tags.
- Click Assign -> Add Tag to create a new tag and attach it
- Name the tag eksdRelease:{eksd release for the selected ova}, for example eksdRelease:kubernetes-1-25-eks-5 for the 1.25 ova. You can find the rest of eksd releases in the previous section
. If it’s the first time you add an
eksdReleasetag, you would need to create the category first. Click on “Create New Category” and name iteksdRelease.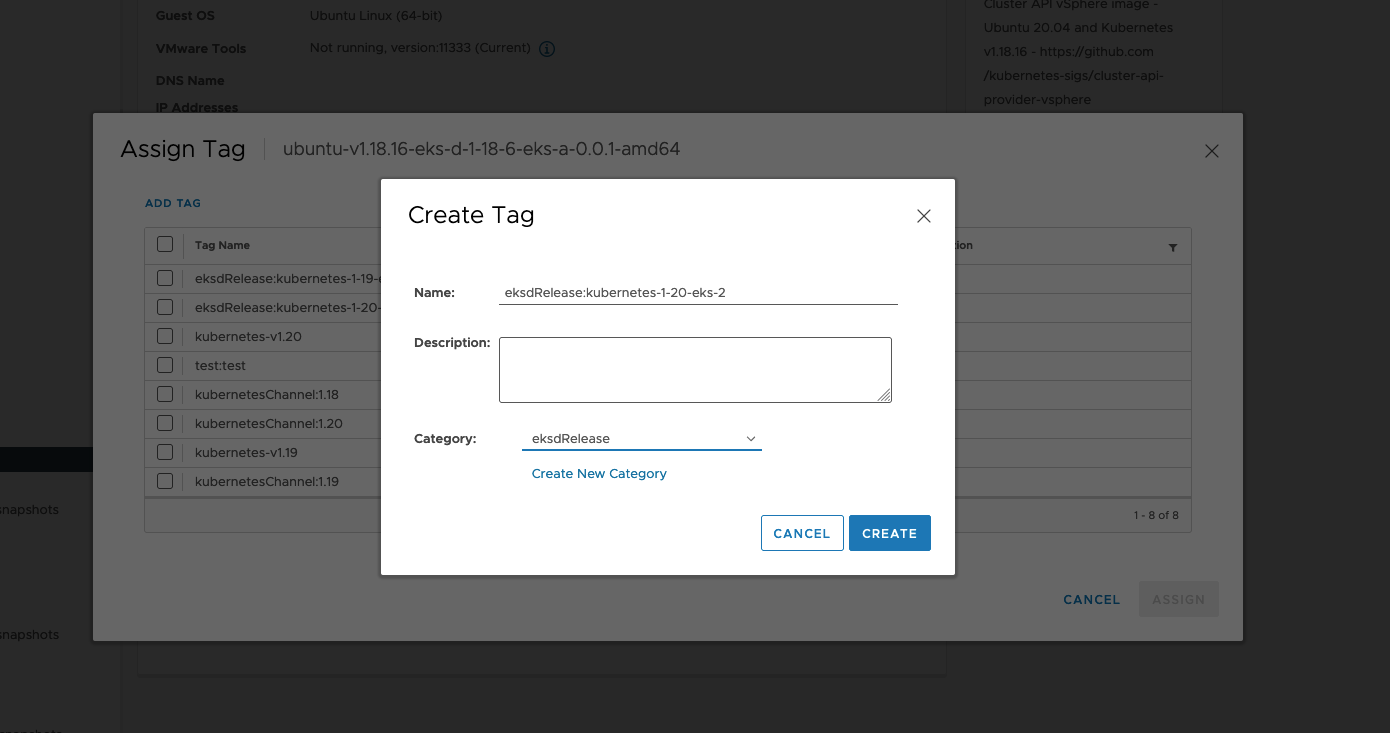
Using govc
Tag to indicate OS family
- Create tag category
govc tags.category.create -t VirtualMachine os
- Create tags os:ubuntu and os:bottlerocket
govc tags.create -c os os:bottlerocket
govc tags.create -c os os:ubuntu
- Attach newly created tag to the template
govc tags.attach os:bottlerocket <Template Path>
govc tags.attach os:ubuntu <Template Path>
- Verify tag is attached to the template
govc tags.ls <Template Path>
Tag to indicate eksd release
- Create tag category
govc tags.category.create -t VirtualMachine eksdRelease
- Create the proper eksd release Tag, depending on your template. You can find the eksd releases in the previous section . For example eksdRelease:kubernetes-1-25-eks-5 for the 1.25 template.
govc tags.create -c eksdRelease eksdRelease:kubernetes-1-25-eks-5
- Attach newly created tag to the template
govc tags.attach eksdRelease:kubernetes-1-25-eks-5 <Template Path>
- Verify tag is attached to the template
govc tags.ls <Template Path>
Note
If the tags above are not applied as shown exactly, eks-a template validations will fail and CLI will abortAfter you are done you can use the template for your workload cluster.
5.5 - Custom DHCP Configuration
If your vSphere deployment is not configured with DHCP, you may want to run your own DHCP server. It may be necessary to turn off DHCP snooping on your switch to get DHCP working across VM servers. If you are running your administration machine in vSphere, it would most likely be easiest to run the DHCP server on that machine. This example is for Ubuntu.
Install
Install DHCP server
sudo apt-get install isc-dhcp-server
Configure /etc/dhcp/dhcpd.conf
Update the ip address range, subnet, mask, etc to suite your configuration similar to this:
default-lease-time 600;
max-lease-time 7200;
ddns-update-style none;
authoritative;
subnet 10.8.105.0 netmask 255.255.255.0 {
range 10.8.105.9 10.8.105.41;
option subnet-mask 255.255.255.0;
option routers 10.8.105.1;
option domain-name-servers 147.149.1.69;
}
Configure /etc/default/isc-dhcp-server
Add the main NIC device interface to this file, such as eth0 (this example uses ens160).
INTERFACESv4="ens160"
Restart DHCP
service isc-dhcp-server restart
Verify your configuration
This example assumes the ens160 interface:
tcpdump -ni ens160 port 67 -vvvv
tcpdump: listening on ens160, link-type EN10MB (Ethernet), capture size 262144 bytes
09:13:54.297704 IP (tos 0xc0, ttl 64, id 40258, offset 0, flags [DF], proto UDP (17), length 327)
10.8.105.12.68 > 10.8.105.5.67: [udp sum ok] BOOTP/DHCP, Request from 00:50:56:90:56:cf, length 299, xid 0xf7a5aac5, secs 50310, Flags [none] (0x0000)
Client-IP 10.8.105.12
Client-Ethernet-Address 00:50:56:90:56:cf
Vendor-rfc1048 Extensions
Magic Cookie 0x63825363
DHCP-Message Option 53, length 1: Request
Client-ID Option 61, length 19: hardware-type 255, 2d:1a:a1:33:00:02:00:00:ab:11:f2:c8:ef:ba:aa:5a:2f:33
Parameter-Request Option 55, length 11:
Subnet-Mask, Default-Gateway, Hostname, Domain-Name
Domain-Name-Server, MTU, Static-Route, Classless-Static-Route
Option 119, NTP, Option 120
MSZ Option 57, length 2: 576
Hostname Option 12, length 15: "prod-etcd-m8ctd"
END Option 255, length 0
09:13:54.299762 IP (tos 0x0, ttl 64, id 56218, offset 0, flags [DF], proto UDP (17), length 328)
10.8.105.5.67 > 10.8.105.12.68: [bad udp cksum 0xe766 -> 0x502f!] BOOTP/DHCP, Reply, length 300, xid 0xf7a5aac5, secs 50310, Flags [none] (0x0000)
Client-IP 10.8.105.12
Your-IP 10.8.105.12
Server-IP 10.8.105.5
Client-Ethernet-Address 00:50:56:90:56:cf
Vendor-rfc1048 Extensions
Magic Cookie 0x63825363
DHCP-Message Option 53, length 1: ACK
Server-ID Option 54, length 4: 10.8.105.5
Lease-Time Option 51, length 4: 600
Subnet-Mask Option 1, length 4: 255.255.255.0
Default-Gateway Option 3, length 4: 10.8.105.1
Domain-Name-Server Option 6, length 4: 147.149.1.69
END Option 255, length 0
PAD Option 0, length 0, occurs 26
5.6 -
- vCenter endpoint (must be accessible to EKS Anywhere clusters)
- public.ecr.aws
- anywhere-assets.eks.amazonaws.com (to download the EKS Anywhere binaries, manifests and OVAs)
- distro.eks.amazonaws.com (to download EKS Distro binaries and manifests)
- d2glxqk2uabbnd.cloudfront.net (for EKS Anywhere and EKS Distro ECR container images)
- api.ecr.us-west-2.amazonaws.com (for EKS Anywhere package authentication matching your region)
- d5l0dvt14r5h8.cloudfront.net (for EKS Anywhere package ECR container images)
- api.github.com (only if GitOps is enabled)
6 - Security best practices
If you discover a potential security issue in this project, we ask that you notify AWS/Amazon Security via our vulnerability reporting page . Please do not create a public GitHub issue for security problems.
This guide provides advice about best practices for EKS Anywhere specific security concerns. For a more complete treatment of Kubernetes security generally please refer to the official Kubernetes documentation on Securing a Cluster and the Amazon EKS Best Practices Guide for Security .
The Shared Responsibility Model and EKS-A
AWS Cloud Services follow the Shared Responsibility Model, where AWS is responsible for security “of” the cloud, while the customer is responsible for security “in” the cloud. However, EKS Anywhere is an open-source tool and the distribution of responsibility differs from that of a managed cloud service like EKS.
AWS Responsibilities
AWS is responsible for building and delivering a secure tool. This tool will provision an initially secure Kubernetes cluster.
AWS is responsible for vetting and securely sourcing the services and tools packaged with EKS Anywhere and the cluster it creates (such as CoreDNS, Cilium, Flux, CAPI, and govc).
The EKS Anywhere build and delivery infrastructure, or supply chain, is secured to the standard of any AWS service and AWS takes responsibility for the secure and reliable delivery of a quality product which provisions a secure and stable Kubernetes cluster.
When the eksctl anywhere plugin is executed, EKS Anywhere components are automatically downloaded from AWS.
eksctl will then perform checksum verification on the components to ensure their authenticity.
AWS is responsible for the secure development and testing of the EKS Anywhere controller and associated custom resource definitions.
AWS is responsible for the secure development and testing of the EKS Anywhere CLI, and ensuring it handles sensitive data and cluster resources securely.
End user responsibilities
The end user is responsible for the entire EKS Anywhere cluster after it has been provisioned. AWS provides a mechanism to upgrade the cluster in-place, but it is the responsibility of the end user to perform that upgrade using the provided tools. End users are responsible for operating their clusters in accordance with Kubernetes security best practices, and for the ongoing security of the cluster after it has been provisioned. This includes but is not limited to:
- creation or modification of RBAC roles and bindings
- creation or modification of namespaces
- modification of the default container network interface plugin
- configuration of network ingress and load balancing
- use and configuration of container storage interfaces
- the inclusion of add-ons and other services
End users are also responsible for:
-
The hardware and software which make up the infrastructure layer (such as vSphere, ESXi, physical servers, and physical network infrastructure).
-
The ongoing maintenance of the cluster nodes, including the underlying guest operating systems. Additionally, while EKS Anywhere provides a streamlined process for upgrading a cluster to a new Kubernetes version, it is the responsibility of the user to perform the upgrade as necessary.
-
Any applications which run “on” the cluster, including their secure operation, least privilege, and use of well-known and vetted container images.
EKS Anywhere Security Best Practices
This section captures EKS Anywhere specific security best practices. Please read this section carefully and follow any guidance to ensure the ongoing security and reliability of your EKS Anywhere cluster.
Critical Namespaces
EKS Anywhere creates and uses resources in several critical namespaces. All of the EKS Anywhere managed namespaces should be treated as sensitive and access should be limited to only the most trusted users and processes. Allowing additional access or modifying the existing RBAC resources could potentially allow a subject to access the namespace and the resources that it contains. This could lead to the exposure of secrets or the failure of your cluster due to modification of critical resources. Here are rules you should follow when dealing with critical namespaces:
-
Avoid creating Roles in these namespaces or providing users access to them with ClusterRoles . For more information about creating limited roles for day-to-day administration and development, please see the official introduction to Role Based Access Control (RBAC) .
-
Do not modify existing Roles in these namespaces, bind existing roles to additional subjects , or create new Roles in the namespace.
-
Do not modify existing ClusterRoles or bind them to additional subjects.
-
Avoid using the cluster-admin role, as it grants permissions over all namespaces.
-
No subjects except for the most trusted administrators should be permitted to perform ANY action in the critical namespaces.
The critical namespaces include:
eksa-systemcapv-systemflux-systemcapi-systemcapi-webhook-systemcapi-kubeadm-control-plane-systemcapi-kubeadm-bootstrap-systemcert-managerkube-system(as with any Kubernetes cluster, this namespace is critical to the functioning of your cluster and should be treated with the highest level of sensitivity.)
Secrets
EKS Anywhere stores sensitive information, like the vSphere credentials and GitHub Personal Access Token, in the cluster as native Kubernetes secrets
.
These secret objects are namespaced, for example in the eksa-system and flux-system namespace, and limiting access to the sensitive namespaces will ensure that these secrets will not be exposed.
Additionally, limit access to the underlying node. Access to the node could allow access to the secret content.
EKS Anywhere does not currently support encryption-at-rest for Kubernetes secrets. EKS Anywhere support for Key Management Services (KMS) is planned.
The EKS Anywhere kubeconfig file
eksctl anywhere create cluster creates an EKS Anywhere-based Kubernetes cluster and outputs a kubeconfig
file with administrative privileges to the $PWD/$CLUSTER_NAME directory.
By default, this kubeconfig file uses certificate-based authentication and contains the user certificate data for the administrative user.
The kubeconfig file grants administrative privileges over your cluster to the bearer and the certificate key should be treated as you would any other private key or administrative password.
The EKS Anywhere-generated kubeconfig file should only be used for interacting with the cluster via eksctl anywhere commands, such as upgrade, and for the most privileged administrative tasks.
For more information about creating limited roles for day-to-day administration and development, please see the official introduction to Role Based Access Control (RBAC)
.
GitOps
GitOps enabled EKS Anywhere clusters maintain a copy of their cluster configuration in the user provided Git repository. This configuration acts as the source of truth for the cluster. Changes made to this configuration will be reflected in the cluster configuration.
AWS recommends that you gate any changes to this repository with mandatory pull request reviews. Carefully review pull requests for changes which could impact the availability of the cluster (such as scaling nodes to 0 and deleting the cluster object) or contain secrets.
GitHub Personal Access Token
Treat the GitHub PAT used with EKS Anywhere as you would any highly privileged secret, as it could potentially be used to make changes to your cluster by modifying the contents of the cluster configuration file through the GitHub.com API.
- Never commit the PAT to a Git repository
- Never share the PAT via untrusted channels
- Never grant non-administrative subjects access to the
flux-systemnamespace where the PAT is stored as a native Kubernetes secret.
Executing EKS Anywhere
Ensure that you execute eksctl anywhere create cluster on a trusted workstation in order to protect the values of sensitive environment variables and the EKS Anywhere generated kubeconfig file.
SSH Access to Cluster Nodes and ETCD Nodes
EKS Anywhere provides the option to configure an ssh authorized key for access to underlying nodes in a cluster, via vsphereMachineConfig.Users.sshAuthorizedKeys.
This grants the associated private key the ability to connect to the cluster via ssh as the user capv with sudo permissions.
The associated private key should be treated as extremely sensitive, as sudo access to the cluster and ETCD nodes can permit access to secret object data and potentially confer arbitrary control over the cluster.
VMWare OVAs
Only download OVAs for cluster nodes from official sources, and do not allow untrusted users or processes to modify the templates used by EKS Anywhere for provisioning nodes.
Keeping Bottlerocket up to date
EKS Anywhere provides the most updated patch of operating systems with every release. It is recommended that your clusters are kept up to date with the latest EKS Anywhere release to ensure you get the latest security updates. Bottlerocket is an EKS Anywhere supported operating system that can be kept up to date without requiring a cluster update. The Bottlerocket Update Operator is a Kubernetes update operator that coordinates Bottlerocket updates on hosts in the cluster. Please follow the instructions here to install Bottlerocket update operator.
Baremetal Clusters
EKS Anywhere Baremetal clusters run directly on physical servers in a datacenter. Make sure that the physical infrastructure, including the network, is secure before running EKS Anywhere clusters.
Please follow industry best practices for securing your network and datacenter, including but not limited to the following
- Only allow trusted devices on the network
- Secure the network using a firewall
- Never source hardware from an untrusted vendor
- Inspect and verify the metal servers you are using for the clusters are the ones you intended to use
- If possible, use a separate L2 network for EKS Anywhere baremetal clusters
- Conduct thorough audits of access, users, logs and other exploitable venues periodically
Benchmark tests for cluster hardening
EKS Anywhere creates clusters with server hardening configurations out of the box, via the use of security flags and opinionated default templates. You can verify the security posture of your EKS Anywhere cluster by using a tool called kube-bench
, that checks whether Kubernetes is deployed securely.
kube-bench runs checks documented in the CIS Benchmark for Kubernetes
, such as, pod specification file permissions, disabling insecure arguments, and so on.
Refer to the EKS Anywhere CIS Self-Assessment Guide for more information on how to evaluate the security configurations of your EKS Anywhere cluster.
6.1 - CIS Self-Assessment Guide
The CIS Benchmark self-assessment guide serves to help EKS Anywhere users evaluate the level of security of the hardened cluster configuration against Kubernetes benchmark controls from the Center for Information Security (CIS). This guide will walk through the various controls and provide updated example commands to audit compliance in EKS Anywhere clusters.
You can verify the security posture of your EKS Anywhere cluster by using a tool called kube-bench
. The ideal way to run the benchmark tests on your EKS Anywhere cluster is to apply the Kube-bench Job YAMLs
to the cluster. This runs the kube-bench tests on a Pod on the cluster, and the logs of the Pod provide the test results.
Kube-bench currently does not support unstacked etcd topology (which is the default for EKS Anywhere), so the following checks are skipped in the default kube-bench Job YAML. If you created your EKS Anywhere cluster with stacked etcd configuration, you can apply the stacked etcd Job YAML
instead.
| Check number | Check description |
|---|---|
| 1.1.7 | Ensure that the etcd pod specification file permissions are set to 644 or more restrictive |
| 1.1.8 | Ensure that the etcd pod specification file ownership is set to root:root |
| 1.1.11 | Ensure that the etcd data directory permissions are set to 700 or more restrictive |
| 1.1.12 | Ensure that the etcd data directory ownership is set to etcd:etcd |
The following tests are also skipped, because they are not applicable or enforce settings that might make the cluster unstable.
| Check number | Check description | Reason for skipping |
|---|---|---|
| Controlplane node configuration | ||
| 1.2.6 | Ensure that the –kubelet-certificate-authority argument is set as appropriate | When generating serving certificates, functionality could break in conjunction with hostname overrides which are required for certain cloud providers |
| 1.2.16 | Ensure that the admission control plugin PodSecurityPolicy is set | Enabling Pod Security Policy can cause applications to unexpectedly fail |
| 1.2.32 | Ensure that the –encryption-provider-config argument is set as appropriate | Enabling encryption changes how data can be recovered as data is encrypted |
| 1.2.33 | Ensure that encryption providers are appropriately configured | Enabling encryption changes how data can be recovered as data is encrypted |
| Worker node configuration | ||
| 4.2.6 | Ensure that the –protect-kernel-defaults argument is set to true | System level configurations are required before provisioning the cluster in order for this argument to be set to true |
| 4.2.10 | Ensure that the –tls-cert-file and –tls-private-key-file arguments are set as appropriate | When generating serving certificates, functionality could break in conjunction with hostname overrides which are required for certain cloud providers |
Note
Running kube-bench on Bottlerocket controlplane nodes currently produces false negatives with respect to pod specification file (manifest) permissions, since the default configuration does not include the paths in which Bottlerocket places these manifests. This issue is being tracked here.7 - Packages
Curated package list
| Name | Description | Versions | GitHub |
|---|---|---|---|
| ADOT | ADOT Collector is an AWS distribution of the OpenTelemetry Collector, which provides a vendor-agnostic solution to receive, process and export telemetry data. | v0.25.0 | https://github.com/aws-observability/aws-otel-collector |
| Cert-manager | Cert-manager is a certificate manager for Kubernetes clusters. | v1.9.1 | https://github.com/cert-manager/cert-manager |
| Cluster Autoscaler | Cluster Autoscaler is a component that automatically adjusts the size of a Kubernetes Cluster so that all pods have a place to run and there are no unneeded nodes. | v9.21.0 | https://github.com/kubernetes/autoscaler |
| Emissary Ingress | Emissary Ingress is an open source Ingress supporting API Gateway + Layer 7 load balancer built on Envoy Proxy. |
v3.3.0 | https://github.com/emissary-ingress/emissary/ |
| Harbor | Harbor is an open source trusted cloud native registry project that stores, signs, and scans content. | v2.7.1
v2.5.1 |
https://github.com/goharbor/harbor
https://github.com/goharbor/harbor-helm |
| MetalLB | MetalLB is a virtual IP provider for services of type LoadBalancer supporting ARP and BGP. |
v0.13.7 | https://github.com/metallb/metallb/ |
| Metrics Server | Metrics Server is a scalable, efficient source of container resource metrics for Kubernetes built-in autoscaling pipelines. | v3.8.2 | https://github.com/kubernetes-sigs/metrics-server |
| Prometheus | Prometheus is an open-source systems monitoring and alerting toolkit that collects and stores metrics as time series data. | v2.41.0 | https://github.com/prometheus/prometheus |
7.1 - Packages configuration
This is a generic template with detailed descriptions below for reference. To generate your own package configuration, follow instructions from Package Management section and modify it using descriptions below.
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: PackageBundleController
metadata:
name: eksa-packages-bundle-controller
namespace: eksa-packages
spec:
activeBundle: v1-21-83
defaultImageRegistry: 783794618700.dkr.ecr.us-west-2.amazonaws.com
defaultRegistry: public.ecr.aws/eks-anywhere
privateRegistry: ""
upgradeCheckInterval: 24h0m0s
---
apiVersion: packages.eks.amazonaws.com/v1alpha1
kind: PackageBundle
metadata:
name: package-bundle
namespace: eksa-packages
spec:
packages:
- name: hello-eks-anywhere
source:
repository: hello-eks-anywhere
versions:
- digest: sha256:c31242a2f94a58017409df163debc01430de65ded6bdfc5496c29d6a6cbc0d94
images:
- digest: sha256:26e3f2f9aa546fee833218ece3fe7561971fd905cef40f685fd1b5b09c6fb71d
repository: hello-eks-anywhere
name: 0.1.1-083e68edbbc62ca0228a5669e89e4d3da99ff73b
schema: H4sIAJc5EW...
---
apiVersion: packages.eks.amazonaws.com/v1alpha1
kind: Package
metadata:
name: my-hello-eks-anywhere
namespace: eksa-packages
spec:
config: |
title: "My Hello"
packageName: hello-eks-anywhere
targetNamespace: eksa-packages
API Reference
Packages:
packages.eks.amazonaws.com/v1alpha1
Resource Types:
PackageBundleController
PackageBundleController is the Schema for the packagebundlecontroller API.
| Name | Type | Description | Required |
|---|---|---|---|
| apiVersion | string | packages.eks.amazonaws.com/v1alpha1 | true |
| kind | string | PackageBundleController | true |
| metadata | object | Refer to the Kubernetes API documentation for the fields of the `metadata` field. | true |
| spec | object |
PackageBundleControllerSpec defines the desired state of PackageBundleController. |
false |
| status | object |
PackageBundleControllerStatus defines the observed state of PackageBundleController. |
false |
PackageBundleController.spec
PackageBundleControllerSpec defines the desired state of PackageBundleController.
| Name | Type | Description | Required |
|---|---|---|---|
| activeBundle | string |
ActiveBundle is name of the bundle from which packages should be sourced. |
false |
| bundleRepository | string |
Repository portion of an OCI address to the bundle Default: eks-anywhere-packages-bundles |
false |
| createNamespace | boolean |
Allow target namespace creation by the controller Default: false |
false |
| defaultImageRegistry | string |
DefaultImageRegistry for pulling images Default: 783794618700.dkr.ecr.us-west-2.amazonaws.com |
false |
| defaultRegistry | string |
DefaultRegistry for pulling helm charts and the bundle Default: public.ecr.aws/eks-anywhere |
false |
| logLevel | integer |
LogLevel controls the verbosity of logging in the controller. Format: int32 |
false |
| privateRegistry | string |
PrivateRegistry is the registry being used for all images, charts and bundles |
false |
| upgradeCheckInterval | string |
UpgradeCheckInterval is the time between upgrade checks.
The format is that of time's ParseDuration. Default: 24h |
false |
| upgradeCheckShortInterval | string |
UpgradeCheckShortInterval time between upgrade checks if there is a problem.
The format is that of time's ParseDuration. Default: 1h |
false |
PackageBundleController.status
PackageBundleControllerStatus defines the observed state of PackageBundleController.
| Name | Type | Description | Required |
|---|---|---|---|
| detail | string |
Detail of the state. |
false |
| spec | object |
Spec previous settings |
false |
| state | enum |
State of the bundle controller. Enum: ignored, active, disconnected, upgrade available |
false |
PackageBundleController.status.spec
Spec previous settings
| Name | Type | Description | Required |
|---|---|---|---|
| activeBundle | string |
ActiveBundle is name of the bundle from which packages should be sourced. |
false |
| bundleRepository | string |
Repository portion of an OCI address to the bundle Default: eks-anywhere-packages-bundles |
false |
| createNamespace | boolean |
Allow target namespace creation by the controller Default: false |
false |
| defaultImageRegistry | string |
DefaultImageRegistry for pulling images Default: 783794618700.dkr.ecr.us-west-2.amazonaws.com |
false |
| defaultRegistry | string |
DefaultRegistry for pulling helm charts and the bundle Default: public.ecr.aws/eks-anywhere |
false |
| logLevel | integer |
LogLevel controls the verbosity of logging in the controller. Format: int32 |
false |
| privateRegistry | string |
PrivateRegistry is the registry being used for all images, charts and bundles |
false |
| upgradeCheckInterval | string |
UpgradeCheckInterval is the time between upgrade checks.
The format is that of time's ParseDuration. Default: 24h |
false |
| upgradeCheckShortInterval | string |
UpgradeCheckShortInterval time between upgrade checks if there is a problem.
The format is that of time's ParseDuration. Default: 1h |
false |
PackageBundle
PackageBundle is the Schema for the packagebundle API.
| Name | Type | Description | Required |
|---|---|---|---|
| apiVersion | string | packages.eks.amazonaws.com/v1alpha1 | true |
| kind | string | PackageBundle | true |
| metadata | object | Refer to the Kubernetes API documentation for the fields of the `metadata` field. | true |
| spec | object |
PackageBundleSpec defines the desired state of PackageBundle. |
false |
| status | object |
PackageBundleStatus defines the observed state of PackageBundle. |
false |
PackageBundle.spec
PackageBundleSpec defines the desired state of PackageBundle.
| Name | Type | Description | Required |
|---|---|---|---|
| packages | []object |
Packages supported by this bundle. |
true |
| minControllerVersion | string |
Minimum required packages controller version |
false |
PackageBundle.spec.packages[index]
BundlePackage specifies a package within a bundle.
| Name | Type | Description | Required |
|---|---|---|---|
| source | object |
Source location for the package (probably a helm chart). |
true |
| name | string |
Name of the package. |
false |
| workloadonly | boolean |
WorkloadOnly specifies if the package should be installed only on the workload cluster |
false |
PackageBundle.spec.packages[index].source
Source location for the package (probably a helm chart).
| Name | Type | Description | Required |
|---|---|---|---|
| repository | string |
Repository within the Registry where the package is found. |
true |
| versions | []object |
Versions of the package supported by this bundle. |
true |
| registry | string |
Registry in which the package is found. |
false |
PackageBundle.spec.packages[index].source.versions[index]
SourceVersion describes a version of a package within a repository.
| Name | Type | Description | Required |
|---|---|---|---|
| digest | string |
Digest is a checksum value identifying the version of the package and its contents. |
true |
| name | string |
Name is a human-friendly description of the version, e.g. "v1.0". |
true |
| dependencies | []string |
Dependencies to be installed before the package |
false |
| images | []object |
Images is a list of images used by this version of the package. |
false |
| schema | string |
Schema is a base64 encoded, gzipped json schema used to validate package configurations. |
false |
PackageBundle.spec.packages[index].source.versions[index].images[index]
VersionImages is an image used by a version of a package.
| Name | Type | Description | Required |
|---|---|---|---|
| digest | string |
Digest is a checksum value identifying the version of the package and its contents. |
true |
| repository | string |
Repository within the Registry where the package is found. |
true |
PackageBundle.status
PackageBundleStatus defines the observed state of PackageBundle.
| Name | Type | Description | Required |
|---|---|---|---|
| state | enum |
PackageBundleStateEnum defines the observed state of PackageBundle. Enum: available, ignored, invalid, controller upgrade required |
true |
| spec | object |
PackageBundleSpec defines the desired state of PackageBundle. |
false |
PackageBundle.status.spec
PackageBundleSpec defines the desired state of PackageBundle.
| Name | Type | Description | Required |
|---|---|---|---|
| packages | []object |
Packages supported by this bundle. |
true |
| minControllerVersion | string |
Minimum required packages controller version |
false |
PackageBundle.status.spec.packages[index]
BundlePackage specifies a package within a bundle.
| Name | Type | Description | Required |
|---|---|---|---|
| source | object |
Source location for the package (probably a helm chart). |
true |
| name | string |
Name of the package. |
false |
| workloadonly | boolean |
WorkloadOnly specifies if the package should be installed only on the workload cluster |
false |
PackageBundle.status.spec.packages[index].source
Source location for the package (probably a helm chart).
| Name | Type | Description | Required |
|---|---|---|---|
| repository | string |
Repository within the Registry where the package is found. |
true |
| versions | []object |
Versions of the package supported by this bundle. |
true |
| registry | string |
Registry in which the package is found. |
false |
PackageBundle.status.spec.packages[index].source.versions[index]
SourceVersion describes a version of a package within a repository.
| Name | Type | Description | Required |
|---|---|---|---|
| digest | string |
Digest is a checksum value identifying the version of the package and its contents. |
true |
| name | string |
Name is a human-friendly description of the version, e.g. "v1.0". |
true |
| dependencies | []string |
Dependencies to be installed before the package |
false |
| images | []object |
Images is a list of images used by this version of the package. |
false |
| schema | string |
Schema is a base64 encoded, gzipped json schema used to validate package configurations. |
false |
PackageBundle.status.spec.packages[index].source.versions[index].images[index]
VersionImages is an image used by a version of a package.
| Name | Type | Description | Required |
|---|---|---|---|
| digest | string |
Digest is a checksum value identifying the version of the package and its contents. |
true |
| repository | string |
Repository within the Registry where the package is found. |
true |
Package
Package is the Schema for the package API.
| Name | Type | Description | Required |
|---|---|---|---|
| apiVersion | string | packages.eks.amazonaws.com/v1alpha1 | true |
| kind | string | Package | true |
| metadata | object | Refer to the Kubernetes API documentation for the fields of the `metadata` field. | true |
| spec | object |
PackageSpec defines the desired state of an package. |
false |
| status | object |
PackageStatus defines the observed state of Package. |
false |
Package.spec
PackageSpec defines the desired state of an package.
| Name | Type | Description | Required |
|---|---|---|---|
| packageName | string |
PackageName is the name of the package as specified in the bundle. |
true |
| config | string |
Config for the package. |
false |
| packageVersion | string |
PackageVersion is a human-friendly version name or sha256 checksum for the package, as specified in the bundle. |
false |
| targetNamespace | string |
TargetNamespace defines where package resources will be deployed. |
false |
Package.status
PackageStatus defines the observed state of Package.
| Name | Type | Description | Required |
|---|---|---|---|
| currentVersion | string |
Version currently installed. |
true |
| source | object |
Source associated with the installation. |
true |
| detail | string |
Detail of the state. |
false |
| spec | object |
Spec previous settings |
false |
| state | enum |
State of the installation. Enum: initializing, installing, installing dependencies, installed, updating, uninstalling, unknown |
false |
| targetVersion | string |
Version to be installed. |
false |
| upgradesAvailable | []object |
UpgradesAvailable indicates upgraded versions in the bundle. |
false |
Package.status.source
Source associated with the installation.
| Name | Type | Description | Required |
|---|---|---|---|
| digest | string |
Digest is a checksum value identifying the version of the package and its contents. |
true |
| registry | string |
Registry in which the package is found. |
true |
| repository | string |
Repository within the Registry where the package is found. |
true |
| version | string |
Versions of the package supported. |
true |
Package.status.spec
Spec previous settings
| Name | Type | Description | Required |
|---|---|---|---|
| packageName | string |
PackageName is the name of the package as specified in the bundle. |
true |
| config | string |
Config for the package. |
false |
| packageVersion | string |
PackageVersion is a human-friendly version name or sha256 checksum for the package, as specified in the bundle. |
false |
| targetNamespace | string |
TargetNamespace defines where package resources will be deployed. |
false |
Package.status.upgradesAvailable[index]
PackageAvailableUpgrade details the package’s available upgrade versions.
| Name | Type | Description | Required |
|---|---|---|---|
| tag | string |
Tag is a specific version number or sha256 checksum for the package upgrade. |
true |
| version | string |
Version is a human-friendly version name for the package upgrade. |
true |
7.2 - Configuration Best Practice
Best Practice
Any package configuration options listed under Reference/Packages should be modified through package yaml files (with kind: Package) through command eksctl anywhere apply package -f packageFileName. Modifying objects outside of package yaml files may lead to unpredictable behaviors.
For automatic namespace (targetNamespace) creation, see createNamespace field: PackagebundleController.spec
7.3 - ADOT Configuration
OpenTelemetry Collector provides a vendor-agnostic solution to receive, process and export telemetry data. It removes the need to run, operate, and maintain multiple agents/collectors. ADOT Collector is an AWS-supported distribution of the OpenTelemetry Collector.
Best Practice
Any package configuration options listed under Reference/Packages should be modified through package yaml files (with kind: Package) through command eksctl anywhere apply package -f packageFileName. Modifying objects outside of package yaml files may lead to unpredictable behaviors.
For automatic namespace (targetNamespace) creation, see createNamespace field: PackagebundleController.spec
Configuration options for ADOT
7.3.1 - v0.21.1
Configuring ADOT in EKS Anywhere package spec
Example
We included a sample configuration below for reference. For in-depth examples and use cases, please refer to ADOT workshop.
apiVersion: packages.eks.amazonaws.com/v1alpha1
kind: Package
metadata:
name: my-adot
namespace: eksa-packages-<cluster-name>
spec:
packageName: adot
targetNamespace: observability
config: |
mode: daemonset
Configurable parameters and default values under spec.config
| Parameter | Description | Default |
|---|---|---|
| General | ||
| hostNetwork | Indicates if the pod should run in the host networking namespace. | false |
| image.pullPolicy | Specifies image pull policy: IfNotPresent, Always, Never. |
"IfNotPresent" |
| mode | Specifies Collector deployment options: daemonset, deployment, or statefulset. |
"daemonset" |
| ports.[*].containerPort | Specifies containerPort used. | See footnote 1 |
| ports.[*].enabled | Indicates if a port is enabled. | See footnote 1 |
| ports.[*].hostPort | Specifies hostPort used. | See footnote 1 |
| ports.[*].protocol | Specifies protocol used. | See footnote 1 |
| ports.[*].servicePort | Specifies servicePort used. | See footnote 1 |
| resources.limits.cpu | Specifies CPU resource limits for containers. | 1 |
| resources.limits.memory | Specifies memory resource limits for containers. | "2Gi" |
| Config | ||
| config.config | Specifies Collector receiver, processor, exporter, and extensions configurations. Refer to aws-otel-collector for full details. Note EKS Anywhere ADOT package version matches the exact aws-otel-collector version. | See footnote 2 |
| config.config.receiver | Specifies how data gets in the Collector. Receivers can be either push or pull based, and support one or more data source. | See footnote 2 |
| config.config.processor | Specifies how processors are run on data between the stage of being received and being exported. Processors are optional though some are recommended. | See footnote 2 |
| config.config.exporters | Specifies how data gets sent to backends/destinations. Exporters can be either push or pull based, and support one or more data source. | See footnote 2 |
| config.config.extensions | Specifies tasks that do not involve processing telemetry data. Examples of extensions include health monitoring, service discovery, and data forwarding. Extensions are optional. | See footnote 2 |
| config.config.service | Specifies what components are enabled in the Collector based on the configuration found in the receivers, processors, exporters, and extensions sections. If a component is configured, but not defined within the service section, then it is not enabled. | See footnote 2 |
| Deployment mode only | ||
| replicaCount | Specifies replicaCount for pods. | 1 |
| service.type | Specifies service types: ClusterIP, NodePort, LoadBalancer, ExternalName. |
"ClusterIP" |
-
The default
portsenablesotlpandotlp-http. See below specification for details.↩︎apiVersion: packages.eks.amazonaws.com/v1alpha1 kind: Package ... spec: config: | ports: otlp: enabled: true containerPort: 4317 servicePort: 4317 hostPort: 4317 protocol: TCP otlp-http: enabled: true containerPort: 4318 servicePort: 4318 hostPort: 4318 protocol: TCP -
The default
config.configdeploys an ADOT Collector with the metrics pipeline, which includes otlp and prometheus receiver, and logging exporter. See below specification for details.↩︎apiVersion: packages.eks.amazonaws.com/v1alpha1 kind: Package ... spec: config: | config: receivers: otlp: protocols: grpc: endpoint: 0.0.0.0:4317 http: endpoint: 0.0.0.0:4318 prometheus: config: scrape_configs: - job_name: opentelemetry-collector scrape_interval: 10s static_configs: - targets: - ${MY_POD_IP}:8888 processors: batch: {} memory_limiter: null exporters: logging: loglevel: info extensions: health_check: {} memory_ballast: {} service: telemetry: metrics: address: 0.0.0.0:8888 extensions: - health_check - memory_ballast pipelines: metrics: exporters: - logging processors: - memory_limiter - batch receivers: - otlp - prometheus
7.3.2 - v0.23.0
Configuring ADOT in EKS Anywhere package spec
Example
We included a sample configuration below for reference. For in-depth examples and use cases, please refer to ADOT workshop.
apiVersion: packages.eks.amazonaws.com/v1alpha1
kind: Package
metadata:
name: my-adot
namespace: eksa-packages-<cluster-name>
spec:
packageName: adot
targetNamespace: observability
config: |
mode: daemonset
Configurable parameters and default values under spec.config
| Parameter | Description | Default |
|---|---|---|
| General | ||
| hostNetwork | Indicates if the pod should run in the host networking namespace. | false |
| image.pullPolicy | Specifies image pull policy: IfNotPresent, Always, Never. |
"IfNotPresent" |
| mode | Specifies Collector deployment options: daemonset, deployment, or statefulset. |
"daemonset" |
| ports.[*].containerPort | Specifies containerPort used. | See footnote 1 |
| ports.[*].enabled | Indicates if a port is enabled. | See footnote 1 |
| ports.[*].hostPort | Specifies hostPort used. | See footnote 1 |
| ports.[*].protocol | Specifies protocol used. | See footnote 1 |
| ports.[*].servicePort | Specifies servicePort used. | See footnote 1 |
| resources.limits.cpu | Specifies CPU resource limits for containers. | 1 |
| resources.limits.memory | Specifies memory resource limits for containers. | "2Gi" |
| Config | ||
| config.config | Specifies Collector receiver, processor, exporter, and extensions configurations. Refer to aws-otel-collector for full details. Note EKS Anywhere ADOT package version matches the exact aws-otel-collector version. | See footnote 2 |
| config.config.receiver | Specifies how data gets in the Collector. Receivers can be either push or pull based, and support one or more data source. | See footnote 2 |
| config.config.processor | Specifies how processors are run on data between the stage of being received and being exported. Processors are optional though some are recommended. | See footnote 2 |
| config.config.exporters | Specifies how data gets sent to backends/destinations. Exporters can be either push or pull based, and support one or more data source. | See footnote 2 |
| config.config.extensions | Specifies tasks that do not involve processing telemetry data. Examples of extensions include health monitoring, service discovery, and data forwarding. Extensions are optional. | See footnote 2 |
| config.config.service | Specifies what components are enabled in the Collector based on the configuration found in the receivers, processors, exporters, and extensions sections. If a component is configured, but not defined within the service section, then it is not enabled. | See footnote 2 |
| Deployment mode only | ||
| replicaCount | Specifies replicaCount for pods. | 1 |
| service.type | Specifies service types: ClusterIP, NodePort, LoadBalancer, ExternalName. |
"ClusterIP" |
-
The default
portsenablesotlpandotlp-http. See below specification for details.↩︎apiVersion: packages.eks.amazonaws.com/v1alpha1 kind: Package ... spec: config: | ports: otlp: enabled: true containerPort: 4317 servicePort: 4317 hostPort: 4317 protocol: TCP otlp-http: enabled: true containerPort: 4318 servicePort: 4318 hostPort: 4318 protocol: TCP -
The default
config.configdeploys an ADOT Collector with the metrics pipeline, which includes otlp and prometheus receiver, and logging exporter. See below specification for details.↩︎apiVersion: packages.eks.amazonaws.com/v1alpha1 kind: Package ... spec: config: | config: receivers: otlp: protocols: grpc: endpoint: 0.0.0.0:4317 http: endpoint: 0.0.0.0:4318 prometheus: config: scrape_configs: - job_name: opentelemetry-collector scrape_interval: 10s static_configs: - targets: - ${MY_POD_IP}:8888 processors: batch: {} memory_limiter: null exporters: logging: loglevel: info extensions: health_check: {} memory_ballast: {} service: telemetry: metrics: address: 0.0.0.0:8888 extensions: - health_check - memory_ballast pipelines: metrics: exporters: - logging processors: - memory_limiter - batch receivers: - otlp - prometheus
7.3.3 - v0.25.0
Configuring ADOT in EKS Anywhere package spec
Example
We included a sample configuration below for reference. For in-depth examples and use cases, please refer to ADOT workshop.
apiVersion: packages.eks.amazonaws.com/v1alpha1
kind: Package
metadata:
name: my-adot
namespace: eksa-packages-<cluster-name>
spec:
packageName: adot
targetNamespace: observability
config: |
mode: daemonset
Configurable parameters and default values under spec.config
| Parameter | Description | Default |
|---|---|---|
| General | ||
| hostNetwork | Indicates if the pod should run in the host networking namespace. | false |
| image.pullPolicy | Specifies image pull policy: IfNotPresent, Always, Never. |
"IfNotPresent" |
| mode | Specifies Collector deployment options: daemonset, deployment, or statefulset. |
"daemonset" |
| ports.[*].containerPort | Specifies containerPort used. | See footnote 1 |
| ports.[*].enabled | Indicates if a port is enabled. | See footnote 1 |
| ports.[*].hostPort | Specifies hostPort used. | See footnote 1 |
| ports.[*].protocol | Specifies protocol used. | See footnote 1 |
| ports.[*].servicePort | Specifies servicePort used. | See footnote 1 |
| resources.limits.cpu | Specifies CPU resource limits for containers. | 1 |
| resources.limits.memory | Specifies memory resource limits for containers. | "2Gi" |
| Config | ||
| config.config | Specifies Collector receiver, processor, exporter, and extensions configurations. Refer to aws-otel-collector for full details. Note EKS Anywhere ADOT package version matches the exact aws-otel-collector version. | See footnote 2 |
| config.config.receiver | Specifies how data gets in the Collector. Receivers can be either push or pull based, and support one or more data source. | See footnote 2 |
| config.config.processor | Specifies how processors are run on data between the stage of being received and being exported. Processors are optional though some are recommended. | See footnote 2 |
| config.config.exporters | Specifies how data gets sent to backends/destinations. Exporters can be either push or pull based, and support one or more data source. | See footnote 2 |
| config.config.extensions | Specifies tasks that do not involve processing telemetry data. Examples of extensions include health monitoring, service discovery, and data forwarding. Extensions are optional. | See footnote 2 |
| config.config.service | Specifies what components are enabled in the Collector based on the configuration found in the receivers, processors, exporters, and extensions sections. If a component is configured, but not defined within the service section, then it is not enabled. | See footnote 2 |
| Deployment mode only | ||
| replicaCount | Specifies replicaCount for pods. | 1 |
| service.type | Specifies service types: ClusterIP, NodePort, LoadBalancer, ExternalName. |
"ClusterIP" |
-
The default
portsenablesotlpandotlp-http. See below specification for details.↩︎apiVersion: packages.eks.amazonaws.com/v1alpha1 kind: Package ... spec: config: | ports: otlp: enabled: true containerPort: 4317 servicePort: 4317 hostPort: 4317 protocol: TCP otlp-http: enabled: true containerPort: 4318 servicePort: 4318 hostPort: 4318 protocol: TCP -
The default
config.configdeploys an ADOT Collector with the metrics pipeline, which includes otlp and prometheus receiver, and logging exporter. See below specification for details.↩︎apiVersion: packages.eks.amazonaws.com/v1alpha1 kind: Package ... spec: config: | config: receivers: otlp: protocols: grpc: endpoint: 0.0.0.0:4317 http: endpoint: 0.0.0.0:4318 prometheus: config: scrape_configs: - job_name: opentelemetry-collector scrape_interval: 10s static_configs: - targets: - ${MY_POD_IP}:8888 processors: batch: {} memory_limiter: null exporters: logging: loglevel: info extensions: health_check: {} memory_ballast: {} service: telemetry: metrics: address: 0.0.0.0:8888 extensions: - health_check - memory_ballast pipelines: metrics: exporters: - logging processors: - memory_limiter - batch receivers: - otlp - prometheus
7.4 - Cert-Manager Configuration
The cert-manager package adds certificates and certificate issuers as resource types in Kubernetes clusters, and simplifies the process of obtaining, renewing and using those certificates.
Best Practice
Any package configuration options listed under Reference/Packages should be modified through package yaml files (with kind: Package) through command eksctl anywhere apply package -f packageFileName. Modifying objects outside of package yaml files may lead to unpredictable behaviors.
For automatic namespace (targetNamespace) creation, see createNamespace field: PackagebundleController.spec
Configuration options for Cert-Manager
7.4.1 - v1.9.1
Configuring Cert-Manager in EKS Anywhere package spec
Example
apiVersion: packages.eks.amazonaws.com/v1alpha1
kind: Package
metadata:
name: my-cert-manager
namespace: eksa-packages-<cluster-name>
spec:
packageName: cert-manager
config: |
global:
logLevel: 4
The following table lists the configurable parameters of the cert-manager package spec and the default values.
| Parameter | Description | Default |
|---|---|---|
| General | ||
namespace |
The namespace to use for installing cert-manager package | cert-manager |
imagePullPolicy |
The image pull policy | IfNotPresent |
| global | ||
global.logLevel |
The log level: integer from 0-6 | 2 |
| Webhook | ||
webhook.timeoutSeconds |
The time in seconds to wait for the webhook to connect with the kube-api server | 0 |
7.5 - Cluster Autoscaler Configuration
Cluster Autoscaler is a component that automatically adjusts the size of a Kubernetes Cluster so that all pods have a place to run and there are no unneeded nodes.
Configuration options for Cluster Autoscaler
7.5.1 - v9.21.0
Configuring Cluster Autoscaler in EKS Anywhere package spec
| Parameter | Description | Default |
|---|---|---|
| General | ||
| cloudProvider | Cluster Autoscaler cloud provider. This should always be clusterapi. Example: cloudProvider: “clusterapi” |
“clusterapi” |
| autoDiscovery.clusterName | Name of the kubernetes cluster this autoscaler package should autoscale. Example: autoDiscovery.clusterName: “mgmt-cluster” |
false |
| clusterAPIMode | Where Cluster Autoscaler should look for a kubeconfig to communicate with the cluster it will manage. See https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/clusterapi/README.md#connecting-cluster-autoscaler-to-cluster-api-management-and-workload-clusters
Example: clusterAPIMode: “incluster-kubeconfig” |
“incluster-incluster” |
| clusterAPICloudConfigPath | Path to kubeconfig for connecting to Cluster API Management Cluster, only used if clusterAPIMode=kubeconfig-kubeconfig or incluster-kubeconfig Example: clusterAPICloudConfigPath: “/etc/kubernetes/value” |
“/etc/kubernetes/mgmt-kubeconfig” |
| extraVolumeSecrets | Additional volumes to mount from Secrets. Example: extraVolumeSecrets: {} |
{} |
7.6 - Emissary Configuration
Emissary Ingress is an open-source Kubernetes-native API Gateway + Layer 7 load balancer + Kubernetes Ingress built on Envoy Proxy.
Best Practice
Any package configuration options listed under Reference/Packages should be modified through package yaml files (with kind: Package) through command eksctl anywhere apply package -f packageFileName. Modifying objects outside of package yaml files may lead to unpredictable behaviors.
For automatic namespace (targetNamespace) creation, see createNamespace field: PackagebundleController.spec
Configuration options for Emissary
7.6.1 - v3.0.0
Configuring Emissary Ingress in EKS Anywhere package spec
| Parameter | Description | Default |
|---|---|---|
| General | ||
| hostNetwork | Whether Emissary will use the host network, useful for on-premise setup . Example: hostNetwork: false |
false |
| createDefaultListeners | Whether Emissary should be created with default listeners, HTTP on port 8080 and HTTPS on port 8443. Example: createDefaultListeners: false |
false |
| replicaCount | Replica count for Emissary to deploy. Example: replicaCount: 2 |
2 |
| daemonSet | Whether to create Emissary as a Daemonset instead of a deployment Example: daemonSet: false |
false |
7.6.2 - v3.3.0
Emissary version 0.3.3 has decoupled the CRD portion of the package, and now supports installing multiple instances of the emissary package in the same cluster.
Configuring Emissary Ingress in EKS Anywhere package spec
| Parameter | Description | Default |
|---|---|---|
| General | ||
| hostNetwork | Whether Emissary will use the host network, useful for on-premise setup . Example: hostNetwork: false |
false |
| createDefaultListeners | Whether Emissary should be created with default listeners, HTTP on port 8080 and HTTPS on port 8443. Example: createDefaultListeners: false |
false |
| replicaCount | Replica count for Emissary to deploy. Example: replicaCount: 2 |
2 |
| daemonSet | Whether to create Emissary as a Daemonset instead of a deployment Example: daemonSet: false |
false |
7.7 - Harbor configuration
Harbor is an open source trusted cloud native registry project that stores, signs, and scans content. Harbor extends the open source Docker Distribution by adding the functionalities usually required by users such as security, identity and management. Having a registry closer to the build and run environment can improve the image transfer efficiency. Harbor supports replication of images between registries, and also offers advanced security features such as user management, access control and activity auditing.
Best Practice
Any package configuration options listed under Reference/Packages should be modified through package yaml files (with kind: Package) through command eksctl anywhere apply package -f packageFileName. Modifying objects outside of package yaml files may lead to unpredictable behaviors.
For automatic namespace (targetNamespace) creation, see createNamespace field: PackagebundleController.spec
Configuration options for Harbor
7.7.1 - v2.5.0
Trivy, Notary and Chartmuseum are not supported at this moment.
Configuring Harbor in EKS Anywhere package spec
The following table lists the configurable parameters of the Harbor package spec and the default values.
| Parameter | Description | Default |
|---|---|---|
| General | ||
externalURL |
The external URL for Harbor core service | https://127.0.0.1:30003 |
imagePullPolicy |
The image pull policy | IfNotPresent |
logLevel |
The log level: debug, info, warning, error or fatal |
info |
harborAdminPassword |
The initial password of the Harbor admin account. Change it from the portal after launching Harbor |
Harbor12345 |
secretKey |
The key used for encryption. Must be a string of 16 chars | "" |
| Expose | ||
expose.type |
How to expose the service: nodePort or loadBalancer, other values will be ignored and the creation of the service will be skipped. |
nodePort |
expose.tls.enabled |
Enable TLS or not. | true |
expose.tls.certSource |
The source of the TLS certificate. Set as auto, secret or none and fill the information in the corresponding section: 1) auto: generate the TLS certificate automatically 2) secret: read the TLS certificate from the specified secret. The TLS certificate can be generated manually or by cert manager 3) none: configure no TLS certificate. |
secret |
expose.tls.auto.commonName |
The common name used to generate the certificate. It’s necessary when expose.tls.certSource is set to auto |
|
expose.tls.secret.secretName |
The name of the secret which contains keys named: tls.crt - the certificate; tls.key - the private key |
harbor-tls-secret |
expose.nodePort.name |
The name of the NodePort service | harbor |
expose.nodePort.ports.http.port |
The service port Harbor listens on when serving HTTP | 80 |
expose.nodePort.ports.http.nodePort |
The node port Harbor listens on when serving HTTP | 30002 |
expose.nodePort.ports.https.port |
The service port Harbor listens on when serving HTTPS | 443 |
expose.nodePort.ports.https.nodePort |
The node port Harbor listens on when serving HTTPS | 30003 |
expose.loadBalancer.name |
The name of the service | harbor |
expose.loadBalancer.IP |
The IP address of the loadBalancer. It only works when the loadBalancer supports assigning an IP address | "" |
expose.loadBalancer.ports.httpPort |
The service port Harbor listens on when serving HTTP | 80 |
expose.loadBalancer.ports.httpsPort |
The service port Harbor listens on when serving HTTPS | 30002 |
expose.loadBalancer.annotations |
The annotations attached to the loadBalancer service | {} |
expose.loadBalancer.sourceRanges |
List of IP address ranges to assign to loadBalancerSourceRanges | [] |
| Internal TLS | ||
internalTLS.enabled |
Enable TLS for the components (core, jobservice, portal, and registry) | true |
| Persistence | ||
persistence.resourcePolicy |
Setting it to keep to avoid removing PVCs during a helm delete operation. Leaving it empty will delete PVCs after the chart is deleted. Does not affect PVCs created for internal database and redis components. |
keep |
persistence.persistentVolumeClaim.registry.size |
The size of the volume | 5Gi |
persistence.persistentVolumeClaim.registry.storageClass |
Specify the storageClass used to provision the volume, or the default StorageClass will be used (the default). Set it to - to disable dynamic provisioning |
"" |
persistence.persistentVolumeClaim.jobservice.size |
The size of the volume | 1Gi |
persistence.persistentVolumeClaim.jobservice.storageClass |
Specify the storageClass used to provision the volume, or the default StorageClass will be used (the default). Set it to - to disable dynamic provisioning |
"" |
persistence.persistentVolumeClaim.database.size |
The size of the volume. If an external database is used, the setting will be ignored | 1Gi |
persistence.persistentVolumeClaim.database.storageClass |
Specify the storageClass used to provision the volume, or the default StorageClass will be used (the default). Set it to - to disable dynamic provisioning. If an external database is used, the setting will be ignored |
"" |
persistence.persistentVolumeClaim.redis.size |
The size of the volume. If an external Redis is used, the setting will be ignored | 1Gi |
persistence.persistentVolumeClaim.redis.storageClass |
Specify the storageClass used to provision the volumem, or the default StorageClass will be used (the default). Set it to - to disable dynamic provisioning. If an external Redis is used, the setting will be ignored |
"" |
| Registry | ||
registry.relativeurls |
If true, the registry returns relative URLs in Location headers. The client is responsible for resolving the correct URL. Needed if harbor is behind a reverse proxy | false |
7.7.2 - v2.5.1
Notary and Chartmuseum are not supported at this moment.
Configuring Harbor in EKS Anywhere package spec
The following table lists the configurable parameters of the Harbor package spec and the default values.
| Parameter | Description | Default |
|---|---|---|
| General | ||
externalURL |
The external URL for Harbor core service | https://127.0.0.1:30003 |
imagePullPolicy |
The image pull policy | IfNotPresent |
logLevel |
The log level: debug, info, warning, error or fatal |
info |
harborAdminPassword |
The initial password of the Harbor admin account. Change it from the portal after launching Harbor |
Harbor12345 |
secretKey |
The key used for encryption. Must be a string of 16 chars | "" |
| Expose | ||
expose.type |
How to expose the service: nodePort or loadBalancer, other values will be ignored and the creation of the service will be skipped. |
nodePort |
expose.tls.enabled |
Enable TLS or not. | true |
expose.tls.certSource |
The source of the TLS certificate. Set as auto, secret or none and fill the information in the corresponding section: 1) auto: generate the TLS certificate automatically 2) secret: read the TLS certificate from the specified secret. The TLS certificate can be generated manually or by cert manager 3) none: configure no TLS certificate. |
secret |
expose.tls.auto.commonName |
The common name used to generate the certificate. It’s necessary when expose.tls.certSource is set to auto |
|
expose.tls.secret.secretName |
The name of the secret which contains keys named: tls.crt - the certificate; tls.key - the private key |
harbor-tls-secret |
expose.nodePort.name |
The name of the NodePort service | harbor |
expose.nodePort.ports.http.port |
The service port Harbor listens on when serving HTTP | 80 |
expose.nodePort.ports.http.nodePort |
The node port Harbor listens on when serving HTTP | 30002 |
expose.nodePort.ports.https.port |
The service port Harbor listens on when serving HTTPS | 443 |
expose.nodePort.ports.https.nodePort |
The node port Harbor listens on when serving HTTPS | 30003 |
expose.loadBalancer.name |
The name of the service | harbor |
expose.loadBalancer.IP |
The IP address of the loadBalancer. It only works when loadBalancer supports assigning an IP address | "" |
expose.loadBalancer.ports.httpPort |
The service port Harbor listens on when serving HTTP | 80 |
expose.loadBalancer.ports.httpsPort |
The service port Harbor listens on when serving HTTPS | 30002 |
expose.loadBalancer.annotations |
The annotations attached to the loadBalancer service | {} |
expose.loadBalancer.sourceRanges |
List of IP address ranges to assign to loadBalancerSourceRanges | [] |
| Internal TLS | ||
internalTLS.enabled |
Enable TLS for the components (core, jobservice, portal, and registry) | true |
| Persistence | ||
persistence.resourcePolicy |
Setting it to keep to avoid removing PVCs during a helm delete operation. Leaving it empty will delete PVCs after the chart is deleted. Does not affect PVCs created for internal database and redis components. |
keep |
persistence.persistentVolumeClaim.registry.size |
The size of the volume | 5Gi |
persistence.persistentVolumeClaim.registry.storageClass |
Specify the storageClass used to provision the volume, or the default StorageClass will be used (the default). Set it to - to disable dynamic provisioning |
"" |
persistence.persistentVolumeClaim.jobservice.size |
The size of the volume | 1Gi |
persistence.persistentVolumeClaim.jobservice.storageClass |
Specify the storageClass used to provision the volume, or the default StorageClass will be used (the default). Set it to - to disable dynamic provisioning |
"" |
persistence.persistentVolumeClaim.database.size |
The size of the volume. If an external database is used, the setting will be ignored | 1Gi |
persistence.persistentVolumeClaim.database.storageClass |
Specify the storageClass used to provision the volume, or the default StorageClass will be used (the default). Set it to - to disable dynamic provisioning. If an external database is used, the setting will be ignored |
"" |
persistence.persistentVolumeClaim.redis.size |
The size of the volume. If an external Redis is used, the setting will be ignored | 1Gi |
persistence.persistentVolumeClaim.redis.storageClass |
Specify the storageClass used to provision the volume, or the default StorageClass will be used (the default). Set it to - to disable dynamic provisioning. If an external Redis is used, the setting will be ignored |
"" |
persistence.persistentVolumeClaim.trivy.size |
The size of the volume | 5Gi |
persistence.persistentVolumeClaim.trivy.storageClass |
Specify the storageClass used to provision the volume, or the default StorageClass will be used (the default). Set it to - to disable dynamic provisioning |
"" |
| Trivy | ||
trivy.enabled |
The flag to enable Trivy scanner | true |
trivy.vulnType |
Comma-separated list of vulnerability types. Possible values os and library. |
os,library |
trivy.severity |
Comma-separated list of severities to be checked | UNKNOWN,LOW,MEDIUM,HIGH,CRITICAL |
trivy.skipUpdate |
The flag to disable Trivy DB downloads from GitHub | false |
trivy.offlineScan |
The flag prevents Trivy from sending API requests to identify dependencies. | false |
| Registry | ||
registry.relativeurls |
If true, the registry returns relative URLs in Location headers. The client is responsible for resolving the correct URL. Needed if harbor is behind a reverse proxy | false |
7.7.3 - v2.7.1
Notary and Chartmuseum are not supported at this moment.
Configuring Harbor in EKS Anywhere package spec
The following table lists the configurable parameters of the Harbor package spec and the default values.
| Parameter | Description | Default |
|---|---|---|
| General | ||
externalURL |
The external URL for Harbor core service | https://127.0.0.1:30003 |
imagePullPolicy |
The image pull policy | IfNotPresent |
logLevel |
The log level: debug, info, warning, error or fatal |
info |
harborAdminPassword |
The initial password of the Harbor admin account. Change it from the portal after launching Harbor |
Harbor12345 |
secretKey |
The key used for encryption. Must be a string of 16 chars | "" |
| Expose | ||
expose.type |
How to expose the service: nodePort or loadBalancer, other values will be ignored and the creation of the service will be skipped. |
nodePort |
expose.tls.enabled |
Enable TLS or not. | true |
expose.tls.certSource |
The source of the TLS certificate. Set as auto, secret or none and fill the information in the corresponding section: 1) auto: generate the TLS certificate automatically 2) secret: read the TLS certificate from the specified secret. The TLS certificate can be generated manually or by cert manager 3) none: configure no TLS certificate. |
secret |
expose.tls.auto.commonName |
The common name used to generate the certificate. It’s necessary when expose.tls.certSource is set to auto |
|
expose.tls.secret.secretName |
The name of the secret which contains keys named: tls.crt - the certificate; tls.key - the private key |
harbor-tls-secret |
expose.nodePort.name |
The name of the NodePort service | harbor |
expose.nodePort.ports.http.port |
The service port Harbor listens on when serving HTTP | 80 |
expose.nodePort.ports.http.nodePort |
The node port Harbor listens on when serving HTTP | 30002 |
expose.nodePort.ports.https.port |
The service port Harbor listens on when serving HTTPS | 443 |
expose.nodePort.ports.https.nodePort |
The node port Harbor listens on when serving HTTPS | 30003 |
expose.loadBalancer.name |
The name of the service | harbor |
expose.loadBalancer.IP |
The IP address of the loadBalancer. It only works when loadBalancer supports assigning an IP address | "" |
expose.loadBalancer.ports.httpPort |
The service port Harbor listens on when serving HTTP | 80 |
expose.loadBalancer.ports.httpsPort |
The service port Harbor listens on when serving HTTPS | 30002 |
expose.loadBalancer.annotations |
The annotations attached to the loadBalancer service | {} |
expose.loadBalancer.sourceRanges |
List of IP address ranges to assign to loadBalancerSourceRanges | [] |
| Internal TLS | ||
internalTLS.enabled |
Enable TLS for the components (core, jobservice, portal, and registry) | true |
| Persistence | ||
persistence.resourcePolicy |
Setting it to keep to avoid removing PVCs during a helm delete operation. Leaving it empty will delete PVCs after the chart is deleted. Does not affect PVCs created for internal database and redis components. |
keep |
persistence.persistentVolumeClaim.registry.size |
The size of the volume | 5Gi |
persistence.persistentVolumeClaim.registry.storageClass |
Specify the storageClass used to provision the volume, or the default StorageClass will be used (the default). Set it to - to disable dynamic provisioning |
"" |
persistence.persistentVolumeClaim.jobservice.jobLog.size |
The size of the volume | 1Gi |
persistence.persistentVolumeClaim.jobservice.jobLog.storageClass |
Specify the storageClass used to provision the volume, or the default StorageClass will be used (the default). Set it to - to disable dynamic provisioning |
"" |
persistence.persistentVolumeClaim.database.size |
The size of the volume. If an external database is used, the setting will be ignored | 1Gi |
persistence.persistentVolumeClaim.database.storageClass |
Specify the storageClass used to provision the volume, or the default StorageClass will be used (the default). Set it to - to disable dynamic provisioning. If an external database is used, the setting will be ignored |
"" |
persistence.persistentVolumeClaim.redis.size |
The size of the volume. If an external Redis is used, the setting will be ignored | 1Gi |
persistence.persistentVolumeClaim.redis.storageClass |
Specify the storageClass used to provision the volume, or the default StorageClass will be used (the default). Set it to - to disable dynamic provisioning. If an external Redis is used, the setting will be ignored |
"" |
persistence.persistentVolumeClaim.trivy.size |
The size of the volume | 5Gi |
persistence.persistentVolumeClaim.trivy.storageClass |
Specify the storageClass used to provision the volume, or the default StorageClass will be used (the default). Set it to - to disable dynamic provisioning |
"" |
| Trivy | ||
trivy.enabled |
The flag to enable Trivy scanner | true |
trivy.vulnType |
Comma-separated list of vulnerability types. Possible values os and library. |
os,library |
trivy.severity |
Comma-separated list of severities to be checked | UNKNOWN,LOW,MEDIUM,HIGH,CRITICAL |
trivy.skipUpdate |
The flag to disable Trivy DB downloads from GitHub | false |
trivy.offlineScan |
The flag prevents Trivy from sending API requests to identify dependencies. | false |
| Registry | ||
registry.relativeurls |
If true, the registry returns relative URLs in Location headers. The client is responsible for resolving the correct URL. Needed if harbor is behind a reverse proxy | false |
7.8 - MetalLB Configuration
MetalLB is a load-balancer implementation for on-premises Kubernetes clusters, using standard routing protocols.
Best Practice
Any package configuration options listed under Reference/Packages should be modified through package yaml files (with kind: Package) through command eksctl anywhere apply package -f packageFileName. Modifying objects outside of package yaml files may lead to unpredictable behaviors.
For automatic namespace (targetNamespace) creation, see createNamespace field: PackagebundleController.spec
Configuration options for MetalLB
7.8.1 - v0.12.1
FRRouting is currently not supported for MetalLB.
Configuring MetalLB in EKS Anywhere package spec
Example
apiVersion: packages.eks.amazonaws.com/v1alpha1
kind: Package
metadata:
name: mylb
namespace: eksa-packages-<cluster-name>
spec:
packageName: metallb
targetNamespace: metallb-system
config: |
IPAddressPools:
- name: default
addresses:
- 10.220.0.93/32
- 10.220.0.94/32
- 10.220.0.95/32
- name: bgp
addresses:
- 10.220.0.97-10.220.0.99
L2Advertisements:
- IPAddressPools:
- default
BGPAdvertisements:
- IPAddressPools:
- bgp
BGPPeers:
- myASN: 123
peerASN: 55001
peerAddress: 1.2.3.4
keepaliveTime: 30s
| Parameter | Description | Default |
|---|---|---|
| IPAddressPools[] | A list of IPAddressPool. | None |
| L2Advertisements[] | A list of L2Advertisement. | None |
| BGPAdvertisements[] | A list of BGPAdvertisement. | None |
| BGPPeers[] | A list of BGPPeer. | None |
| — | — | — |
| IPAddressPool | A list of IP address ranges over which MetalLB has authority. You can list multiple ranges in a single pool and they will all share the same settings. Each range can be either a CIDR prefix, or an explicit start-end range of IPs. | |
| name | Name for the address pool. | None |
| addresses[] | A list of string representing CIRD or IP ranges. | None |
| autoAssign | AutoAssign flag used to prevent MetalLB from automatic allocation for a pool. | true |
| — | — | — |
| L2Advertisement | L2Advertisement allows MetalLB to advertise the LoadBalancer IPs provided by the selected pools via L2. | |
| IPAddressPools[] | The list of IPAddressPools to advertise via this advertisement, selected by name. | None |
| — | — | — |
| BGPAdvertisement | BGPAdvertisement allows MetalLB to advertise the IPs coming from the selected IPAddressPools via BGP, setting the parameters of the BGP Advertisement. | |
| aggregationLength | The aggregation-length advertisement option lets you “roll up” the /32s into a larger prefix. Defaults to 32. Works for IPv4 addresses. | 32 |
| aggregationLengthV6 | The aggregation-length advertisement option lets you “roll up” the /128s into a larger prefix. Defaults to 128. Works for IPv6 addresses. | 128 |
| communities[] | The BGP communities to be associated with the announcement. Each item can be a community of the form 1234:1234 or the name of an alias defined in the Community CRD. | None |
| IPAddressPools[] | The list of IPAddressPools to advertise via this advertisement, selected by name. | None |
| localPref | The BGP LOCAL_PREF attribute which is used by BGP best path algorithm, Path with higher localpref is preferred over one with lower localpref. | None |
| — | — | — |
| BGPPeer | Peers for the BGP protocol. | |
| bfdProfile | The name of the BFD Profile to be used for the BFD session associated to the BGP session. If not set, the BFD session won’t be set up. | None |
| holdTime | Requested BGP hold time, per RFC4271. | None |
| keepaliveTime | Requested BGP keepalive time, per RFC4271. | None |
| myASN | AS number to use for the local end of the session. | None |
| password | Authentication password for routers enforcing TCP MD5 authenticated sessions. | None |
| peerASN | AS number to expect from the remote end of the session. | None |
| peerAddress | Address to dial when establishing the session. | None |
| peerPort | Port to dial when establishing the session. | 179 |
| routerID | BGP router ID to advertise to the peer. | None |
| sourceAddress | Source address to use when establishing the session. | None |
7.8.2 - v0.13.5
FRRouting is currently not supported for MetalLB.
Configuring MetalLB in EKS Anywhere package spec
Starting at v0.13.5, keys within each config section start with lowercase. For example:
L2Advertisements:
- IPAddressPools:
- default
Becomes:
L2Advertisements:
- ipAddressPools:
- default
Top-level section names remain capitalized as they represent CRDs:
config: |
IPAddressPools:
...
Example
apiVersion: packages.eks.amazonaws.com/v1alpha1
kind: Package
metadata:
name: mylb
namespace: eksa-packages-<cluster-name>
spec:
packageName: metallb
targetNamespace: metallb-system
config: |
IPAddressPools:
- name: default
addresses:
- 10.220.0.93/32
- 10.220.0.94/32
- 10.220.0.95/32
- name: bgp
addresses:
- 10.220.0.97-10.220.0.99
L2Advertisements:
- ipAddressPools:
- default
BGPAdvertisements:
- ipAddressPools:
- bgp
autoAssign: false
BGPPeers:
- myASN: 123
peerASN: 55001
peerAddress: 1.2.3.4
keepaliveTime: 30s
| Parameter | Description | Default | Required |
|---|---|---|---|
| IPAddressPools[] | A list of ip address pools. See IPAddressPool. | None | False |
| L2Advertisements[] | A list of Layer 2 advertisements. See L2Advertisement. | None | False |
| BGPAdvertisements[] | A list of BGP advertisements. See BGPAdvertisement. | None | False |
| BGPPeers[] | A list of BGP peers. See BGPPeer. | None | False |
| — | — | — | — |
| IPAddressPool | A list of IP address ranges over which MetalLB has authority. You can list multiple ranges in a single pool and they will all share the same settings. Each range can be either a CIDR prefix, or an explicit start-end range of IPs. | ||
| name | Name for the address pool. | None | True |
| addresses[] | A list of string representing CIRD or IP ranges. | None | True |
| autoAssign | AutoAssign flag used to prevent MetalLB from automatic allocation for a pool. | true | False |
| — | — | — | — |
| L2Advertisement | L2Advertisement allows MetalLB to advertise the LoadBalancer IPs provided by the selected pools via L2. | ||
| ipAddressPools[] | The list of IPAddressPool names to advertise. | None | True |
| name | Name for the L2Advertisement. | None | False |
| — | — | — | — |
| BGPAdvertisement | BGPAdvertisement allows MetalLB to advertise the IPs coming from the selected ipAddressPools via BGP, setting the parameters of the BGP Advertisement. | ||
| aggregationLength | The aggregation-length advertisement option lets you “roll up” the /32s into a larger prefix. Defaults to 32. Works for IPv4 addresses. | 32 | False |
| aggregationLengthV6 | The aggregation-length advertisement option lets you “roll up” the /128s into a larger prefix. Defaults to 128. Works for IPv6 addresses. | 128 | False |
| communities[] | The BGP communities to be associated with the announcement. Each item can be a community of the form 1234:1234 or the name of an alias defined in the Community CRD. | None | False |
| ipAddressPools[] | The list of IPAddressPool names to be advertised via BGP. | None | True |
| localPref | The BGP LOCAL_PREF attribute which is used by BGP best path algorithm, Path with higher localpref is preferred over one with lower localpref. | None | False |
| peers[] | List of peer names. Limits the bgppeer to advertise the ips of the selected pools to. When empty, the loadbalancer IP is announced to all the BGPPeers configured. | None | False |
| — | — | — | — |
| BGPPeer | Peers for the BGP protocol. | ||
| holdTime | Requested BGP hold time, per RFC4271. | None | False |
| keepaliveTime | Requested BGP keepalive time, per RFC4271. | None | False |
| myASN | AS number to use for the local end of the session. | None | True |
| password | Authentication password for routers enforcing TCP MD5 authenticated sessions. | None | False |
| peerASN | AS number to expect from the remote end of the session. | None | True |
| peerAddress | Address to dial when establishing the session. | None | True |
| peerPort | Port to dial when establishing the session. | 179 | False |
| routerID | BGP router ID to advertise to the peer. | None | False |
| sourceAddress | Source address to use when establishing the session. | None | False |
7.8.3 - v0.13.7
FRRouting is currently not supported for MetalLB.
Configuring MetalLB in EKS Anywhere package spec
Starting at v0.13.5, keys within each config section start with lowercase. See v0.13.5 for details.
Example
apiVersion: packages.eks.amazonaws.com/v1alpha1
kind: Package
metadata:
name: mylb
namespace: eksa-packages-<cluster-name>
spec:
packageName: metallb
targetNamespace: metallb-system
config: |
IPAddressPools:
- name: default
addresses:
- 10.220.0.93/32
- 10.220.0.94/32
- 10.220.0.95/32
- name: bgp
addresses:
- 10.220.0.97-10.220.0.99
L2Advertisements:
- ipAddressPools:
- default
BGPAdvertisements:
- ipAddressPools:
- bgp
autoAssign: false
BGPPeers:
- myASN: 123
peerASN: 55001
peerAddress: 1.2.3.4
keepaliveTime: 30s
| Parameter | Description | Default | Required |
|---|---|---|---|
| IPAddressPools[] | A list of ip address pools. See IPAddressPool. | None | False |
| L2Advertisements[] | A list of Layer 2 advertisements. See L2Advertisement. | None | False |
| BGPAdvertisements[] | A list of BGP advertisements. See BGPAdvertisement. | None | False |
| BGPPeers[] | A list of BGP peers. See BGPPeer. | None | False |
| — | — | — | — |
| IPAddressPool | A list of IP address ranges over which MetalLB has authority. You can list multiple ranges in a single pool and they will all share the same settings. Each range can be either a CIDR prefix, or an explicit start-end range of IPs. | ||
| name | Name for the address pool. | None | True |
| addresses[] | A list of string representing CIRD or IP ranges. | None | True |
| autoAssign | AutoAssign flag used to prevent MetalLB from automatic allocation for a pool. | true | False |
| — | — | — | — |
| L2Advertisement | L2Advertisement allows MetalLB to advertise the LoadBalancer IPs provided by the selected pools via L2. | ||
| ipAddressPools[] | The list of IPAddressPool names to advertise. | None | True |
| name | Name for the L2Advertisement. | None | False |
| — | — | — | — |
| BGPAdvertisement | BGPAdvertisement allows MetalLB to advertise the IPs coming from the selected ipAddressPools via BGP, setting the parameters of the BGP Advertisement. | ||
| aggregationLength | The aggregation-length advertisement option lets you “roll up” the /32s into a larger prefix. Defaults to 32. Works for IPv4 addresses. | 32 | False |
| aggregationLengthV6 | The aggregation-length advertisement option lets you “roll up” the /128s into a larger prefix. Defaults to 128. Works for IPv6 addresses. | 128 | False |
| communities[] | The BGP communities to be associated with the announcement. Each item can be a community of the form 1234:1234 or the name of an alias defined in the Community CRD. | None | False |
| ipAddressPools[] | The list of IPAddressPool names to be advertised via BGP. | None | True |
| localPref | The BGP LOCAL_PREF attribute which is used by BGP best path algorithm, Path with higher localpref is preferred over one with lower localpref. | None | False |
| peers[] | List of peer names. Limits the bgppeer to advertise the ips of the selected pools to. When empty, the loadbalancer IP is announced to all the BGPPeers configured. | None | False |
| — | — | — | — |
| BGPPeer | Peers for the BGP protocol. | ||
| holdTime | Requested BGP hold time, per RFC4271. | None | False |
| keepaliveTime | Requested BGP keepalive time, per RFC4271. | None | False |
| myASN | AS number to use for the local end of the session. | None | True |
| password | Authentication password for routers enforcing TCP MD5 authenticated sessions. | None | False |
| peerASN | AS number to expect from the remote end of the session. | None | True |
| peerAddress | Address to dial when establishing the session. | None | True |
| peerPort | Port to dial when establishing the session. | 179 | False |
| routerID | BGP router ID to advertise to the peer. | None | False |
| sourceAddress | Source address to use when establishing the session. | None | False |
| password | Authentication password for routers enforcing TCP MD5 authenticated sessions. | None | False |
| passwordSecret | passwordSecret is a reference to the authentication secret for BGP Peer. The secret must be of type ‘kubernetes.io/basic-auth’ and the password stored under the “password” key. Example: passwordSecret: |
None | False |
7.9 - Metrics Server Configuration
Metrics Server is a scalable, efficient source of container resource metrics for Kubernetes built-in autoscaling pipelines.
Configuration options for Metrics Server
7.9.1 - v3.8.2
Configuring Metrics Server in EKS Anywhere package spec
| Parameter | Description | Default |
|---|---|---|
| General | ||
| args | Additional args to provide to metrics-server Example: cloudProvider: ["–kubelet-insecure-tls"] |
[] |
7.10 - Prometheus Configuration
Prometheus is an open-source systems monitoring and alerting toolkit. It collects and stores metrics as time series data.
Best Practice
Any package configuration options listed under Reference/Packages should be modified through package yaml files (with kind: Package) through command eksctl anywhere apply package -f packageFileName. Modifying objects outside of package yaml files may lead to unpredictable behaviors.
For automatic namespace (targetNamespace) creation, see createNamespace field: PackagebundleController.spec
Configuration options for Prometheus
7.10.1 - v2.39.1
Configuring Prometheus in EKS Anywhere package spec
Example
apiVersion: packages.eks.amazonaws.com/v1alpha1
kind: Package
metadata:
name: generated-prometheus
namespace: eksa-packages-<cluster-name>
spec:
packageName: prometheus
targetNamespace: observability
config: |
server:
replicaCount: 2
statefulSet:
enabled: true
Configurable parameters and default values under spec.config
| Parameter | Description | Default |
|---|---|---|
| General | ||
| rbac.create | Specifies if clusterRole / role and clusterRoleBinding / roleBinding will be created for prometheus-server and node-exporter | true |
| sourceRegistry | Specifies image source registry for prometheus-server and node-exporter | "783794618700.dkr.ecr.us-west-2.amazonaws.com" |
| Node-Exporter | ||
| nodeExporter.enabled | Indicates if node-exporter is enabled | true |
| nodeExporter.hostNetwork | Indicates if node-exporter shares the host network namespace | true |
| nodeExporter.hostPID | Indicates if node-exporter shares the host process ID namespace | true |
| nodeExporter.image.pullPolicy | Specifies node-exporter image pull policy: IfNotPresent, Always, Never |
"IfNotPresent" |
| nodeExporter.image.repository | Specifies node-exporter image repository | "prometheus/node-exporter" |
| nodeExporter.resources | Specifies resource requests and limits of the node-exporter container. Refer to the Kubernetes API documentation ResourceRequirements field for more details | {} |
| nodeExporter.service | Specifies how to expose node-exporter as a network service | See footnote 1 |
| nodeExporter.tolerations | Specifies node tolerations for node-exporter scheduling to nodes with taints. Refer to the Kubernetes API documentation toleration field for more details. | See footnote 2 |
| serviceAccounts.nodeExporter.annotations | Specifies node-exporter service account annotations | {} |
| serviceAccounts.nodeExporter.create | Indicates if node-exporter service account will be created | true |
| serviceAccounts.nodeExporter.name | Specifies node-exporter service account name | "" |
| Prometheus-Server | ||
| server.enabled | Indicates if prometheus-server is enabled | true |
| server.global.evaluation_interval | Specifies how frequently the prometheus-server rules are evaluated | "1m" |
| server.global.scrape_interval | Specifies how frequently prometheus-server will scrape targets | "1m" |
| server.global.scrape_timeout | Specifies how long until a prometheus-server scrape request times out | "10s" |
| server.image.pullPolicy | Specifies prometheus-server image pull policy: IfNotPresent, Always, Never |
"IfNotPresent" |
| server.image.repository | Specifies prometheus-server image repository | "prometheus/prometheus" |
| server.name | Specifies prometheus-server container name | "server" |
| server.persistentVolume.accessModes | Specifies prometheus-server data Persistent Volume access modes | "ReadWriteOnce" |
| server.persistentVolume.enabled | Indicates if prometheus-server will create/use a Persistent Volume Claim | true |
| server.persistentVolume.existingClaim | Specifies prometheus-server data Persistent Volume existing claim name. It requires server.persistentVolume.enabled: true. If defined, PVC must be created manually before volume will be bound |
"" |
| server.persistentVolume.size | Specifies prometheus-server data Persistent Volume size | "8Gi" |
| server.remoteRead | Specifies prometheus-server remote read configs. Refer to Prometheus docs remote_read for more details | [] |
| server.remoteWrite | Specifies prometheus-server remote write configs. Refer to Prometheus docs remote_write for more details | [] |
| server.replicaCount | Specifies the replicaCount for prometheus-server deployment / statefulSet. Note: server.statefulSet.enabled should be set to true if server.replicaCount is greater than 1 |
1 |
| server.resources | Specifies resource requests and limits of the prometheus-server container. Refer to the Kubernetes API documentation ResourceRequirements field for more details | {} |
| server.retention | Specifies prometheus-server data retention period | "15d" |
| server.service | Specifies how to expose prometheus-server as a network service | See footnote 3 |
| server.statefulSet.enabled | Indicates if prometheus-server is deployed as a statefulSet. If set to false, prometheus-server will be deployed as a deployment |
false |
| serverFiles.“prometheus.yml”.scrape_configs | Specifies a set of targets and parameters for prometheus-server describing how to scrape them. Refer to Prometheus docs scrape_config for more details | See footnote 4 |
| serviceAccounts.server.annotations | Specifies prometheus-server service account annotations | {} |
| serviceAccounts.server.create | Indicates if prometheus-server service account will be created | true |
| serviceAccounts.server.name | Specifies prometheus-server service account name | "" |
-
Node-exporter service is exposed as a
clusterIPwithport: 9100(controlled bynodeExporter.service.servicePortbelow) andtargetPort: 9100(controlled bynodeExporter.service.hostPortbelow) by default. Note the annotationprometheus.io/scrape: "true"is mandatory in order for node-exporter to be discovered by prometheus-server as a scrape target. See below specification for details.↩︎apiVersion: packages.eks.amazonaws.com/v1alpha1 kind: Package ... spec: config: | nodeExporter: service: annotations: prometheus.io/scrape: "true" hostPort: 9100 servicePort: 9100 type: ClusterIP -
Node-exporter pods have the following toleration by default, which allows daemonSet to be scheduled on control plane node.
↩︎apiVersion: packages.eks.amazonaws.com/v1alpha1 kind: Package ... spec: config: | nodeExporter: tolerations: # For K8 version prior to 1.24 - key: "node-role.kubernetes.io/master" operator: "Exists" effect: "NoSchedule" # For K8 version 1.24+ - key: "node-role.kubernetes.io/control-plane" operator: "Exists" effect: "NoSchedule" -
Prometheus-server service is exposed as a
clusterIPwithport: 9090(controlled byserver.service.servicePortbelow) andtargetPort: 9090(not overridable) by default. See below specification for details.↩︎apiVersion: packages.eks.amazonaws.com/v1alpha1 kind: Package ... spec: config: | server: service: enabled: true servicePort: 9090 type: ClusterIP -
Prometheus-server by default has the following scrape configs.
↩︎apiVersion: packages.eks.amazonaws.com/v1alpha1 kind: Package ... spec: config: | serverFiles: prometheus.yml: scrape_configs: - job_name: prometheus honor_timestamps: true scrape_interval: 1m scrape_timeout: 10s metrics_path: /metrics scheme: http follow_redirects: true enable_http2: true static_configs: - targets: - localhost:9090 - job_name: kubernetes-apiservers honor_timestamps: true scrape_interval: 1m scrape_timeout: 10s metrics_path: /metrics scheme: https authorization: type: Bearer credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: false follow_redirects: true enable_http2: true relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] separator: ; regex: default;kubernetes;https replacement: $1 action: keep kubernetes_sd_configs: - role: endpoints kubeconfig_file: "" follow_redirects: true enable_http2: true - job_name: kubernetes-nodes honor_timestamps: true scrape_interval: 1m scrape_timeout: 10s metrics_path: /metrics scheme: https authorization: type: Bearer credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: false follow_redirects: true enable_http2: true relabel_configs: - separator: ; regex: __meta_kubernetes_node_label_(.+) replacement: $1 action: labelmap - separator: ; regex: (.*) target_label: __address__ replacement: kubernetes.default.svc:443 action: replace - source_labels: [__meta_kubernetes_node_name] separator: ; regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/$1/proxy/metrics action: replace kubernetes_sd_configs: - role: node kubeconfig_file: "" follow_redirects: true enable_http2: true - job_name: kubernetes-nodes-cadvisor honor_timestamps: true scrape_interval: 1m scrape_timeout: 10s metrics_path: /metrics scheme: https authorization: type: Bearer credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: false follow_redirects: true enable_http2: true relabel_configs: - separator: ; regex: __meta_kubernetes_node_label_(.+) replacement: $1 action: labelmap - separator: ; regex: (.*) target_label: __address__ replacement: kubernetes.default.svc:443 action: replace - source_labels: [__meta_kubernetes_node_name] separator: ; regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/$1/proxy/metrics/cadvisor action: replace kubernetes_sd_configs: - role: node kubeconfig_file: "" follow_redirects: true enable_http2: true - job_name: kubernetes-service-endpoints honor_labels: true honor_timestamps: true scrape_interval: 1m scrape_timeout: 10s metrics_path: /metrics scheme: http follow_redirects: true enable_http2: true relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] separator: ; regex: "true" replacement: $1 action: keep - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape_slow] separator: ; regex: "true" replacement: $1 action: drop - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] separator: ; regex: (https?) target_label: __scheme__ replacement: $1 action: replace - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] separator: ; regex: (.+) target_label: __metrics_path__ replacement: $1 action: replace - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] separator: ; regex: (.+?)(?::\d+)?;(\d+) target_label: __address__ replacement: $1:$2 action: replace - separator: ; regex: __meta_kubernetes_service_annotation_prometheus_io_param_(.+) replacement: __param_$1 action: labelmap - separator: ; regex: __meta_kubernetes_service_label_(.+) replacement: $1 action: labelmap - source_labels: [__meta_kubernetes_namespace] separator: ; regex: (.*) target_label: namespace replacement: $1 action: replace - source_labels: [__meta_kubernetes_service_name] separator: ; regex: (.*) target_label: service replacement: $1 action: replace - source_labels: [__meta_kubernetes_pod_node_name] separator: ; regex: (.*) target_label: node replacement: $1 action: replace kubernetes_sd_configs: - role: endpoints kubeconfig_file: "" follow_redirects: true enable_http2: true - job_name: kubernetes-service-endpoints-slow honor_labels: true honor_timestamps: true scrape_interval: 5m scrape_timeout: 30s metrics_path: /metrics scheme: http follow_redirects: true enable_http2: true relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape_slow] separator: ; regex: "true" replacement: $1 action: keep - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] separator: ; regex: (https?) target_label: __scheme__ replacement: $1 action: replace - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] separator: ; regex: (.+) target_label: __metrics_path__ replacement: $1 action: replace - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] separator: ; regex: (.+?)(?::\d+)?;(\d+) target_label: __address__ replacement: $1:$2 action: replace - separator: ; regex: __meta_kubernetes_service_annotation_prometheus_io_param_(.+) replacement: __param_$1 action: labelmap - separator: ; regex: __meta_kubernetes_service_label_(.+) replacement: $1 action: labelmap - source_labels: [__meta_kubernetes_namespace] separator: ; regex: (.*) target_label: namespace replacement: $1 action: replace - source_labels: [__meta_kubernetes_service_name] separator: ; regex: (.*) target_label: service replacement: $1 action: replace - source_labels: [__meta_kubernetes_pod_node_name] separator: ; regex: (.*) target_label: node replacement: $1 action: replace kubernetes_sd_configs: - role: endpoints kubeconfig_file: "" follow_redirects: true enable_http2: true - job_name: prometheus-pushgateway honor_labels: true honor_timestamps: true scrape_interval: 1m scrape_timeout: 10s metrics_path: /metrics scheme: http follow_redirects: true enable_http2: true relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_probe] separator: ; regex: pushgateway replacement: $1 action: keep kubernetes_sd_configs: - role: service kubeconfig_file: "" follow_redirects: true enable_http2: true - job_name: kubernetes-services honor_labels: true honor_timestamps: true params: module: - http_2xx scrape_interval: 1m scrape_timeout: 10s metrics_path: /probe scheme: http follow_redirects: true enable_http2: true relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_probe] separator: ; regex: "true" replacement: $1 action: keep - source_labels: [__address__] separator: ; regex: (.*) target_label: __param_target replacement: $1 action: replace - separator: ; regex: (.*) target_label: __address__ replacement: blackbox action: replace - source_labels: [__param_target] separator: ; regex: (.*) target_label: instance replacement: $1 action: replace - separator: ; regex: __meta_kubernetes_service_label_(.+) replacement: $1 action: labelmap - source_labels: [__meta_kubernetes_namespace] separator: ; regex: (.*) target_label: namespace replacement: $1 action: replace - source_labels: [__meta_kubernetes_service_name] separator: ; regex: (.*) target_label: service replacement: $1 action: replace kubernetes_sd_configs: - role: service kubeconfig_file: "" follow_redirects: true enable_http2: true - job_name: kubernetes-pods honor_labels: true honor_timestamps: true scrape_interval: 1m scrape_timeout: 10s metrics_path: /metrics scheme: http follow_redirects: true enable_http2: true relabel_configs: - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape] separator: ; regex: "true" replacement: $1 action: keep - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape_slow] separator: ; regex: "true" replacement: $1 action: drop - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scheme] separator: ; regex: (https?) target_label: __scheme__ replacement: $1 action: replace - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path] separator: ; regex: (.+) target_label: __metrics_path__ replacement: $1 action: replace - source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] separator: ; regex: (.+?)(?::\d+)?;(\d+) target_label: __address__ replacement: $1:$2 action: replace - separator: ; regex: __meta_kubernetes_pod_annotation_prometheus_io_param_(.+) replacement: __param_$1 action: labelmap - separator: ; regex: __meta_kubernetes_pod_label_(.+) replacement: $1 action: labelmap - source_labels: [__meta_kubernetes_namespace] separator: ; regex: (.*) target_label: namespace replacement: $1 action: replace - source_labels: [__meta_kubernetes_pod_name] separator: ; regex: (.*) target_label: pod replacement: $1 action: replace - source_labels: [__meta_kubernetes_pod_phase] separator: ; regex: Pending|Succeeded|Failed|Completed replacement: $1 action: drop kubernetes_sd_configs: - role: pod kubeconfig_file: "" follow_redirects: true enable_http2: true - job_name: kubernetes-pods-slow honor_labels: true honor_timestamps: true scrape_interval: 5m scrape_timeout: 30s metrics_path: /metrics scheme: http follow_redirects: true enable_http2: true relabel_configs: - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape_slow] separator: ; regex: "true" replacement: $1 action: keep - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scheme] separator: ; regex: (https?) target_label: __scheme__ replacement: $1 action: replace - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path] separator: ; regex: (.+) target_label: __metrics_path__ replacement: $1 action: replace - source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] separator: ; regex: (.+?)(?::\d+)?;(\d+) target_label: __address__ replacement: $1:$2 action: replace - separator: ; regex: __meta_kubernetes_pod_annotation_prometheus_io_param_(.+) replacement: __param_$1 action: labelmap - separator: ; regex: __meta_kubernetes_pod_label_(.+) replacement: $1 action: labelmap - source_labels: [__meta_kubernetes_namespace] separator: ; regex: (.*) target_label: namespace replacement: $1 action: replace - source_labels: [__meta_kubernetes_pod_name] separator: ; regex: (.*) target_label: pod replacement: $1 action: replace - source_labels: [__meta_kubernetes_pod_phase] separator: ; regex: Pending|Succeeded|Failed|Completed replacement: $1 action: drop kubernetes_sd_configs: - role: pod kubeconfig_file: "" follow_redirects: true enable_http2: true
7.10.2 - v2.41.1
Configuring Prometheus in EKS Anywhere package spec
Example
apiVersion: packages.eks.amazonaws.com/v1alpha1
kind: Package
metadata:
name: generated-prometheus
namespace: eksa-packages-<cluster-name>
spec:
packageName: prometheus
targetNamespace: observability
config: |
server:
replicaCount: 2
statefulSet:
enabled: true
Configurable parameters and default values under spec.config
| Parameter | Description | Default |
|---|---|---|
| General | ||
| rbac.create | Specifies if clusterRole / role and clusterRoleBinding / roleBinding will be created for prometheus-server and node-exporter | true |
| sourceRegistry | Specifies image source registry for prometheus-server and node-exporter | "783794618700.dkr.ecr.us-west-2.amazonaws.com" |
| Node-Exporter | ||
| nodeExporter.enabled | Indicates if node-exporter is enabled | true |
| nodeExporter.hostNetwork | Indicates if node-exporter shares the host network namespace | true |
| nodeExporter.hostPID | Indicates if node-exporter shares the host process ID namespace | true |
| nodeExporter.image.pullPolicy | Specifies node-exporter image pull policy: IfNotPresent, Always, Never |
"IfNotPresent" |
| nodeExporter.image.repository | Specifies node-exporter image repository | "prometheus/node-exporter" |
| nodeExporter.resources | Specifies resource requests and limits of the node-exporter container. Refer to the Kubernetes API documentation ResourceRequirements field for more details | {} |
| nodeExporter.service | Specifies how to expose node-exporter as a network service | See footnote 1 |
| nodeExporter.tolerations | Specifies node tolerations for node-exporter scheduling to nodes with taints. Refer to the Kubernetes API documentation toleration field for more details. | See footnote 2 |
| serviceAccounts.nodeExporter.annotations | Specifies node-exporter service account annotations | {} |
| serviceAccounts.nodeExporter.create | Indicates if node-exporter service account will be created | true |
| serviceAccounts.nodeExporter.name | Specifies node-exporter service account name | "" |
| Prometheus-Server | ||
| server.enabled | Indicates if prometheus-server is enabled | true |
| server.global.evaluation_interval | Specifies how frequently the prometheus-server rules are evaluated | "1m" |
| server.global.scrape_interval | Specifies how frequently prometheus-server will scrape targets | "1m" |
| server.global.scrape_timeout | Specifies how long until a prometheus-server scrape request times out | "10s" |
| server.image.pullPolicy | Specifies prometheus-server image pull policy: IfNotPresent, Always, Never |
"IfNotPresent" |
| server.image.repository | Specifies prometheus-server image repository | "prometheus/prometheus" |
| server.name | Specifies prometheus-server container name | "server" |
| server.persistentVolume.accessModes | Specifies prometheus-server data Persistent Volume access modes | "ReadWriteOnce" |
| server.persistentVolume.enabled | Indicates if prometheus-server will create/use a Persistent Volume Claim | true |
| server.persistentVolume.existingClaim | Specifies prometheus-server data Persistent Volume existing claim name. It requires server.persistentVolume.enabled: true. If defined, PVC must be created manually before volume will be bound |
"" |
| server.persistentVolume.size | Specifies prometheus-server data Persistent Volume size | "8Gi" |
| server.remoteRead | Specifies prometheus-server remote read configs. Refer to Prometheus docs remote_read for more details | [] |
| server.remoteWrite | Specifies prometheus-server remote write configs. Refer to Prometheus docs remote_write for more details | [] |
| server.replicaCount | Specifies the replicaCount for prometheus-server deployment / statefulSet. Note: server.statefulSet.enabled should be set to true if server.replicaCount is greater than 1 |
1 |
| server.resources | Specifies resource requests and limits of the prometheus-server container. Refer to the Kubernetes API documentation ResourceRequirements field for more details | {} |
| server.retention | Specifies prometheus-server data retention period | "15d" |
| server.service | Specifies how to expose prometheus-server as a network service | See footnote 3 |
| server.statefulSet.enabled | Indicates if prometheus-server is deployed as a statefulSet. If set to false, prometheus-server will be deployed as a deployment |
false |
| serverFiles.“prometheus.yml”.scrape_configs | Specifies a set of targets and parameters for prometheus-server describing how to scrape them. Refer to Prometheus docs scrape_config for more details | See footnote 4 |
| serviceAccounts.server.annotations | Specifies prometheus-server service account annotations | {} |
| serviceAccounts.server.create | Indicates if prometheus-server service account will be created | true |
| serviceAccounts.server.name | Specifies prometheus-server service account name | "" |
-
Node-exporter service is exposed as a
clusterIPwithport: 9100(controlled bynodeExporter.service.servicePortbelow) andtargetPort: 9100(controlled bynodeExporter.service.hostPortbelow) by default. Note the annotationprometheus.io/scrape: "true"is mandatory in order for node-exporter to be discovered by prometheus-server as a scrape target. See below specification for details.↩︎apiVersion: packages.eks.amazonaws.com/v1alpha1 kind: Package ... spec: config: | nodeExporter: service: annotations: prometheus.io/scrape: "true" hostPort: 9100 servicePort: 9100 type: ClusterIP -
Node-exporter pods have the following toleration by default, which allows daemonSet to be scheduled on control plane node.
↩︎apiVersion: packages.eks.amazonaws.com/v1alpha1 kind: Package ... spec: config: | nodeExporter: tolerations: # For K8 version prior to 1.24 - key: "node-role.kubernetes.io/master" operator: "Exists" effect: "NoSchedule" # For K8 version 1.24+ - key: "node-role.kubernetes.io/control-plane" operator: "Exists" effect: "NoSchedule" -
Prometheus-server service is exposed as a
clusterIPwithport: 9090(controlled byserver.service.servicePortbelow) andtargetPort: 9090(not overridable) by default. See below specification for details.↩︎apiVersion: packages.eks.amazonaws.com/v1alpha1 kind: Package ... spec: config: | server: service: enabled: true servicePort: 9090 type: ClusterIP -
Prometheus-server by default has the following scrape configs.
↩︎apiVersion: packages.eks.amazonaws.com/v1alpha1 kind: Package ... spec: config: | serverFiles: prometheus.yml: scrape_configs: - job_name: prometheus honor_timestamps: true scrape_interval: 1m scrape_timeout: 10s metrics_path: /metrics scheme: http follow_redirects: true enable_http2: true static_configs: - targets: - localhost:9090 - job_name: kubernetes-apiservers honor_timestamps: true scrape_interval: 1m scrape_timeout: 10s metrics_path: /metrics scheme: https authorization: type: Bearer credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: false follow_redirects: true enable_http2: true relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] separator: ; regex: default;kubernetes;https replacement: $1 action: keep kubernetes_sd_configs: - role: endpoints kubeconfig_file: "" follow_redirects: true enable_http2: true - job_name: kubernetes-nodes honor_timestamps: true scrape_interval: 1m scrape_timeout: 10s metrics_path: /metrics scheme: https authorization: type: Bearer credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: false follow_redirects: true enable_http2: true relabel_configs: - separator: ; regex: __meta_kubernetes_node_label_(.+) replacement: $1 action: labelmap - separator: ; regex: (.*) target_label: __address__ replacement: kubernetes.default.svc:443 action: replace - source_labels: [__meta_kubernetes_node_name] separator: ; regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/$1/proxy/metrics action: replace kubernetes_sd_configs: - role: node kubeconfig_file: "" follow_redirects: true enable_http2: true - job_name: kubernetes-nodes-cadvisor honor_timestamps: true scrape_interval: 1m scrape_timeout: 10s metrics_path: /metrics scheme: https authorization: type: Bearer credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: false follow_redirects: true enable_http2: true relabel_configs: - separator: ; regex: __meta_kubernetes_node_label_(.+) replacement: $1 action: labelmap - separator: ; regex: (.*) target_label: __address__ replacement: kubernetes.default.svc:443 action: replace - source_labels: [__meta_kubernetes_node_name] separator: ; regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/$1/proxy/metrics/cadvisor action: replace kubernetes_sd_configs: - role: node kubeconfig_file: "" follow_redirects: true enable_http2: true - job_name: kubernetes-service-endpoints honor_labels: true honor_timestamps: true scrape_interval: 1m scrape_timeout: 10s metrics_path: /metrics scheme: http follow_redirects: true enable_http2: true relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] separator: ; regex: "true" replacement: $1 action: keep - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape_slow] separator: ; regex: "true" replacement: $1 action: drop - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] separator: ; regex: (https?) target_label: __scheme__ replacement: $1 action: replace - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] separator: ; regex: (.+) target_label: __metrics_path__ replacement: $1 action: replace - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] separator: ; regex: (.+?)(?::\d+)?;(\d+) target_label: __address__ replacement: $1:$2 action: replace - separator: ; regex: __meta_kubernetes_service_annotation_prometheus_io_param_(.+) replacement: __param_$1 action: labelmap - separator: ; regex: __meta_kubernetes_service_label_(.+) replacement: $1 action: labelmap - source_labels: [__meta_kubernetes_namespace] separator: ; regex: (.*) target_label: namespace replacement: $1 action: replace - source_labels: [__meta_kubernetes_service_name] separator: ; regex: (.*) target_label: service replacement: $1 action: replace - source_labels: [__meta_kubernetes_pod_node_name] separator: ; regex: (.*) target_label: node replacement: $1 action: replace kubernetes_sd_configs: - role: endpoints kubeconfig_file: "" follow_redirects: true enable_http2: true - job_name: kubernetes-service-endpoints-slow honor_labels: true honor_timestamps: true scrape_interval: 5m scrape_timeout: 30s metrics_path: /metrics scheme: http follow_redirects: true enable_http2: true relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape_slow] separator: ; regex: "true" replacement: $1 action: keep - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] separator: ; regex: (https?) target_label: __scheme__ replacement: $1 action: replace - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] separator: ; regex: (.+) target_label: __metrics_path__ replacement: $1 action: replace - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] separator: ; regex: (.+?)(?::\d+)?;(\d+) target_label: __address__ replacement: $1:$2 action: replace - separator: ; regex: __meta_kubernetes_service_annotation_prometheus_io_param_(.+) replacement: __param_$1 action: labelmap - separator: ; regex: __meta_kubernetes_service_label_(.+) replacement: $1 action: labelmap - source_labels: [__meta_kubernetes_namespace] separator: ; regex: (.*) target_label: namespace replacement: $1 action: replace - source_labels: [__meta_kubernetes_service_name] separator: ; regex: (.*) target_label: service replacement: $1 action: replace - source_labels: [__meta_kubernetes_pod_node_name] separator: ; regex: (.*) target_label: node replacement: $1 action: replace kubernetes_sd_configs: - role: endpoints kubeconfig_file: "" follow_redirects: true enable_http2: true - job_name: prometheus-pushgateway honor_labels: true honor_timestamps: true scrape_interval: 1m scrape_timeout: 10s metrics_path: /metrics scheme: http follow_redirects: true enable_http2: true relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_probe] separator: ; regex: pushgateway replacement: $1 action: keep kubernetes_sd_configs: - role: service kubeconfig_file: "" follow_redirects: true enable_http2: true - job_name: kubernetes-services honor_labels: true honor_timestamps: true params: module: - http_2xx scrape_interval: 1m scrape_timeout: 10s metrics_path: /probe scheme: http follow_redirects: true enable_http2: true relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_probe] separator: ; regex: "true" replacement: $1 action: keep - source_labels: [__address__] separator: ; regex: (.*) target_label: __param_target replacement: $1 action: replace - separator: ; regex: (.*) target_label: __address__ replacement: blackbox action: replace - source_labels: [__param_target] separator: ; regex: (.*) target_label: instance replacement: $1 action: replace - separator: ; regex: __meta_kubernetes_service_label_(.+) replacement: $1 action: labelmap - source_labels: [__meta_kubernetes_namespace] separator: ; regex: (.*) target_label: namespace replacement: $1 action: replace - source_labels: [__meta_kubernetes_service_name] separator: ; regex: (.*) target_label: service replacement: $1 action: replace kubernetes_sd_configs: - role: service kubeconfig_file: "" follow_redirects: true enable_http2: true - job_name: kubernetes-pods honor_labels: true honor_timestamps: true scrape_interval: 1m scrape_timeout: 10s metrics_path: /metrics scheme: http follow_redirects: true enable_http2: true relabel_configs: - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape] separator: ; regex: "true" replacement: $1 action: keep - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape_slow] separator: ; regex: "true" replacement: $1 action: drop - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scheme] separator: ; regex: (https?) target_label: __scheme__ replacement: $1 action: replace - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path] separator: ; regex: (.+) target_label: __metrics_path__ replacement: $1 action: replace - source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] separator: ; regex: (.+?)(?::\d+)?;(\d+) target_label: __address__ replacement: $1:$2 action: replace - separator: ; regex: __meta_kubernetes_pod_annotation_prometheus_io_param_(.+) replacement: __param_$1 action: labelmap - separator: ; regex: __meta_kubernetes_pod_label_(.+) replacement: $1 action: labelmap - source_labels: [__meta_kubernetes_namespace] separator: ; regex: (.*) target_label: namespace replacement: $1 action: replace - source_labels: [__meta_kubernetes_pod_name] separator: ; regex: (.*) target_label: pod replacement: $1 action: replace - source_labels: [__meta_kubernetes_pod_phase] separator: ; regex: Pending|Succeeded|Failed|Completed replacement: $1 action: drop kubernetes_sd_configs: - role: pod kubeconfig_file: "" follow_redirects: true enable_http2: true - job_name: kubernetes-pods-slow honor_labels: true honor_timestamps: true scrape_interval: 5m scrape_timeout: 30s metrics_path: /metrics scheme: http follow_redirects: true enable_http2: true relabel_configs: - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape_slow] separator: ; regex: "true" replacement: $1 action: keep - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scheme] separator: ; regex: (https?) target_label: __scheme__ replacement: $1 action: replace - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path] separator: ; regex: (.+) target_label: __metrics_path__ replacement: $1 action: replace - source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] separator: ; regex: (.+?)(?::\d+)?;(\d+) target_label: __address__ replacement: $1:$2 action: replace - separator: ; regex: __meta_kubernetes_pod_annotation_prometheus_io_param_(.+) replacement: __param_$1 action: labelmap - separator: ; regex: __meta_kubernetes_pod_label_(.+) replacement: $1 action: labelmap - source_labels: [__meta_kubernetes_namespace] separator: ; regex: (.*) target_label: namespace replacement: $1 action: replace - source_labels: [__meta_kubernetes_pod_name] separator: ; regex: (.*) target_label: pod replacement: $1 action: replace - source_labels: [__meta_kubernetes_pod_phase] separator: ; regex: Pending|Succeeded|Failed|Completed replacement: $1 action: drop kubernetes_sd_configs: - role: pod kubeconfig_file: "" follow_redirects: true enable_http2: true
8 - What's New?
Unreleased
v0.14.5
Fixed
- Fix kubectl get call to point to full API name (#5342 )
- Expand all kubectl calls to fully qualified names (#5347 )
v0.14.4
Added
--no-timeoutsflag in create and upgrade commands to disable timeout for all wait operations- Management resources backup procedure with clusterctl
v0.14.3
Added
--aws-regionflag tocopy packagescommand.
Upgraded
- CAPAS from
v0.1.22tov0.1.24.
v0.14.2
Added
- Enabled support for Kubernetes version 1.25
v0.14.1
Added
- support for authenticated pulls from registry mirror (#4796 )
- option to override default nodeStartupTimeout in machine health check (#4800 )
- Validate control plane endpoint with pods and services CIDR blocks(#4816 )
Fixed
- Fixed a issue where registry mirror settings weren’t being applied properly on Bottlerocket nodes for Tinkerbell provider
v0.14.0
Added
- Add support for EKS Anywhere on AWS Snow (#1042 )
- Static IP support for BottleRocket (#4359 )
- Add registry mirror support for curated packages
- Add copy packages command (#4420 )
Fixed
- Improve management cluster name validation for workload clusters
v0.13.1
Added
- Multi-region support for all supported curated packages
Fixed
- Fixed nil pointer in
eksctl anywhere upgrade plancommand
v0.13.0
Added
- Workload clusters full lifecycle API support for vSphere and Docker (#1090 )
- Single node cluster support for Bare Metal provider
- Cilium updated to version
v1.11.10 - CLI high verbosity log output is automatically included in the support bundle after a CLI
clustercommand error (#1703 implemented by #4289 ) - Allow to configure machine health checks timeout through a new flag
--unhealthy-machine-timeout(#3918 implemented by #4123 ) - Ability to configure rolling upgrade for Bare Metal and Cloudstack via
maxSurgeandmaxUnavailableparameters - New Nutanix Provider
- Workload clusters support for Bare Metal
- VM Tagging support for vSphere VM’s created in the cluster (#4228 )
- Support for new curated packages:
- Prometheus
v2.39.1
- Prometheus
- Updated curated packages' versions:
- ADOT
v0.23.0upgraded fromv0.21.1 - Emissary
v3.3.0upgraded fromv3.0.0 - Metallb
v0.13.7upgraded fromv0.13.5
- ADOT
- Support for packages controller to create target namespaces #601
- (For more EKS Anywhere packages info: v0.13.0 )
Fixed
- Kubernetes version upgrades from 1.23 to 1.24 for Docker clusters (#4266 )
- Added missing docker login when doing authenticated registry pulls
Breaking changes
- Removed support for Kubernetes 1.20
v0.12.2
Added
- Add support for Kubernetes 1.24 (CloudStack support to come in future releases)#3491
Fixed
- Fix authenticated registry mirror validations
- Fix capc bug causing orphaned VM’s in slow environments
- Bundle activation problem for package controller
v0.12.1
Changed
- Setting minimum wait time for nodes and machinedeployments (#3868, fixes #3822)
Fixed
- Fixed worker node count pointer dereference issue (#3852)
- Fixed eks-anywhere-packages reference in go.mod (#3902)
- Surface dropped error in Cloudstack validations (#3832)
v0.12.0
⚠️ Breaking changes
- Certificates signed with SHA-1 are not supported anymore for Registry Mirror. Users with a registry mirror and providing a custom CA cert will need to rotate the certificate served by the registry mirror endpoint before using the new EKS-A version. This is true for both new clusters (
create clustercommand) and existing clusters (upgrade clustercommand). - The
--sourceoption was removed from several package commands. Use either--kube-versionfor registry or--clusterfor cluster.
Added
- Add support for EKS Anywhere with provider CloudStack
- Add support to upgrade Bare Metal cluster
- Add support for using Registry Mirror for Bare Metal
- Redhat-based node image support for vSphere, CloudStack and Bare Metal EKS Anywhere clusters
- Allow authenticated image pull using Registry Mirror for Ubuntu on vSphere cluster
- Add option to disable vSphere CSI driver #3148
- Add support for skipping load balancer deployment for Bare Metal so users can use their own load balancers #3608
- Add support to configure aws-iam-authenticator on workload clusters independent of management cluster #2814
- Add EKS Anywhere Packages support for remote management on workload clusters. (For more EKS Anywhere packages info: v0.12.0 )
- Add new EKS Anywhere Packages
- AWS Distro for OpenTelemetry (ADOT)
- Cert Manager
- Cluster Autoscaler
- Metrics Server
Fixed
- Remove special cilium network policy with
policyEnforcementModeset toalwaysdue to lack of pod network connectivity for vSphere CSI - Fixed #3391 #3560 for AWSIamConfig upgrades on EKS Anywhere workload clusters
v0.11.4
Added
- Add validate session permission for vsphere
Fixed
- Fix datacenter naming bug for vSphere #3381
- Fix os family validation for vSphere
- Fix controller overwriting secret for vSphere #3404
- Fix unintended rolling upgrades when upgrading from an older EKS-A version for CloudStack
v0.11.3
Added
- Add some bundleRef validation
- Enable kube-rbac-proxy on CloudStack cluster controller’s metrics port
Fixed
- Fix issue with fetching EKS-D CRDs/manifests with retries
- Update BundlesRef when building a Spec from file
- Fix worker node upgrade inconsistency in Cloudstack
v0.11.2
Added
- Add a preflight check to validate vSphere user’s permissions #2744
Changed
- Make
DiskOfferinginCloudStackMachineConfigoptional
Fixed
- Fix upgrade failure when flux is enabled #3091 #3093
- Add token-refresher to default images to fix import/download images commands
- Improve retry logic for transient issues with kubectl applies and helm pulls #3167
- Fix issue fetching curated packages images
v0.11.1
Added
- Add
--insecureflag to import/download images commands #2878
v0.11.0
Breaking Changes
- EKS Anywhere no longer distributes Ubuntu OVAs for use with EKS Anywhere clusters. Building your own Ubuntu-based nodes as described in Building node images is the only supported way to get that functionality.
Added
- Add support for Kubernetes 1.23 #2159
- Add support for Support Bundle for validating control plane IP with vSphere provider
- Add support for aws-iam-authenticator on Bare Metal
- Curated Packages General Availability
- Added Emissary Ingress Curated Package
Changed
- Install and enable GitOps in the existing cluster with upgrade command
v0.10.1
Changed
- Updated EKS Distro versions to latest release
Fixed
- Fixed control plane nodes not upgraded for same kube version #2636
v0.10.0
Added
- Added support for EKS Anywhere on bare metal with provider tinkerbell . EKS Anywhere on bare metal supports complete provisioning cycle, including power on/off and PXE boot for standing up a cluster with the given hardware data.
- Support for node CIDR mask config exposed via the cluster spec. #488
Changed
Fixed
- Fix issue using self-signed certificates for registry mirror #1857
v0.9.2
Fixed
- Fix issue by avoiding processing Snow images when URI is empty
v0.9.1
v0.9.0
Added
- Adding support to EKS Anywhere for a generic git provider as the source of truth for GitOps configuration management. #9
- Allow users to configure Cloud Provider and CSI Driver with different credentials. #1730
- Support to install, configure and maintain operational components that are secure and tested by Amazon on EKS Anywhere clusters.#2083
- A new Workshop section has been added to EKS Anywhere documentation.
- Added support for curated packages behind a feature flag #1893
Fixed
- Fix issue specifying proxy configuration for helm template command #2009
v0.8.2
Fixed
- Fix issue with upgrading cluster from a previous minor version #1819
v0.8.1
Fixed
- Fix issue with downloading artifacts #1753
v0.8.0
Added
- SSH keys and Users are now mutable #1208
- OIDC configuration is now mutable #676
- Add support for Cilium’s policy enforcement mode #726
Changed
- Install Cilium networking through Helm instead of static manifest
v0.7.2 - 2022-02-28
Fixed
- Fix issue with downloading artifacts #1327
v0.7.1 - 2022-02-25
Added
- Support for taints in worker node group configurations #189
- Support for taints in control plane configurations #189
- Support for labels in worker node group configuration #486
- Allow removal of worker node groups using the
eksctl anywhere upgradecommand #1054
v0.7.0 - 2022-01-27
Added
- Support for
aws-iam-authenticatoras an authentication option in EKS-A clusters #90 - Support for multiple worker node groups in EKS-A clusters #840
- Support for IAM Role for Service Account (IRSA) #601
- New command
upgrade plan clusterlists core component changes affected byupgrade cluster#499 - Support for workload cluster’s control plane and etcd upgrade through GitOps #1007
- Upgrading a Flux managed cluster previously required manual steps. These steps have now been automated. #759 , #1019
- Cilium CNI will now be upgraded by the
upgrade clustercommand #326
Changed
- EKS-A now uses Cluster API (CAPI) v1.0.1 and v1beta1 manifests, upgrading from v0.3.23 and v1alpha3 manifests.
- Kubernetes components and etcd now use TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256 as the configured TLS cipher suite #657 , #759
- Automated git repository structure changes during Flux component
upgradeworkflow #577
v0.6.0 - 2021-10-29
Added
- Support to create and manage workload clusters #94
- Support for upgrading eks-anywhere components #93
, Cluster upgrades
- IMPORTANT: Currently upgrading existing flux manged clusters requires performing a few additional steps
. The fix for upgrading the existing clusters will be published in
0.6.1release to improve the upgrade experience.
- IMPORTANT: Currently upgrading existing flux manged clusters requires performing a few additional steps
. The fix for upgrading the existing clusters will be published in
- k8s CIS compliance #193
- Support bundle improvements #92
- Ability to upgrade control plane nodes before worker nodes #100
- Ability to use your own container registry #98
- Make namespace configurable for anywhere resources #177
Fixed
- Fix ova auto-import issue for multi-datacenter environments #437
- OVA import via EKS-A CLI sometimes fails #254
- Add proxy configuration to etcd nodes for bottlerocket #195
Removed
- overrideClusterSpecFile field in cluster config
v0.5.0
Added
- Initial release of EKS-A
9 - Frequently Asked Questions
AuthN / AuthZ
How do my applications running on EKS Anywhere authenticate with AWS services using IAM credentials?
You can now leverage the IAM Role for Service Account (IRSA) feature by following the IRSA reference guide for details.
Does EKS Anywhere support OIDC (including Azure AD and AD FS)?
Yes, EKS Anywhere can create clusters that support API server OIDC authentication. This means you can federate authentication through AD FS locally or through Azure AD, along with other IDPs that support the OIDC standard. In order to add OIDC support to your EKS Anywhere clusters, you need to configure your cluster by updating the configuration file before creating the cluster. Please see the OIDC reference for details.
Does EKS Anywhere support LDAP?
EKS Anywhere does not support LDAP out of the box. However, you can look into the Dex LDAP Connector .
Can I use AWS IAM for Kubernetes resource access control on EKS Anywhere?
Yes, you can install the aws-iam-authenticator on your EKS Anywhere cluster to achieve this.
Miscellaneous
How much does EKS Anywhere cost?
EKS Anywhere is free, open source software that you can download, install on your existing hardware, and run in your own data centers. It includes management and CLI tooling for all supported cluster topologies on all supported providers . You are responsible for providing infrastructure where EKS Anywhere runs (e.g. VMware, bare metal), and some providers require third party hardware and software contracts.
The EKS Anywhere Enterprise Subscription provides access to curated packages and enterprise support. This is an optional—but recommended—cost based on how many clusters and how many years of support you need.
Can I connect my EKS Anywhere cluster to EKS?
Yes, you can install EKS Connector to connect your EKS Anywhere cluster to AWS EKS. EKS Connector is a software agent that you can install on the EKS Anywhere cluster that enables the cluster to communicate back to AWS. Once connected, you can immediately see a read-only view of the EKS Anywhere cluster with workload and cluster configuration information on the EKS console, alongside your EKS clusters.
How does the EKS Connector authenticate with AWS?
During start-up, the EKS Connector generates and stores an RSA key-pair as Kubernetes secrets. It also registers with AWS using the public key and the activation details from the cluster registration configuration file. The EKS Connector needs AWS credentials to receive commands from AWS and to send the response back. Whenever it requires AWS credentials, it uses its private key to sign the request and invokes AWS APIs to request the credentials.
How does the EKS Connector authenticate with my Kubernetes cluster?
The EKS Connector acts as a proxy and forwards the EKS console requests to the Kubernetes API server on your cluster. In the initial release, the connector uses impersonation with its service account secrets to interact with the API server. Therefore, you need to associate the connector’s service account with a ClusterRole, which gives permission to impersonate AWS IAM entities.
How do I enable an AWS user account to view my connected cluster through the EKS console?
For each AWS user or other IAM identity, you should add cluster role binding to the Kubernetes cluster with the appropriate permission for that IAM identity. Additionally, each of these IAM entities should be associated with the IAM policy to invoke the EKS Connector on the cluster.
Can I use Amazon Controllers for Kubernetes (ACK) on EKS Anywhere?
Yes, you can leverage AWS services from your EKS Anywhere clusters on-premises through Amazon Controllers for Kubernetes (ACK) .
Can I deploy EKS Anywhere on other clouds?
EKS Anywhere can be installed on any infrastructure with the required Bare Metal, Cloudstack, or VMware vSphere components. See EKS Anywhere Baremetal , CloudStack , or vSphere documentation.
How is EKS Anywhere different from ECS Anywhere?
Amazon ECS Anywhere is an option for Amazon Elastic Container Service (ECS) to run containers on your on-premises infrastructure. The ECS Anywhere Control Plane runs in an AWS region and allows you to install the ECS agent on worker nodes that run outside of an AWS region. Workloads that run on ECS Anywhere nodes are scheduled by ECS. You are not responsible for running, managing, or upgrading the ECS Control Plane.
EKS Anywhere runs the Kubernetes Control Plane and worker nodes on your infrastructure. You are responsible for managing the EKS Anywhere Control Plane and worker nodes. There is no requirement to have an AWS account to run EKS Anywhere.
If you’d like to see how EKS Anywhere compares to EKS please see the information here.
How can I manage EKS Anywhere at scale?
You can perform cluster life cycle and configuration management at scale through GitOps-based tools. EKS Anywhere offers git-driven cluster management through the integrated Flux Controller. See Manage cluster with GitOps documentation for details.
Can I run EKS Anywhere on ESXi?
No. EKS Anywhere is only supported on providers listed on the Create production cluster page. There would need to be a change to the upstream project to support ESXi.
Can I deploy EKS Anywhere on a single node?
Yes. Single node cluster deployment is supported for Bare Metal. See workerNodeGroupConfigurations
10 - Troubleshooting
Read more about troubleshooting in the tasks section.
11 - Support
11.1 - Support scope
Enterprise support for Amazon EKS Anywhere is available to Amazon customers who pay for the Amazon EKS Anywhere Enterprise subscription. If you would like to purchase the Amazon EKS Anywhere Enterprise Subscription, contact an AWS specialist.
EKS Anywhere is an open source project and it is supported by the community. If you have a problem, open an issue and someone will get back to you as soon as possible. If you discover a potential security issue in this project, we ask that you notify AWS/Amazon Security via our vulnerability reporting page. Please do not create a public GitHub issue for security problems.
Operating system support
EKS Anywhere has some level of support for the following operating system nodes:
-
Bottlerocket: Bottlerocket is the only fully-supported operating system for EKS Anywhere nodes. Bottlerocket OVAs and Raw images are distributed by the EKS Anywhere project. See the Artifacts page for details on how to download Bottlerocket images for EKS Anywhere.
-
Ubuntu: EKS Anywhere has been tested with Ubuntu-based nodes. Amazon will assist with troubleshooting and configuration guidance with Ubuntu-based nodes under the EKS Anywhere Enterprise Subscription. To build your own Ubuntu-based EKS Anywhere node image, refer to Building node images . For official Ubuntu support, see the Canonical Support page.
-
Red Hat Enterprise Linux (RHEL): EKS Anywhere has been tested with RHEL-based nodes. As with Ubuntu, Amazon will assist with troubleshooting and configuration guidance with RHEL-based nodes under the EKS Anywhere Enterprise Subscription. To build your own RHEL-based EKS Anywhere node image, refer to Building node images . For official Red Hat support, see the Red Hat Enterprise Linux Subscriptions page.
Curated packages support
Amazon EKS Anywhere Curated Packages are Amazon-curated software packages that extend the core functionalities of Kubernetes on your EKS Anywhere clusters. All curated packages, including the curated OSS packages, are supported under the EKS Anywhere Enterprise Subscription.
11.2 - Version support
To see supported versions of Kubernetes for each release of EKS Anywhere, and information about that support, refer to the content below.
Kubernetes support
Each EKS Anywhere version generally includes support for multiple Kubernetes versions, with the exception of the initial few releases. Starting from EKS Anywhere version 0.11, the latest version supports at least four recent versions of Kubernetes. The end of support date of a Kubernetes version aligns with Amazon EKS in AWS as documented on the Amazon EKS Kubernetes release calendar .
Common vulnerabilities and exposures (CVE) patches and bug fixes, including those for the supported Kubernetes versions, are back-ported to the latest EKS Anywhere version (version n). The following table shows EKS Anywhere version support for different Kubernetes versions:
| Kubernetes version | Supported EKS Anywhere version | First supported | End of support |
|---|---|---|---|
| 1.25 | 0.14 | February 16, 2023 | April 2024 |
| 1.24 | 0.14, 0.13, 0.12 | November 17, 2022 | January 2024 |
| 1.23 | 0.14, 0.13, 0.12, 0.11 | August 18, 2022 | October 2023 |
| 1.22 | 0.14, 0.13, 0.12, 0.11, 0.10, 0.9, 0.8 | March 31, 2022 | May 2023 |
| 1.21 | 0.14, 0.13, 0.12, 0.11, 0.10, 0.9, 0.8, 0.7, 0.6, 0.5 | September 8, 2021 | March 30, 2023 |
| 1.20 | 0.12, 0.11, 0.10, 0.9, 0.8, 0.7, 0.6, 0.5 | September 8, 2021 | November 1, 2022 |
| 1.19 | Not supported | – | – |
| 1.18 | Not supported | – | – |
The following table notes which EKS Anywhere and related Kubernetes versions are currently supported for CVE patches and bug fixes:
| EKS Anywhere version | Kubernetes versions included | EKS Anywhere Release Date | CVE patches and bug fixes back-ported? |
|---|---|---|---|
| 0.14 | 1.25, 1.24, 1.23, 1.22, 1.21 | January 19, 2023 | Yes |
| 0.13 | 1.24, 1.23, 1.22, 1.21 | December 15, 2022 | Yes |
| 0.12 | 1.24, 1.23, 1.22, 1.21, 1.20 | October 20, 2022 | No |
| 0.11 | 1.23, 1.22, 1.21, 1.20 | August 18, 2022 | No |
| 0.10 | 1.22, 1.21, 1.20 | June 30, 2022 | No |
| 0.9 | 1.21, 1.20 | May 12, 2022 | No |
| 0.8 | 1.22, 1.21, 1.20 | March 31, 2022 | No |
| 0.7 | 1.21, 1.20 | January 27, 2022 | No |
| 0.6 | 1.21, 1.20 | October 29, 2021 | No |
| 0.5 | 1.21, 1.20 | September 8, 2021 | No |
- Amazon EKS Anywhere Enterprise subscription is required to receive AWS support on any Amazon EKS Anywhere clusters.
EKS Anywhere version support FAQs
What is the difference between an Amazon EKS Anywhere minor version versus a patch version?
An Amazon EKS Anywhere minor version includes new Amazon EKS Anywhere capabilities, bug fixes, security patches, and a new Kubernetes minor version if there is one. An Amazon EKS Anywhere patch version generally includes only bug fixes, security patches, and Kubernetes patch version. Amazon EKS Anywhere patch versions are released more frequently than the Amazon EKS Anywhere minor versions so you can receive the latest security and bug fixes sooner.
Where can I find the content of the Amazon EKS Anywhere versions?
You can find the content of the previous Amazon EKS Anywhere minor versions and patch versions on the What’s New page.
Will I get notified when there is a new Amazon EKS Anywhere version release?
You will get notified if you have subscribed as documented on the Release Alerts page.
Can I skip Amazon EKS Anywhere minor versions during cluster upgrade (such as going from v0.9 directly to v0.11)?
No. We perform regular upgrade reliability testing for sequential version upgrade (e.g. going from version 0.9 to 0.10, then from version 0.10 to 0.11), but we do not perform testing on non-sequential upgrade path (e.g. going from version 0.9 directly to 0.11). You should not skip minor versions during cluster upgrade. However, you can choose to skip patch versions.
What kind of fixes are back-ported to the previous versions?*
Back-ported fixes include CVE patches and bug fixes for the Amazon EKS Anywhere components and the Kubernetes versions that are supported by the corresponding Amazon EKS Anywhere versions.
What happens on the end of support date for a Kubernetes version?
On the end of support date, you can still create a new cluster with the unsupported Kubernetes version using an old version of the Amazon EKS Anywhere toolkit that was released with this Kubernetes version. Any existing Amazon EKS Anywhere clusters with the unsupported Kubernetes version will continue to function. If you have the Amazon EKS Anywhere Enterprise subscription , AWS Support will continue to provide troubleshooting support and configuration guidance to those clusters as long as their Amazon EKS Anywhere versions are still being supported. However, you will not be able to receive CVE patches or bug fixes for the unsupported Kubernetes version.
Will I get notified when support is ending for a Kubernetes version on Amazon EKS Anywhere?
Not automatically. You should check this page regularly and take note of the end of support date for the Kubernetes version you’re using.
12 - Artifacts
EKS Anywhere supports three different node operating systems:
- Bottlerocket: For vSphere and Bare Metal providers
- Ubuntu: For vSphere, Bare Metal, Nutanix, and Snow providers
- Red Hat Enterprise Linux (RHEL): For vSphere, CloudStack, and Bare Metal providers
Bottlerocket OVAs and images are distributed by the EKS Anywhere project. To build your own Ubuntu-based or RHEL-based EKS Anywhere node, see Building node images .
Bare Metal artifacts
Artifacts for EKS Anyware Bare Metal clusters are listed below.
If you like, you can download these images and serve them locally to speed up cluster creation.
See descriptions of the osImageURL
and hookImagesURLPath
fields for details.
Ubuntu or RHEL OS images for Bare Metal
EKS Anywhere does not distribute Ubuntu or RHEL OS images. However, see Building node images for information on how to build EKS Anywhere images from those Linux distributions.
Bottlerocket OS images for Bare Metal
Bottlerocket vends its Baremetal variant Images using a secure distribution tool called tuftool. Please refer to Download Bottlerocket node images
to download Bottlerocket image. You can also get the download URIs for Bottlerocket Baremetal images from the bundle release by running the following command:
LATEST_EKSA_RELEASE_VERSION=$(curl -sL https://anywhere-assets.eks.amazonaws.com/releases/eks-a/manifest.yaml | yq ".spec.latestVersion")
BUNDLE_MANIFEST_URL=$(curl -sL https://anywhere-assets.eks.amazonaws.com/releases/eks-a/manifest.yaml | yq ".spec.releases[] | select(.version==\"$LATEST_EKSA_RELEASE_VERSION\").bundleManifestUrl")
curl -s $BUNDLE_MANIFEST_URL | yq ".spec.versionsBundles[].eksD.raw.bottlerocket.uri"
HookOS (kernel and initial ramdisk) for Bare Metal
kernel:
LATEST_EKSA_RELEASE_VERSION=$(curl -sL https://anywhere-assets.eks.amazonaws.com/releases/eks-a/manifest.yaml | yq ".spec.latestVersion")
BUNDLE_MANIFEST_URL=$(curl -sL https://anywhere-assets.eks.amazonaws.com/releases/eks-a/manifest.yaml | yq ".spec.releases[] | select(.version==\"$LATEST_EKSA_RELEASE_VERSION\").bundleManifestUrl")
curl -s $BUNDLE_MANIFEST_URL | yq ".spec.versionsBundles[0].tinkerbell.tinkerbellStack.hook.vmlinuz.amd.uri"
initial ramdisk:
LATEST_EKSA_RELEASE_VERSION=$(curl -sL https://anywhere-assets.eks.amazonaws.com/releases/eks-a/manifest.yaml | yq ".spec.latestVersion")
BUNDLE_MANIFEST_URL=$(curl -sL https://anywhere-assets.eks.amazonaws.com/releases/eks-a/manifest.yaml | yq ".spec.releases[] | select(.version==\"$LATEST_EKSA_RELEASE_VERSION\").bundleManifestUrl")
curl -s $BUNDLE_MANIFEST_URL | yq ".spec.versionsBundles[0].tinkerbell.tinkerbellStack.hook.initramfs.amd.uri"
vSphere artifacts
Bottlerocket OVAs
Bottlerocket vends its VMware variant OVAs using a secure distribution tool called tuftool. Please refer Download Bottlerocket node images
to download Bottlerocket OVA. You can also get the download URIs for Bottlerocket OVAs from the bundle release by running the following command:
LATEST_EKSA_RELEASE_VERSION=$(curl -sL https://anywhere-assets.eks.amazonaws.com/releases/eks-a/manifest.yaml | yq ".spec.latestVersion")
BUNDLE_MANIFEST_URL=$(curl -sL https://anywhere-assets.eks.amazonaws.com/releases/eks-a/manifest.yaml | yq ".spec.releases[] | select(.version==\"$LATEST_EKSA_RELEASE_VERSION\").bundleManifestUrl")
curl -s $BUNDLE_MANIFEST_URL | yq ".spec.versionsBundles[].eksD.ova.bottlerocket.uri"
Bottlerocket Template Tags
OS Family - os:bottlerocket
EKS Distro Release
1.25 - eksdRelease:kubernetes-1-25-eks-7
1.24 - eksdRelease:kubernetes-1-24-eks-11
1.23 - eksdRelease:kubernetes-1-23-eks-16
1.22 - eksdRelease:kubernetes-1-22-eks-21
1.21 - eksdRelease:kubernetes-1-21-eks-26
Ubuntu OVAs
EKS Anywhere no longer distributes Ubuntu OVAs for use with EKS Anywhere clusters. Building your own Ubuntu-based nodes as described in Building node images is the only supported way to get that functionality.
Download Bottlerocket node images
Bottlerocket vends its VMware variant OVAs and Baremetal variants images using a secure distribution tool called tuftool. Please follow instructions down below to
download Bottlerocket node images.
- Install Rust and Cargo
curl https://sh.rustup.rs -sSf | sh
- Install
tuftoolusing Cargo
CARGO_NET_GIT_FETCH_WITH_CLI=true cargo install --force tuftool
- Download the root role that will be used by
tuftoolto download the Bottlerocket images
curl -O "https://cache.bottlerocket.aws/root.json"
sha512sum -c <<<"b81af4d8eb86743539fbc4709d33ada7b118d9f929f0c2f6c04e1d41f46241ed80423666d169079d736ab79965b4dd25a5a6db5f01578b397496d49ce11a3aa2 root.json"
- Export the desired Kubernetes version. EKS Anywhere currently supports 1.21, 1.22, 1.23, 1.24 and 1.25.
export KUBEVERSION="1.25"
-
Download Bottlerocket node image
a. To download VMware variant Bottlerocket OVA
OVA="bottlerocket-vmware-k8s-${KUBEVERSION}-x86_64-v1.12.0.ova" tuftool download ${TMPDIR:-/tmp/bottlerocket-ovas} --target-name "${OVA}" \ --root ./root.json \ --metadata-url "https://updates.bottlerocket.aws/2020-07-07/vmware-k8s-${KUBEVERSION}/x86_64/" \ --targets-url "https://updates.bottlerocket.aws/targets/"The above command will download a Bottlerocket OVA. Please refer Deploy an OVA Template to proceed with the downloaded OVA.
b. To download Baremetal variant Bottlerocket image
IMAGE="bottlerocket-metal-k8s-${KUBEVERSION}-x86_64-v1.12.0.img.lz4" tuftool download ${TMPDIR:-/tmp/bottlerocket-metal} --target-name "${IMAGE}" \ --root ./root.json \ --metadata-url "https://updates.bottlerocket.aws/2020-07-07/metal-k8s-${KUBEVERSION}/x86_64/" \ --targets-url "https://updates.bottlerocket.aws/targets/"The above command will download a Bottlerocket lz4 compressed image. Decompress and gzip the image with the following commands and host the image on a webserver for using it for an EKS Anywhere Baremetal cluster.
lz4 --decompress ${TMPDIR:-/tmp/bottlerocket-metal}/${IMAGE} ${TMPDIR:-/tmp/bottlerocket-metal}/bottlerocket.img gzip ${TMPDIR:-/tmp/bottlerocket-metal}/bottlerocket.img
Building node images
The image-builder CLI lets you build your own Ubuntu-based vSphere OVAs, Nutanix qcow2 images, RHEL-based qcow2 images, or Bare Metal gzip images to use in EKS Anywhere clusters.
When you run image-builder, it will pull in all components needed to build images to be used as Kubernetes nodes in an EKS Anywhere cluster, including the latest operating system, Kubernetes control plane components, and EKS Distro security updates, bug fixes, and patches.
When building an image using this tool, you get to choose:
- Operating system type (for example, ubuntu, redhat)
- Provider (vsphere, cloudstack, baremetal, ami, nutanix)
- Release channel for EKS Distro (generally aligning with Kubernetes releases)
- vSphere only: configuration file providing information needed to access your vSphere setup
- CloudStack only: configuration file providing information needed to access your CloudStack setup
- Snow AMI only: configuration file providing information needed to customize your Snow AMI build parameters
- Nutanix only: configuration file providing information needed to access Nutanix Prism Central
Because image-builder creates images in the same way that the EKS Anywhere project does for their own testing, images built with that tool are supported.
The table below shows the support matrix for the hypervisor and OS combinations that image-builder supports.
| vSphere | Baremetal | CloudStack | Nutanix | Snow | |
|---|---|---|---|---|---|
| Ubuntu | ✓ | ✓ | ✓ | ✓ | |
| RHEL | ✓ | ✓ | ✓ |
Prerequisites
To use image-builder, you must meet the following prerequisites:
System requirements
image-builder has been tested on Ubuntu, RHEL and Amazon Linux 2 machines. The following system requirements should be met for the machine on which image-builder is run:
- AMD 64-bit architecture
- 50 GB disk space
- 2 vCPUs
- 8 GB RAM
- Baremetal only: Run on a bare metal machine with virtualization enabled
Network connectivity requirements
- public.ecr.aws (to download container images from EKS Anywhere)
- anywhere-assets.eks.amazonaws.com (to download the EKS Anywhere artifacts such as binaries, manifests and OS images)
- distro.eks.amazonaws.com (to download EKS Distro binaries and manifests)
- d2glxqk2uabbnd.cloudfront.net (to pull the EKS Anywhere and EKS Distro ECR container images)
- api.ecr.us-west-2.amazonaws.com (for EKS Anywhere package authentication matching your region)
- d5l0dvt14r5h8.cloudfront.net (for EKS Anywhere package ECR container)
- github.com (to download binaries and tools required for image builds from GitHub releases)
- releases.hashicorp.com (to download Packer binary for image builds)
- galaxy.ansible.com (to download Ansible packages from Ansible Galaxy)
- vSphere only: VMware vCenter endpoint
- CloudStack only: Apache CloudStack endpoint
- Nutanix only: Nutanix Prism Central endpoint
- Red Hat only: dl.fedoraproject.org (to download RPMs and GPG keys for RHEL image builds)
- Ubuntu only: cdimage.ubuntu.com (to download Ubuntu server ISOs for Ubuntu image builds)
vSphere requirements
image-builder uses the Hashicorp vsphere-iso Packer Builder for building vSphere OVAs.
Permissions
Configure a user with a role containing the following permissions.
The role can be configured programmatically with the govc command below, or configured in the vSphere UI using the table below as reference.
Note that no matter how the role is created, it must be assigned to the user or user group at the Global Permissions level.
Unfortunately there is no API for managing vSphere Global Permissions, so they must be set on the user via the UI under Administration > Access Control > Global Permissions.
To generate a role named EKSAImageBuilder with the required privileges via govc, run the following:
govc role.create "EKSAImageBuilder" $(curl https://raw.githubusercontent.com/aws/eks-anywhere/main/pkg/config/static/imageBuilderPrivs.json | jq .[] | tr '\n' ' ' | tr -d '"')
If creating a role with these privileges via the UI, refer to the table below.
| Category | UI Privilege | Programmatic Privilege |
|---|---|---|
| Content Library | Add library item | ContentLibrary.AddLibraryItem |
| Content Library | Delete library item | ContentLibrary.DeleteLibraryItem |
| Content Library | Download files | ContentLibrary.DownloadSession |
| Content Library | Evict library item | ContentLibrary.EvictLibraryItem |
| Content Library | Update library item | ContentLibrary.UpdateLibraryItem |
| Datastore | Allocate space | Datastore.AllocateSpace |
| Datastore | Browse datastore | Datastore.Browse |
| Datastore | Low level file operations | Datastore.FileManagement |
| Network | Assign network | Network.Assign |
| Resource | Assign virtual machine to resource pool | Resource.AssignVMToPool |
| vApp | Export | vApp.Export |
| VirtualMachine | Configuration > Add new disk | VirtualMachine.Config.AddNewDisk |
| VirtualMachine | Configuration > Add or remove device | VirtualMachine.Config.AddRemoveDevice |
| VirtualMachine | Configuration > Advanced configuration | VirtualMachine.Config.AdvancedConfiguration |
| VirtualMachine | Configuration > Change CPU count | VirtualMachine.Config.CPUCount |
| VirtualMachine | Configuration > Change memory | VirtualMachine.Config.Memory |
| VirtualMachine | Configuration > Change settings | VirtualMachine.Config.Settings |
| VirtualMachine | Configuration > Change Resource | VirtualMachine.Config.Resource |
| VirtualMachine | Configuration > Set annotation | VirtualMachine.Config.Annotation |
| VirtualMachine | Edit Inventory > Create from existing | VirtualMachine.Inventory.CreateFromExisting |
| VirtualMachine | Edit Inventory > Create new | VirtualMachine.Inventory.Create |
| VirtualMachine | Edit Inventory > Remove | VirtualMachine.Inventory.Delete |
| VirtualMachine | Interaction > Configure CD media | VirtualMachine.Interact.SetCDMedia |
| VirtualMachine | Interaction > Configure floppy media | VirtualMachine.Interact.SetFloppyMedia |
| VirtualMachine | Interaction > Connect devices | VirtualMachine.Interact.DeviceConnection |
| VirtualMachine | Interaction > Inject USB HID scan codes | VirtualMachine.Interact.PutUsbScanCodes |
| VirtualMachine | Interaction > Power off | VirtualMachine.Interact.PowerOff |
| VirtualMachine | Interaction > Power on | VirtualMachine.Interact.PowerOn |
| VirtualMachine | Interaction > Create template from virtual machine | VirtualMachine.Provisioning.CreateTemplateFromVM |
| VirtualMachine | Interaction > Mark as template | VirtualMachine.Provisioning.MarkAsTemplate |
| VirtualMachine | Interaction > Mark as virtual machine | VirtualMachine.Provisioning.MarkAsVM |
| VirtualMachine | State > Create snapshot | VirtualMachine.State.CreateSnapshot |
CloudStack requirements
Refer to the CloudStack Permissions for CAPC doc for required CloudStack user permissions.
Snow AMI requirements
Packer will require prior authentication with your AWS account to launch EC2 instances for the Snow AMI build. Refer to the Authentication guide for Amazon EBS Packer builder
for possible modes of authentication. We recommend that you run image-builder on a pre-existing Ubuntu EC2 instance and use an IAM instance role with the required permissions
.
Nutanix permissions
Prism Central Administrator permissions are required to build a Nutanix image using image-builder.
Optional Proxy configuration
You can use a proxy server to route outbound requests to the internet. To configure image-builder tool to use a proxy server, export these proxy environment variables:
export HTTP_PROXY=<HTTP proxy URL e.g. http://proxy.corp.com:80>
export HTTPS_PROXY=<HTTPS proxy URL e.g. http://proxy.corp.com:443>
export NO_PROXY=<No proxy>
Build vSphere OVA node images
These steps use image-builder to create an Ubuntu-based or RHEL-based image for vSphere. Before proceeding, ensure that the above system-level, network-level and vSphere-specific prerequisites
have been met.
-
Create a linux user for running image-builder.
sudo adduser image-builderFollow the prompt to provide a password for the image-builder user.
-
Add image-builder user to the sudo group and change user as image-builder providing in the password from previous step when prompted.
sudo usermod -aG sudo image-builder su image-builder cd /home/$USER -
Install packages and prepare environment:
sudo apt update -y sudo apt install jq unzip make ansible python3-pip -y sudo snap install yq mkdir -p /home/$USER/.ssh echo "HostKeyAlgorithms +ssh-rsa" >> /home/$USER/.ssh/config echo "PubkeyAcceptedKeyTypes +ssh-rsa" >> /home/$USER/.ssh/config -
Get
image-builder:cd /tmp LATEST_EKSA_RELEASE_VERSION=$(curl -s https://anywhere-assets.eks.amazonaws.com/releases/eks-a/manifest.yaml | yq ".spec.latestVersion") BUNDLE_MANIFEST_URL=$(curl -s https://anywhere-assets.eks.amazonaws.com/releases/eks-a/manifest.yaml | yq ".spec.releases[] | select(.version==\"$LATEST_EKSA_RELEASE_VERSION\").bundleManifestUrl") IMAGEBUILDER_TARBALL_URI=$(curl -s $BUNDLE_MANIFEST_URL | yq ".spec.versionsBundles[0].eksD.imagebuilder.uri") curl -s $IMAGEBUILDER_TARBALL_URI | tar xz ./image-builder sudo cp ./image-builder /usr/local/bin cd - -
Get the latest version of
govc:curl -L -o - "https://github.com/vmware/govmomi/releases/latest/download/govc_$(uname -s)_$(uname -m).tar.gz" | sudo tar -C /usr/local/bin -xvzf - govc -
Create a content library on vSphere:
govc library.create "<library name>" -
Create a vsphere configuration file (for example,
vsphere-connection.json):{ "cluster": "<vsphere cluster used for image building>", "convert_to_template": "false", "create_snapshot": "<creates a snapshot on base OVA after building if set to true>", "datacenter": "<vsphere datacenter used for image building>", "datastore": "<datastore used to store template/for image building>", "folder": "<folder on vsphere to create temporary VM>", "insecure_connection": "true", "linked_clone": "false", "network": "<vsphere network used for image building>", "password": "<vcenter password>", "resource_pool": "<resource pool used for image building VM>", "username": "<vcenter username>", "vcenter_server": "<vcenter fqdn>", "vsphere_library_name": "<vsphere content library name>" }For RHEL images, add the following fields:
{ "iso_url": "<https://endpoint to RHEL ISO endpoint or path to file>", "iso_checksum": "<for example: ea5f349d492fed819e5086d351de47261c470fc794f7124805d176d69ddf1fcd>", "iso_checksum_type": "<for example: sha256>", "rhel_username": "<rhsm username>", "rhel_password": "<rhsm password>" } -
Create an Ubuntu or Redhat image:
-
To create an Ubuntu-based image, run
image-builderwith the following options:--os:ubuntu--hypervisor: For vSphere usevsphere--release-channel: Supported EKS Distro releases include 1-21, 1-22, 1-23, 1-24 and 1-25.--vsphere-config: vSphere configuration file (vsphere-connection.jsonin this example)
image-builder build --os ubuntu --hypervisor vsphere --release-channel 1-25 --vsphere-config vsphere-connection.json -
To create a RHEL-based image, run
image-builderwith the following options:--os:redhat--hypervisor: For vSphere usevsphere--release-channel: Supported EKS Distro releases include 1-21, 1-22, 1-23, 1-24 and 1-25.--vsphere-config: vSphere configuration file (vsphere-connection.jsonin this example)
image-builder build --os redhat --hypervisor vsphere --release-channel 1-25 --vsphere-config vsphere-connection.json
-
Build Bare Metal node images
These steps use image-builder to create an Ubuntu-based or RHEL-based image for Bare Metal. Before proceeding, ensure that the above system-level, network-level and baremetal-specific prerequisites
have been met.
-
Create a linux user for running image-builder.
sudo adduser image-builderFollow the prompt to provide a password for the image-builder user.
-
Add image-builder user to the sudo group and change user as image-builder providing in the password from previous step when prompted.
sudo usermod -aG sudo image-builder su image-builder cd /home/$USER -
Install packages and prepare environment:
sudo apt update -y sudo apt install jq make python3-pip qemu-kvm libvirt-daemon-system libvirt-clients virtinst cpu-checker libguestfs-tools libosinfo-bin unzip ansible -y sudo snap install yq sudo usermod -a -G kvm $USER sudo chmod 666 /dev/kvm sudo chown root:kvm /dev/kvm mkdir -p /home/$USER/.ssh echo "HostKeyAlgorithms +ssh-rsa" >> /home/$USER/.ssh/config echo "PubkeyAcceptedKeyTypes +ssh-rsa" >> /home/$USER/.ssh/config -
Get
image-builder:cd /tmp LATEST_EKSA_RELEASE_VERSION=$(curl -s https://anywhere-assets.eks.amazonaws.com/releases/eks-a/manifest.yaml | yq ".spec.latestVersion") BUNDLE_MANIFEST_URL=$(curl -s https://anywhere-assets.eks.amazonaws.com/releases/eks-a/manifest.yaml | yq ".spec.releases[] | select(.version==\"$LATEST_EKSA_RELEASE_VERSION\").bundleManifestUrl") IMAGEBUILDER_TARBALL_URI=$(curl -s $BUNDLE_MANIFEST_URL | yq ".spec.versionsBundles[0].eksD.imagebuilder.uri") curl -s $IMAGEBUILDER_TARBALL_URI | tar xz ./image-builder sudo cp ./image-builder /usr/local/bin cd - -
Create an Ubuntu or Red Hat image.
Ubuntu
Run
image-builderwith the following options:--os:ubuntu--hypervisor:baremetal--release-channel: A supported EKS Distro release formatted as “[major]-[minor]"; for example “1-25”
image-builder build --os ubuntu --hypervisor baremetal --release-channel 1-25Red Hat Enterprise Linux (RHEL)
RHEL images require a configuration file to identify the location of the RHEL 8 ISO image and Red Hat subscription information. The
image-buildercommand will temporarily consume a Red Hat subscription that is returned once the image is built.{ "iso_url": "<https://endpoint to RHEL ISO endpoint or path to file>", "iso_checksum": "<for example: ea5f349d492fed819e5086d351de47261c470fc794f7124805d176d69ddf1fcd>", "iso_checksum_type": "<for example: sha256>", "rhel_username": "<rhsm username>", "rhel_password": "<rhsm password>", "extra_rpms": "<space-separated list of RPM packages; useful for adding required drivers or other packages>" }Run the
image-builderwith the following options:--os:redhat--hypervisor:baremetal--release-channel: A supported EKS Distro release formatted as “[major]-[minor]"; for example “1-25”--baremetal-config: Bare metal config file
image-builder build --os redhat --hypervisor baremetal --release-channel 1-25 --baremetal-config baremetal.json -
To consume the image, serve it from an accessible web server, then create the bare metal cluster spec configuring the
osImageURLfield URL of the image. For example:osImageURL: "http://<artifact host address>/my-ubuntu-v1.23.9-eks-a-17-amd64.gz"See descriptions of osImageURL for further information.
Build CloudStack node images
These steps use image-builder to create a RHEL-based image for CloudStack. Before proceeding, ensure that the above system-level, network-level and CloudStack-specific prerequisites
have been met.
-
Create a linux user for running image-builder.
sudo adduser image-builderFollow the prompt to provide a password for the image-builder user.
-
Add image-builder user to the sudo group and change user as image-builder providing in the password from previous step when prompted.
sudo usermod -aG sudo image-builder su image-builder cd /home/$USER -
Install packages and prepare environment:
sudo apt update -y sudo apt install jq make python3-pip qemu-kvm libvirt-daemon-system libvirt-clients virtinst cpu-checker libguestfs-tools libosinfo-bin unzip ansible -y sudo snap install yq sudo usermod -a -G kvm $USER sudo chmod 666 /dev/kvm sudo chown root:kvm /dev/kvm mkdir -p /home/$USER/.ssh echo "HostKeyAlgorithms +ssh-rsa" >> /home/$USER/.ssh/config echo "PubkeyAcceptedKeyTypes +ssh-rsa" >> /home/$USER/.ssh/config -
Get
image-builder:cd /tmp LATEST_EKSA_RELEASE_VERSION=$(curl -s https://anywhere-assets.eks.amazonaws.com/releases/eks-a/manifest.yaml | yq ".spec.latestVersion") BUNDLE_MANIFEST_URL=$(curl -s https://anywhere-assets.eks.amazonaws.com/releases/eks-a/manifest.yaml | yq ".spec.releases[] | select(.version==\"$LATEST_EKSA_RELEASE_VERSION\").bundleManifestUrl") IMAGEBUILDER_TARBALL_URI=$(curl -s $BUNDLE_MANIFEST_URL | yq ".spec.versionsBundles[0].eksD.imagebuilder.uri") curl -s $IMAGEBUILDER_TARBALL_URI | tar xz ./image-builder sudo cp ./image-builder /usr/local/bin cd - -
Create a CloudStack configuration file (for example,
cloudstack.json) to identify the location of a Red Hat Enterprise Linux 8 ISO image and related checksum and Red Hat subscription information:{ "iso_url": "<https://endpoint to RHEL ISO endpoint or path to file>", "iso_checksum": "<for example: ea5f349d492fed819e5086d351de47261c470fc794f7124805d176d69ddf1fcd>", "iso_checksum_type": "<for example: sha256>", "rhel_username": "<rhsm username>", "rhel_password": "<rhsm password>" }NOTE: To build the RHEL-based image,
image-buildertemporarily consumes a Red Hat subscription. That subscription is returned once the image is built. -
To create a RHEL-based image, run
image-builderwith the following options:--os:redhat--hypervisor: For CloudStack usecloudstack--release-channel: Supported EKS Distro releases include 1-21, 1-22, 1-23, 1-24 and 1-25.--cloudstack-config: CloudStack configuration file (cloudstack.jsonin this example)
image-builder build --os redhat --hypervisor cloudstack --release-channel 1-25 --cloudstack-config cloudstack.json -
To consume the resulting RHEL-based image, add it as a template to your CloudStack setup as described in Preparing CloudStack .
Build Snow node images
These steps use image-builder to create an Ubuntu-based Amazon Machine Image (AMI) that is backed by EBS volumes for Snow. Before proceeding, ensure that the above system-level, network-level and AMI-specific prerequisites
have been met
-
Create a linux user for running image-builder.
sudo adduser image-builderFollow the prompt to provide a password for the image-builder user.
-
Add the
image-builderuser to thesudogroup and switch user toimage-builder, providing in the password from previous step when prompted.sudo usermod -aG sudo image-builder su image-builder cd /home/$USER -
Install packages and prepare environment:
sudo apt update -y sudo apt install jq unzip make ansible python3-pip -y sudo snap install yq mkdir -p /home/$USER/.ssh echo "HostKeyAlgorithms +ssh-rsa" >> /home/$USER/.ssh/config echo "PubkeyAcceptedKeyTypes +ssh-rsa" >> /home/$USER/.ssh/config -
Get
image-builder:cd /tmp LATEST_EKSA_RELEASE_VERSION=$(curl -s https://anywhere-assets.eks.amazonaws.com/releases/eks-a/manifest.yaml | yq ".spec.latestVersion") BUNDLE_MANIFEST_URL=$(curl -s https://anywhere-assets.eks.amazonaws.com/releases/eks-a/manifest.yaml | yq ".spec.releases[] | select(.version==\"$LATEST_EKSA_RELEASE_VERSION\").bundleManifestUrl") IMAGEBUILDER_TARBALL_URI=$(curl -s $BUNDLE_MANIFEST_URL | yq ".spec.versionsBundles[0].eksD.imagebuilder.uri") curl -s $IMAGEBUILDER_TARBALL_URI | tar xz ./image-builder sudo cp ./image-builder /usr/local/bin cd - -
Create an AMI configuration file (for example,
ami.json) that contains various AMI parameters.{ "ami_filter_name": "<Regular expression to filter a source AMI (default: ubuntu/images/*ubuntu-focal-20.04-amd64-server-*)>", "ami_filter_owners": "<AWS account ID or AWS owner alias such as 'amazon', 'aws-marketplace', etc (default: 679593333241 - the AWS Marketplace AWS account ID)>", "ami_regions": "<A list of AWS regions to copy the AMI to>", "aws_region": "<The AWS region in which to launch the EC2 instance to create the AMI>", "ansible_extra_vars": "<The absolute path to the additional variables to pass to Ansible. These are converted to the `--extra-vars` command-line argument. This path must be prefix with '@'>", "builder_instance_type": "<The EC2 instance type to use while building the AMI (default: t3.small)>", "custom_role": "<If set to true, this will run a custom Ansible role before the `sysprep` role to allow for further customization>", "custom_role_name_list" : "<Array of strings representing the absolute paths of custom Ansible roles to run. This field is mutually exclusive with custom_role_names>", "custom_role_names": "<Space-delimited string of the custom roles to run. This field is mutually exclusive with custom_role_name_list and is provided for compatibility with Ansible's input format>", "manifest_output": "<The absolute path to write the build artifacts manifest to. If you wish to export the AMI using this manifest, ensure that you provide a path that is not inside the '/home/$USER/eks-anywhere-build-tooling' path since that will be cleaned up when the build finishes>", "root_device_name": "<The device name used by EC2 for the root EBS volume attached to the instance>", "subnet_id": "<The ID of the subnet where Packer will launch the EC2 instance. This field is required when using a non-default VPC>", "volume_size": "<The size of the root EBS volume in GiB>", "volume_type": "<The type of root EBS volume, such as gp2, gp3, io1, etc.>" } -
To create an Ubuntu-based image, run
image-builderwith the following options:--os:ubuntu--hypervisor: For AMI, useami--release-channel: Supported EKS Distro releases include 1-21, 1-22, 1-23 and 1-24.--ami-config: AMI configuration file (ami.jsonin this example)
image-builder build --os ubuntu --hypervisor ami --release-channel 1-24 --ami-config ami.json -
After the build, the Ubuntu AMI will be available in your AWS account in the AWS region specified in your AMI configuration file. If you wish to export it as a Raw image, you can achieve this using the AWS CLI.
ARTIFACT_ID=$(cat <manifest output location> | jq -r '.builds[0].artifact_id') AMI_ID=$(echo $ARTIFACT_ID | cut -d: -f2) IMAGE_FORMAT=raw AMI_EXPORT_BUCKET_NAME=<S3 bucket to export the AMI to> AMI_EXPORT_PREFIX=<S3 prefix for the exported AMI object> EXPORT_RESPONSE=$(aws ec2 export-image --disk-image-format $IMAGE_FORMAT --s3-export-location S3Bucket=$AMI_EXPORT_BUCKET_NAME,S3Prefix=$AMI_EXPORT_PREFIX --image-id $AMI_ID) EXPORT_TASK_ID=$(echo $EXPORT_RESPONSE | jq -r '.ExportImageTaskId')The exported image will be available at the location
s3://$AMI_EXPORT_BUCKET_NAME/$AMI_EXPORT_PREFIX/$EXPORT_IMAGE_TASK_ID.raw.
Build Nutanix node images
These steps use image-builder to create a Ubuntu-based image for Nutanix AHV and import it into the AOS Image Service. Before proceeding, ensure that the above system-level, network-level and Nutanix-specific prerequisites
have been met.
-
Download an Ubuntu cloud image for the build and upload it to the AOS Image Service using Prism. You will need to specify this image name as the
source_image_namein thenutanix-connection.jsonconfig file specified below. -
Create a linux user for running image-builder.
sudo adduser image-builderFollow the prompt to provide a password for the image-builder user.
-
Add image-builder user to the sudo group and change user as image-builder providing in the password from previous step when prompted.
sudo usermod -aG sudo image-builder su image-builder cd /home/$USER -
Install packages and prepare environment:
sudo apt update -y sudo apt install jq unzip make ansible python3-pip -y sudo snap install yq mkdir -p /home/$USER/.ssh echo "HostKeyAlgorithms +ssh-rsa" >> /home/$USER/.ssh/config echo "PubkeyAcceptedKeyTypes +ssh-rsa" >> /home/$USER/.ssh/config -
Get
image-builder:cd /tmp LATEST_EKSA_RELEASE_VERSION=$(curl -s https://anywhere-assets.eks.amazonaws.com/releases/eks-a/manifest.yaml | yq ".spec.latestVersion") BUNDLE_MANIFEST_URL=$(curl -s https://anywhere-assets.eks.amazonaws.com/releases/eks-a/manifest.yaml | yq ".spec.releases[] | select(.version==\"$LATEST_EKSA_RELEASE_VERSION\").bundleManifestUrl") IMAGEBUILDER_TARBALL_URI=$(curl -s $BUNDLE_MANIFEST_URL | yq ".spec.versionsBundles[0].eksD.imagebuilder.uri") curl -s $IMAGEBUILDER_TARBALL_URI | tar xz ./image-builder sudo cp ./image-builder /usr/local/bin cd - -
Create a
nutanix-connection.jsonconfig file. More details on values can be found in the image-builder documentation . See example below:{ "nutanix_cluster_name": "Name of PE Cluster", "source_image_name": "Name of Source Image", "image_name": "Name of Destination Image", "nutanix_subnet_name": "Name of Subnet", "nutanix_endpoint": "Prism Central IP / FQDN", "nutanix_insecure": "false", "nutanix_port": "9440", "nutanix_username": "PrismCentral_Username", "nutanix_password": "PrismCentral_Password" } -
Run
image-builderwith the following options:--os:ubuntu--hypervisor: For Nutanix usenutanix--release-channel: Supported EKS Distro releases include 1-21, 1-22, 1-23, 1-24 and 1-25.--nutanix-config: Nutanix configuration file (nutanix-connection.jsonin this example)
cd /home/$USER image-builder build --os ubuntu --hypervisor nutanix --release-channel 1-25 --nutanix-config nutanix-connection.json
Images
The various images for EKS Anywhere can be found in the EKS Anywhere ECR repository . The various images for EKS Distro can be found in the EKS Distro ECR repository .
13 - Ports and protocols
EKS Anywhere requires that various ports on control plane and worker nodes be open. Some Kubernetes-specific ports need open access only from other Kubernetes nodes, while others are exposed externally. Beyond Kubernetes ports, someone managing an EKS Anywhere cluster must also have external access to ports on the underlying EKS Anywhere provider (such as VMware) and to external tooling (such as Jenkins).
If you are responsible for network firewall rules between nodes on your EKS Anywhere clusters, the following tables describe both Kubernetes and EKS Anywhere-specific ports you should be aware of.
Kubernetes control plane
The following table represents the ports published by the Kubernetes project that must be accessible on any Kubernetes control plane.
| Protocol | Direction | Port Range | Purpose | Used By |
|---|---|---|---|---|
| TCP | Inbound | 6443 | Kubernetes API server | All |
| TCP | Inbound | 10250 | Kubelet API | Self, Control plane |
| TCP | Inbound | 10259 | kube-scheduler | Self |
| TCP | Inbound | 10257 | kube-controller-manager | Self |
Although etcd ports are included in control plane section, you can also host your own etcd cluster externally or on custom ports.
| Protocol | Direction | Port Range | Purpose | Used By |
|---|---|---|---|---|
| TCP | Inbound | 2379-2380 | etcd server client API | kube-apiserver, etcd |
Use the following to access the SSH service on the control plane and etcd nodes:
| Protocol | Direction | Port Range | Purpose | Used By |
|---|---|---|---|---|
| TCP | Inbound | 22 | SSHD server | SSH clients |
Kubernetes worker nodes
The following table represents the ports published by the Kubernetes project that must be accessible from worker nodes.
| Protocol | Direction | Port Range | Purpose | Used By |
|---|---|---|---|---|
| TCP | Inbound | 10250 | Kubelet API | Self, Control plane |
| TCP | Inbound | 30000-32767 | NodePort Services | All |
The API server port that is sometimes switched to 443. Alternatively, the default port is kept as is and API server is put behind a load balancer that listens on 443 and routes the requests to API server on the default port.
Use the following to access the SSH service on the worker nodes:
| Protocol | Direction | Port Range | Purpose | Used By |
|---|---|---|---|---|
| TCP | Inbound | 22 | SSHD server | SSH clients |
Bare Metal provider
On the Admin machine for a Bare Metal provider, the following ports need to be accessible to all the nodes in the cluster, from the same level 2 network, for initially network booting:
| Protocol | Direction | Port Range | Purpose | Used By |
|---|---|---|---|---|
| UDP | Inbound | 67 | Boots DHCP | All nodes, for network boot |
| UDP | Inbound | 69 | Boots TFTP | All nodes, for network boot |
| TCP | Inbound | 80 | Boots HTTP | All nodes, for network boot |
| TCP | Inbound | 42113 | Tink-server gRPC | All nodes, talk to Tinkerbell |
| TCP | Inbound | 50061 | Hegel HTTP | All nodes, talk to Tinkerbell |
| TCP | Outbound | 623 | Rufio IPMI | All nodes, out-of-band power and next boot (optional ) |
| TCP | Outbound | 80,443 | Rufio Redfish | All nodes, out-of-band power and next boot (optional ) |
VMware provider
The following table displays ports that need to be accessible from the VMware provider running EKS Anywhere:
| Protocol | Direction | Port Range | Purpose | Used By |
|---|---|---|---|---|
| TCP | Inbound | 443 | vCenter Server | vCenter API endpoint |
| TCP | Inbound | 6443 | Kubernetes API server | Kubernetes API endpoint |
| TCP | Inbound | 2379 | Manager | Etcd API endpoint |
| TCP | Inbound | 2380 | Manager | Etcd API endpoint |
Nutanix provider
The following table displays ports that need to be accessible from the Nutanix provider running EKS Anywhere:
| Protocol | Direction | Port Range | Purpose | Used By |
|---|---|---|---|---|
| TCP | Inbound | 9440 | Prism Central Server | Prism Central API endpoint |
| TCP | Inbound | 6443 | Kubernetes API server | Kubernetes API endpoint |
| TCP | Inbound | 2379 | Manager | Etcd API endpoint |
| TCP | Inbound | 2380 | Manager | Etcd API endpoint |
Snow provider
In addition to the Ports Required to Use AWS Services on an AWS Snowball Edge Device , the following table displays ports that need to be accessible from the Snow provider running EKS Anywhere:
| Protocol | Direction | Port Range | Purpose | Used By |
|---|---|---|---|---|
| TCP | Inbound | 9092 | Device Controller | EKS Anywhere and CAPAS controller |
| TCP | Inbound | 8242 | EC2 HTTPS endpoint | EKS Anywhere and CAPAS controller |
| TCP | Inbound | 6443 | Kubernetes API server | Kubernetes API endpoint |
| TCP | Inbound | 2379 | Manager | Etcd API endpoint |
| TCP | Inbound | 2380 | Manager | Etcd API endpoint |
Control plane management tools
A variety of control plane management tools are available to use with EKS Anywhere. One example is Jenkins.
| Protocol | Direction | Port Range | Purpose | Used By |
|---|---|---|---|---|
| TCP | Inbound | 8080 | Jenkins Server | HTTP Jenkins endpoint |
| TCP | Inbound | 8443 | Jenkins Server | HTTPS Jenkins endpoint |
14 - Release Alerts
EKS Anywhere uses Amazon Simple Notification Service (SNS) to notify availability of a new release. It is recommended that your clusters are kept up to date with the latest EKS Anywhere release. Please follow the instructions below to subscribe to SNS notification.
- Sign in to your AWS Account
- Select us-east-1 region
- Go to the SNS Console
- In the left navigation pane, choose “Subscriptions”
- On the Subscriptions page, choose “Create subscription”
- On the Create subscription page, in the Details section enter the following information
- Topic ARN
arn:aws:sns:us-east-1:153288728732:eks-anywhere-updates - Protocol - Email
- Endpoint - Your preferred email address
- Topic ARN
- Choose Create Subscription
- In few minutes, you will receive an email asking you to confirm the subscription
- Click the confirmation link in the email
15 - eksctl anywhere CLI reference
The eksctl CLI, with the EKS Anywhere plugin added, lets you create and manage EKS Anywhere clusters.
While a cluster is running, most EKS Anywhere administration can be done using kubectl or other native Kubernetes tools.
Use this page as a reference to useful eksctl anywhere command examples for working with EKS Anywhere clusters.
Available eksctl anywhere commands include:
create clusterTo create an EKS Anywhere clusterupgradeTo upgrade a workload clusterdelete clusterTo delete an EKS Anywhere clustergenerate[clusterconfig|support-bundle|support-bundle-config|packages|hardware] To generate cluster, support configs, package configs, and tinkerbell hardware fileshelpTo get help informationversionTo get the EKS Anywhere version
Options used with multiple commands include:
-hor--helpTo get help for a command or subcommand-v intor--verbosity intTo set log level verbosity from 0-9-ffilenameor–filename filename` To identify the filename containing the cluster config--force-cleanupTo force deletion of previously created bootstrap cluster-w stringor--w-config stringTo identify the kubeconfig file when needed to create a support bundle or upgrade a cluster
Other available options and arguments are listed with the command examples that follow.
eksctl anywhere generate
With eksctl anywhere generate, you can output sets of cluster resources to create a new cluster
or troubleshoot an existing cluster.
Here are some examples.
eksctl anywhere generate clusterconfig
Using eksctl anywhere generate clusterconfig you can generate a cluster configuration
for a specific provider (-p or --providerprovider_name). Here are examples:
Generate a configuration file to create an EKS Anywhere cluster for a vsphere provider:
export CLUSTER_NAME=vsphere01
eksctl anywhere generate clusterconfig ${CLUSTER_NAME} -p vsphere > ${CLUSTER_NAME}.yaml
Generate a configuration file to create an EKS Anywhere cluster for a Docker provider:
export CLUSTER_NAME=docker01
eksctl anywhere generate clusterconfig ${CLUSTER_NAME} -p docker > ${CLUSTER_NAME}.yaml
Once you have generated the yaml configuration file, edit that file to add configuration information before you use the file to create your cluster. See local and production cluster creation procedures for details.
eksctl anywhere generate support-bundle-config
If you would like to customize your support bundle, you can generate a support bundle configuration file (support-bundle-config),
edit that file to choose the data you want to gather,
then gather the selected data into a support bundle (support-bundle).
Generate a support bundle config file (then edit that file to select the log data you want to gather):
export CLUSTER_NAME=vsphere01
eksctl anywhere generate support-bundle-config > ${CLUSTER_NAME}_bundle_config.yaml
eksctl anywhere generate support-bundle
Once you have a bundle config file, generate a support bundle from an existing EKS Anywhere cluster. Additional options available for this command include:
--bundle-config stringTo identify the bundle config file to use to generate the support bundle--since stringTo collect pod logs in the latest duration like 5s, 2m, or 3h.--since-time stringTo collect pod logs after a specific datetime(RFC3339) like 2021-06-28T15:04:05Z
Here is an example:
export CLUSTER_NAME=vsphere01
eksctl anywhere generate support-bundle --bundle-config ${CLUSTER_NAME}_bundle_config.yaml \
-w ${PWD}/${CLUSTER_NAME}/${CLUSTER_NAME}-eks-a-cluster.kubeconfig \
--since 2h -f ${CLUSTER_NAME}/${CLUSTER_NAME}-eks-a-cluster.yaml
The example just shown:
- Uses
${CLUSTER_NAME}_bundle.yamlas the file to hold the results - Collects pod logs for the past two hours (2h)
- Identifies the bundle config file to use (
${CLUSTER_NAME}_bundle_config.yaml) - Identifies the
.kubeconfigfile to use for a workload cluster
To change the command to generate a support bundle that gathers pod logs starting from a specific date (September 8, 2021) and time (1:27 PM):
export CLUSTER_NAME=vsphere01
eksctl anywhere generate support-bundle --bundle-config ${CLUSTER_NAME}_bundle_config.yaml \
-w KUBECONFIG=${PWD}/${CLUSTER_NAME}/${CLUSTER_NAME}-eks-a-cluster.kubeconfig \
--since-time 2021-09-8T13:27:00Z 2h -f ${CLUSTER_NAME}_bundle.yaml
eksctl anywhere create cluster
Create an EKS Anywhere cluster from a cluster configuration file you generated (and modified) earlier.
This example sets verbosity to most verbose (-v 9):
export CLUSTER_NAME=vsphere01
eksctl anywhere create cluster -v 9 -f ${CLUSTER_NAME}.yaml
See local and production cluster creation procedures for details.
eksctl anywhere upgrade cluster
Upgrade an existing EKS Anywhere cluster. This example uses maximum verbosity and forces a cleanup of the previously created bootstrap cluster:
export CLUSTER_NAME=vsphere01
eksctl anywhere upgrade cluster -f ${CLUSTER_NAME}.yaml --force-cleanup -v9 \
-w KUBECONFIG=${PWD}/${CLUSTER_NAME}/${CLUSTER_NAME}-eks-a-cluster.kubeconfig
For more information on this and other ways to upgrade a cluster, see Upgrade cluster .
eksctl anywhere delete cluster
Delete an existing EKS Anywhere cluster. This example deletes all VMs and the forces the deletion of the previously created bootstrap cluster:
export CLUSTER_NAME=vsphere01
eksctl anywhere delete cluster -f ${CLUSTER_NAME}.yaml \
--force-cleanup \
-w KUBECONFIG=${PWD}/${CLUSTER_NAME}/${CLUSTER_NAME}-eks-a-cluster.kubeconfig
For more information on deleting a cluster, see Delete cluster .
eksctl anywhere version
View the version of eksctl anywhere:
eksctl anywhere version
v0.5.0
eksctl anywhere help
Use eksctl anywhere help or the -h option to see general options or options specific to a particular set of commands.
View general help information using help:
eksctl anywhere help
Use eksctl anywhere to build your own self-managing cluster on your hardware with the best of Amazon EKS
Usage:
eksctl anywhere [command]
Available Commands:
create Create resources
delete Delete resources
generate Generate resources
help Help about any command
upgrade Upgrade resources
version Get the eksctl version
Flags:
-h, --help help for eksctl
-v, --verbosity int Set the log level verbosity
Use "eksctl [command] --help" for more information about a command.
...
Display help options for generating a support bundle:
eksctl anywhere generate support-bundle -h
This command is used to create a support bundle to troubleshoot a cluster
Usage:
eksctl anywhere generate support-bundle -f my-cluster.yaml [flags]
Flags:
--bundle-config string Bundle Config file to use when generating support bundle
-f, --filename string Filename that contains EKS-A cluster configuration
-h, --help help for support-bundle
--since string Collect pod logs in the latest duration like 5s, 2m, or 3h.
--since-time string Collect pod logs after a specific datetime(RFC3339) like 2021-06-28T15:04:05Z
-w, --w-config string Kubeconfig file to use when creating support bundle for a workload cluster
Global Flags:
-v, --verbosity int Set the log level verbosity
Display options for creating a cluster:
eksctl anywhere create cluster -h
This command is used to create workload clusters
Usage:
eksctl anywhere create cluster [flags]
Flags:
-f, --filename string Filename that contains EKS-A cluster configuration
--force-cleanup Force deletion of previously created bootstrap cluster
-h, --help help for cluster
Global Flags:
-v, --verbosity int Set the log level verbosity
15.1 - anywhere
anywhere
Amazon EKS Anywhere
Synopsis
Use eksctl anywhere to build your own self-managing cluster on your hardware with the best of Amazon EKS
Options
-h, --help help for anywhere
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere apply - Apply resources
- anywhere check-images - Check images used by EKS Anywhere do exist in the target registry
- anywhere copy - Copy resources
- anywhere create - Create resources
- anywhere delete - Delete resources
- anywhere describe - Describe resources
- anywhere download - Download resources
- anywhere exp - experimental commands
- anywhere generate - Generate resources
- anywhere get - Get resources
- anywhere import - Import resources
- anywhere install - Install resources to the cluster
- anywhere list - List resources
- anywhere upgrade - Upgrade resources
- anywhere version - Get the eksctl anywhere version
15.2 - anywhere apply
anywhere apply
Apply resources
Synopsis
Use eksctl anywhere apply to apply resources
Options
-h, --help help for apply
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere - Amazon EKS Anywhere
- anywhere apply package(s) - Apply curated packages
15.3 - anywhere apply package(s)
anywhere apply package(s)
Apply curated packages
Synopsis
Apply Curated Packages Custom Resources to the cluster
anywhere apply package(s) [flags]
Options
-f, --filename string Filename that contains curated packages custom resources to apply
-h, --help help for package(s)
--kubeconfig string Path to an optional kubeconfig file to use.
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere apply - Apply resources
15.4 - anywhere check-images
anywhere check-images
Check images used by EKS Anywhere do exist in the target registry
Synopsis
This command is used to check images used by EKS-Anywhere for cluster provisioning do exist in the target registry
anywhere check-images [flags]
Options
-f, --filename string Filename that contains EKS-A cluster configuration
-h, --help help for check-images
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere - Amazon EKS Anywhere
15.5 - anywhere copy
anywhere copy
Copy resources
Synopsis
Copy EKS Anywhere resources and artifacts
Options
-h, --help help for copy
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere - Amazon EKS Anywhere
- anywhere copy packages - Copy curated package images and charts from a source to a destination
15.6 - anywhere copy packages
anywhere copy packages
Copy curated package images and charts from a source to a destination
Synopsis
Copy all the EKS Anywhere curated package images and helm charts from a source to a destination.
anywhere copy packages [flags]
Options
--aws-region string Region to copy images from
-b, --bundle string EKS-A bundle file to read artifact dependencies from
--dry-run Dry run copy to print images that would be copied
--dst-cert string TLS certificate for destination registry
-h, --help help for packages
--insecure Skip TLS verification while copying images and charts
--src-cert string TLS certificate for source registry
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere copy - Copy resources
15.7 - anywhere create
anywhere create
Create resources
Synopsis
Use eksctl anywhere create to create resources, such as clusters
Options
-h, --help help for create
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere - Amazon EKS Anywhere
- anywhere create cluster - Create workload cluster
- anywhere create package(s) - Create curated packages
15.8 - anywhere create cluster
anywhere create cluster
Create workload cluster
Synopsis
This command is used to create workload clusters
anywhere create cluster -f <cluster-config-file> [flags]
Options
--bundles-override string Override default Bundles manifest (not recommended)
-f, --filename string Filename that contains EKS-A cluster configuration
--force-cleanup Force deletion of previously created bootstrap cluster
-z, --hardware-csv string Path to a CSV file containing hardware data.
-h, --help help for cluster
--install-packages string Location of curated packages configuration files to install to the cluster
--kubeconfig string Management cluster kubeconfig file
--no-timeouts Disable timeout for all wait operations
--skip-ip-check Skip check for whether cluster control plane ip is in use
--tinkerbell-bootstrap-ip string Override the local tinkerbell IP in the bootstrap cluster
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere create - Create resources
15.9 - anywhere create package(s)
anywhere create package(s)
Create curated packages
Synopsis
Create Curated Packages Custom Resources to the cluster
anywhere create package(s) [flags]
Options
-f, --filename string Filename that contains curated packages custom resources to create
-h, --help help for package(s)
--kubeconfig string Path to an optional kubeconfig file to use.
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere create - Create resources
15.10 - anywhere delete
anywhere delete
Delete resources
Synopsis
Use eksctl anywhere delete to delete clusters
Options
-h, --help help for delete
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere - Amazon EKS Anywhere
- anywhere delete cluster - Workload cluster
- anywhere delete package(s) - Delete package(s)
15.11 - anywhere delete cluster
anywhere delete cluster
Workload cluster
Synopsis
This command is used to delete workload clusters created by eksctl anywhere
anywhere delete cluster (<cluster-name>|-f <config-file>) [flags]
Options
--bundles-override string Override default Bundles manifest (not recommended)
-f, --filename string Filename that contains EKS-A cluster configuration, required if <cluster-name> is not provided
--force-cleanup Force deletion of previously created bootstrap cluster
-h, --help help for cluster
--kubeconfig string kubeconfig file pointing to a management cluster
-w, --w-config string Kubeconfig file to use when deleting a workload cluster
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere delete - Delete resources
15.12 - anywhere delete package(s)
anywhere delete package(s)
Delete package(s)
Synopsis
This command is used to delete the curated packages custom resources installed in the cluster
anywhere delete package(s) [flags]
Options
--cluster string Cluster for package deletion.
-h, --help help for package(s)
--kubeconfig string Path to an optional kubeconfig file to use.
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere delete - Delete resources
15.13 - anywhere describe
anywhere describe
Describe resources
Synopsis
Use eksctl anywhere describe to show details of a specific resource or group of resources
Options
-h, --help help for describe
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere - Amazon EKS Anywhere
- anywhere describe package(s) - Describe curated packages in the cluster
15.14 - anywhere describe package(s)
anywhere describe package(s)
Describe curated packages in the cluster
anywhere describe package(s) [flags]
Options
--cluster string Cluster to describe packages.
-h, --help help for package(s)
--kubeconfig string Path to an optional kubeconfig file to use.
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere describe - Describe resources
15.15 - anywhere download
anywhere download
Download resources
Synopsis
Use eksctl anywhere download to download artifacts (manifests, bundles) used by EKS Anywhere
Options
-h, --help help for download
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere - Amazon EKS Anywhere
- anywhere download artifacts - Download EKS Anywhere artifacts/manifests to a tarball on disk
- anywhere download images - Download all eks-a images to disk
15.16 - anywhere download artifacts
anywhere download artifacts
Download EKS Anywhere artifacts/manifests to a tarball on disk
Synopsis
This command is used to download the S3 artifacts from an EKS Anywhere bundle manifest and package them into a tarball
anywhere download artifacts [flags]
Options
--bundles-override string Override default Bundles manifest (not recommended)
-d, --download-dir string Directory to download the artifacts to (default "eks-anywhere-downloads")
--dry-run Print the manifest URIs without downloading them
-f, --filename string [Deprecated] Filename that contains EKS-A cluster configuration
-h, --help help for artifacts
-r, --retain-dir Do not delete the download folder after creating a tarball
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere download - Download resources
15.17 - anywhere download images
anywhere download images
Download all eks-a images to disk
Synopsis
Creates a tarball containing all necessary images to create an eks-a cluster for any of the supported Kubernetes versions.
anywhere download images [flags]
Options
--bundles-override string Override default Bundles manifest (not recommended)
-h, --help help for images
--include-packages this flag no longer works, use copy packages instead (DEPRECATED: use copy packages command)
--insecure Flag to indicate skipping TLS verification while downloading helm charts
-o, --output string Output tarball containing all downloaded images
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere download - Download resources
15.18 - anywhere exp
anywhere exp
experimental commands
Synopsis
Use eksctl anywhere experimental commands
Options
-h, --help help for exp
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere - Amazon EKS Anywhere
- anywhere exp validate - Validate resource or action
- anywhere exp vsphere - Utility vsphere operations
15.19 - anywhere exp validate
anywhere exp validate
Validate resource or action
Synopsis
Use eksctl anywhere validate to validate a resource or action
Options
-h, --help help for validate
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere exp - experimental commands
- anywhere exp validate create - Validate create resources
15.20 - anywhere exp validate create
anywhere exp validate create
Validate create resources
Synopsis
Use eksctl anywhere validate create to validate the create action on resources, such as cluster
Options
-h, --help help for create
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere exp validate - Validate resource or action
- anywhere exp validate create cluster - Validate create cluster
15.21 - anywhere exp validate create cluster
anywhere exp validate create cluster
Validate create cluster
Synopsis
Use eksctl anywhere validate create cluster to validate the create cluster action
anywhere exp validate create cluster -f <cluster-config-file> [flags]
Options
-f, --filename string Filename that contains EKS-A cluster configuration
-z, --hardware-csv string Path to a CSV file containing hardware data.
-h, --help help for cluster
--tinkerbell-bootstrap-ip string Override the local tinkerbell IP in the bootstrap cluster
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere exp validate create - Validate create resources
15.22 - anywhere exp vsphere
anywhere exp vsphere
Utility vsphere operations
Synopsis
Use eksctl anywhere vsphere to perform utility operations on vsphere
Options
-h, --help help for vsphere
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere exp - experimental commands
- anywhere exp vsphere setup - Setup vSphere objects
15.23 - anywhere exp vsphere setup
anywhere exp vsphere setup
Setup vSphere objects
Synopsis
Use eksctl anywhere vsphere setup to configure vSphere objects
Options
-h, --help help for setup
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere exp vsphere - Utility vsphere operations
- anywhere exp vsphere setup user - Setup vSphere user
15.24 - anywhere exp vsphere setup user
anywhere exp vsphere setup user
Setup vSphere user
Synopsis
Use eksctl anywhere vsphere setup user to configure EKS Anywhere vSphere user
anywhere exp vsphere setup user -f <config-file> [flags]
Options
-f, --filename string Filename containing vsphere setup configuration
--force Force flag. When set, setup user will proceed even if the group and role objects already exist. Mutually exclusive with --password flag, as it expects the user to already exist. default: false
-h, --help help for user
-p, --password string Password for creating new user
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere exp vsphere setup - Setup vSphere objects
15.25 - anywhere generate
anywhere generate
Generate resources
Synopsis
Use eksctl anywhere generate to generate resources, such as clusterconfig yaml
Options
-h, --help help for generate
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere - Amazon EKS Anywhere
- anywhere generate clusterconfig - Generate cluster config
- anywhere generate hardware - Generate hardware files
- anywhere generate packages - Generate package(s) configuration
- anywhere generate support-bundle - Generate a support bundle
- anywhere generate support-bundle-config - Generate support bundle config
15.26 - anywhere generate clusterconfig
anywhere generate clusterconfig
Generate cluster config
Synopsis
This command is used to generate a cluster config yaml for the create cluster command
anywhere generate clusterconfig <cluster-name> (max 80 chars) [flags]
Options
-h, --help help for clusterconfig
-p, --provider string Provider to use (vsphere or tinkerbell or docker)
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere generate - Generate resources
15.27 - anywhere generate hardware
anywhere generate hardware
Generate hardware files
Synopsis
Generate Kubernetes hardware YAML manifests for each Hardware entry in the source.
anywhere generate hardware [flags]
Options
-z, --hardware-csv string Path to a CSV file containing hardware data.
-h, --help help for hardware
-o, --output string Path to output hardware YAML.
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere generate - Generate resources
15.28 - anywhere generate packages
anywhere generate packages
Generate package(s) configuration
Synopsis
Generates Kubernetes configuration files for curated packages
anywhere generate packages [flags] package
Options
--cluster string Name of cluster for package generation
-h, --help help for packages
--kube-version string Kubernetes Version of the cluster to be used. Format <major>.<minor>
--kubeconfig string Path to an optional kubeconfig file to use.
--registry string Used to specify an alternative registry for package generation
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere generate - Generate resources
15.29 - anywhere generate support-bundle
anywhere generate support-bundle
Generate a support bundle
Synopsis
This command is used to create a support bundle to troubleshoot a cluster
anywhere generate support-bundle -f my-cluster.yaml [flags]
Options
--bundle-config string Bundle Config file to use when generating support bundle
-f, --filename string Filename that contains EKS-A cluster configuration
-h, --help help for support-bundle
--since string Collect pod logs in the latest duration like 5s, 2m, or 3h.
--since-time string Collect pod logs after a specific datetime(RFC3339) like 2021-06-28T15:04:05Z
-w, --w-config string Kubeconfig file to use when creating support bundle for a workload cluster
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere generate - Generate resources
15.30 - anywhere generate support-bundle-config
anywhere generate support-bundle-config
Generate support bundle config
Synopsis
This command is used to generate a default support bundle config yaml
anywhere generate support-bundle-config [flags]
Options
-f, --filename string Filename that contains EKS-A cluster configuration
-h, --help help for support-bundle-config
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere generate - Generate resources
15.31 - anywhere get
anywhere get
Get resources
Synopsis
Use eksctl anywhere get to display one or many resources
Options
-h, --help help for get
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere - Amazon EKS Anywhere
- anywhere get package(s) - Get package(s)
- anywhere get packagebundle(s) - Get packagebundle(s)
- anywhere get packagebundlecontroller(s) - Get packagebundlecontroller(s)
15.32 - anywhere get package(s)
anywhere get package(s)
Get package(s)
Synopsis
This command is used to display the curated packages installed in the cluster
anywhere get package(s) [flags]
Options
--cluster string Cluster to get list of packages.
-h, --help help for package(s)
--kubeconfig string Path to an optional kubeconfig file.
-o, --output string Specifies the output format (valid option: json, yaml)
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere get - Get resources
15.33 - anywhere get packagebundle(s)
anywhere get packagebundle(s)
Get packagebundle(s)
Synopsis
This command is used to display the currently supported packagebundles
anywhere get packagebundle(s) [flags]
Options
-h, --help help for packagebundle(s)
--kubeconfig string Path to an optional kubeconfig file.
-o, --output string Specifies the output format (valid option: json, yaml)
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere get - Get resources
15.34 - anywhere get packagebundlecontroller(s)
anywhere get packagebundlecontroller(s)
Get packagebundlecontroller(s)
Synopsis
This command is used to display the current packagebundlecontrollers
anywhere get packagebundlecontroller(s) [flags]
Options
-h, --help help for packagebundlecontroller(s)
--kubeconfig string Path to an optional kubeconfig file.
-o, --output string Specifies the output format (valid option: json, yaml)
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere get - Get resources
15.35 - anywhere import
anywhere import
Import resources
Synopsis
Use eksctl anywhere import to import resources, such as images and helm charts
Options
-h, --help help for import
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere - Amazon EKS Anywhere
- anywhere import images - Import images and charts to a registry from a tarball
15.36 - anywhere import images
anywhere import images
Import images and charts to a registry from a tarball
Synopsis
Import all the images and helm charts necessary for EKS Anywhere clusters into a registry. Use this command in conjunction with download images, passing it output tarball as input to this command.
anywhere import images [flags]
Options
-b, --bundles string Bundles file to read artifact dependencies from
-h, --help help for images
--include-packages Flag to indicate inclusion of curated packages in imported images (DEPRECATED: use copy packages command)
-i, --input string Input tarball containing all images and charts to import
--insecure Flag to indicate skipping TLS verification while pushing helm charts
-r, --registry string Registry where to import images and charts
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere import - Import resources
15.37 - anywhere install
anywhere install
Install resources to the cluster
Synopsis
Use eksctl anywhere install to install resources into a cluster
Options
-h, --help help for install
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere - Amazon EKS Anywhere
- anywhere install package - Install package
- anywhere install packagecontroller - Install packagecontroller on the cluster
15.38 - anywhere install package
anywhere install package
Install package
Synopsis
This command is used to Install a curated package. Use list to discover curated packages
anywhere install package [flags] package
Options
--cluster string Target cluster for installation.
-h, --help help for package
--kube-version string Kubernetes Version of the cluster to be used. Format <major>.<minor>
--kubeconfig string Path to an optional kubeconfig file to use.
-n, --package-name string Custom name of the curated package to install
--registry string Used to specify an alternative registry for discovery
--set stringArray Provide custom configurations for curated packages. Format key:value
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere install - Install resources to the cluster
15.39 - anywhere install packagecontroller
anywhere install packagecontroller
Install packagecontroller on the cluster
Synopsis
This command is used to Install the packagecontroller on to an existing cluster
anywhere install packagecontroller [flags]
Options
-f, --filename string Filename that contains EKS-A cluster configuration
-h, --help help for packagecontroller
--kubeConfig string Management cluster kubeconfig file
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere install - Install resources to the cluster
15.40 - anywhere list
anywhere list
List resources
Synopsis
Use eksctl anywhere list to list images and artifacts used by EKS Anywhere
Options
-h, --help help for list
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere - Amazon EKS Anywhere
- anywhere list images - Generate a list of images used by EKS Anywhere
- anywhere list ovas - List the OVAs that are supported by current version of EKS Anywhere
- anywhere list packages - Lists curated packages available to install
15.41 - anywhere list images
anywhere list images
Generate a list of images used by EKS Anywhere
Synopsis
This command is used to generate a list of images used by EKS-Anywhere for cluster provisioning
anywhere list images [flags]
Options
--bundles-override string Override default Bundles manifest (not recommended)
-f, --filename string Filename that contains EKS-A cluster configuration
-h, --help help for images
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere list - List resources
15.42 - anywhere list ovas
anywhere list ovas
List the OVAs that are supported by current version of EKS Anywhere
Synopsis
This command is used to list the vSphere OVAs from the EKS Anywhere bundle manifest for the current version of the EKS Anywhere CLI
anywhere list ovas [flags]
Options
--bundles-override string Override default Bundles manifest (not recommended)
-f, --filename string Filename that contains EKS-A cluster configuration
-h, --help help for ovas
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere list - List resources
15.43 - anywhere list packages
anywhere list packages
Lists curated packages available to install
anywhere list packages [flags]
Options
--cluster string Name of cluster for package list.
-h, --help help for packages
--kube-version string Kubernetes version <major>.<minor> of the packages to list, for example: "1.23".
--kubeconfig string Path to a kubeconfig file to use when source is a cluster.
--registry string Specifies an alternative registry for packages discovery.
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere list - List resources
15.44 - anywhere upgrade
anywhere upgrade
Upgrade resources
Synopsis
Use eksctl anywhere upgrade to upgrade resources, such as clusters
Options
-h, --help help for upgrade
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere - Amazon EKS Anywhere
- anywhere upgrade cluster - Upgrade workload cluster
- anywhere upgrade packages - Upgrade all curated packages to the latest version
- anywhere upgrade plan - Provides information for a resource upgrade
15.45 - anywhere upgrade cluster
anywhere upgrade cluster
Upgrade workload cluster
Synopsis
This command is used to upgrade workload clusters
anywhere upgrade cluster [flags]
Options
--bundles-override string Override default Bundles manifest (not recommended)
-f, --filename string Filename that contains EKS-A cluster configuration
--force-cleanup Force deletion of previously created bootstrap cluster
-z, --hardware-csv string Path to a CSV file containing hardware data.
-h, --help help for cluster
--kubeconfig string Management cluster kubeconfig file
--no-timeouts Disable timeout for all wait operations
-w, --w-config string Kubeconfig file to use when upgrading a workload cluster
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere upgrade - Upgrade resources
15.46 - anywhere upgrade packages
anywhere upgrade packages
Upgrade all curated packages to the latest version
anywhere upgrade packages [flags]
Options
--bundle-version string Bundle version to use
--cluster string Cluster to upgrade.
-h, --help help for packages
--kubeconfig string Path to an optional kubeconfig file to use.
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere upgrade - Upgrade resources
15.47 - anywhere upgrade plan
anywhere upgrade plan
Provides information for a resource upgrade
Synopsis
Use eksctl anywhere upgrade plan to get information for a resource upgrade
Options
-h, --help help for plan
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere upgrade - Upgrade resources
- anywhere upgrade plan cluster - Provides new release versions for the next cluster upgrade
15.48 - anywhere upgrade plan cluster
anywhere upgrade plan cluster
Provides new release versions for the next cluster upgrade
Synopsis
Provides a list of target versions for upgrading the core components in the workload cluster
anywhere upgrade plan cluster [flags]
Options
--bundles-override string Override default Bundles manifest (not recommended)
-f, --filename string Filename that contains EKS-A cluster configuration
-h, --help help for cluster
--kubeconfig string Management cluster kubeconfig file
-o, --output string Output format: text|json (default "text")
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere upgrade plan - Provides information for a resource upgrade
15.49 - anywhere version
anywhere version
Get the eksctl anywhere version
Synopsis
This command prints the version of eksctl anywhere
anywhere version [flags]
Options
-h, --help help for version
Options inherited from parent commands
-v, --verbosity int Set the log level verbosity
SEE ALSO
- anywhere - Amazon EKS Anywhere